
5、redis叢集與hash一致性
為什麼叢集?
通常,為了提高網站響應速度,總是把熱點資料儲存在記憶體中而不是直接從後端資料庫中讀取。Redis是一個很好的Cache工具。大型網站應用,熱點資料量往往巨大,幾十G上百G是很正常的事兒,在這種情況下,如何正確架構Redis呢?
首先,無論我們是使用自己的物理主機,還是使用雲服務主機,記憶體資源往往是有限制的,scale up不是一個好辦法,我們需要scale out橫向可伸縮擴充套件,這需要由多臺主機協同提供服務,即分散式多個Redis例項協同執行。
其次,目前硬體資源成本降低,多核CPU,幾十G記憶體的主機很普遍,對於主程序是單執行緒工作的Redis,只執行一個例項就顯得有些浪費。同時,管理一個巨大記憶體不如管理相對較小的記憶體高效。因此,實際使用中,通常一臺機器上同時跑多個Redis例項。
方案
1.Redis官方叢集方案 Redis Cluster
Redis Cluster是一種伺服器Sharding技術,3.0版本開始正式提供。
Redis Cluster中,Sharding採用slot(槽)的概念,一共分成16384個槽,這有點兒類pre sharding思路。對於每個進入Redis的鍵值對,根據key進行雜湊,分配到這16384個slot中的某一箇中。使用的hash演算法也比較簡單,就是CRC16後16384取模。
Redis叢集中的每個node(節點)負責分攤這16384個slot中的一部分,也就是說,每個slot都對應一個node負責處理。當動態新增或減少node節點時,需要將16384個槽做個再分配,槽中的鍵值也要遷移。當然,這一過程,在目前實現中,還處於半自動狀態,需要人工介入。
Redis叢集,要保證16384個槽對應的node都正常工作,如果某個node發生故障,那它負責的slots也就失效,整個叢集將不能工作。
為了增加叢集的可訪問性,官方推薦的方案是將node配置成主從結構,即一個master主節點,掛n個slave從節點。這時,如果主節點失效,Redis Cluster會根據選舉演算法從slave節點中選擇一個上升為主節點,整個叢集繼續對外提供服務。這非常類似前篇文章提到的Redis Sharding場景下伺服器節點通過Sentinel監控架構成主從結構,只是Redis Cluster本身提供了故障轉移容錯的能力。
Redis Cluster的新節點識別能力、故障判斷及故障轉移能力是通過叢集中的每個node都在和其它nodes進行通訊,這被稱為叢集匯流排(cluster bus)。它們使用特殊的埠號,即對外服務埠號加10000。例如如果某個node的埠號是6379,那麼它與其它nodes通訊的埠號是16379。nodes之間的通訊採用特殊的二進位制協議。
對客戶端來說,整個cluster被看做是一個整體,客戶端可以連線任意一個node進行操作,就像操作單一Redis例項一樣,當客戶端操作的key沒有分配到該node上時,Redis會返回轉向指令,指向正確的node,這有點兒像瀏覽器頁面的302 redirect跳轉。
Redis Cluster是Redis 3.0以後才正式推出,時間較晚,目前能證明在大規模生產環境下成功的案例還不是很多,需要時間檢驗。
2.Redis Sharding叢集
Redis 3正式推出了官方叢集技術,解決了多Redis例項協同服務問題。Redis Cluster可以說是服務端Sharding分片技術的體現,即將鍵值按照一定演算法合理分配到各個例項分片上,同時各個例項節點協調溝通,共同對外承擔一致服務。
多Redis例項服務,比單Redis例項要複雜的多,這涉及到定位、協同、容錯、擴容等技術難題。這裡,我們介紹一種輕量級的客戶端Redis Sharding技術。
Redis Sharding可以說是Redis Cluster出來之前,業界普遍使用的多Redis例項叢集方法。其主要思想是採用雜湊演算法將Redis資料的key進行雜湊,通過hash函式,特定的key會對映到特定的Redis節點上。這樣,客戶端就知道該向哪個Redis節點操作資料。
慶幸的是,java redis客戶端驅動jedis,已支援Redis Sharding功能,即ShardedJedis以及結合快取池的ShardedJedisPool。
Jedis的Redis Sharding實現具有如下特點:
1.採用一致性雜湊演算法(consistent hashing),將key和節點name同時hashing,然後進行對映匹配,採用的演算法是MURMUR_HASH。採用一致性雜湊而不是採用簡單類似雜湊求模對映的主要原因是當增加或減少節點時,不會產生由於重新匹配造成的rehashing。一致性雜湊隻影響相鄰節點key分配,影響量小。
2.為了避免一致性雜湊隻影響相鄰節點造成節點分配壓力,ShardedJedis會對每個Redis節點根據名字(沒有,Jedis會賦予預設名字)會虛擬化出160個虛擬節點進行雜湊。根據權重weight,也可虛擬化出160倍數的虛擬節點。用虛擬節點做對映匹配,可以在增加或減少Redis節點時,key在各Redis節點移動再分配更均勻,而不是隻有相鄰節點受影響。
3.ShardedJedis支援keyTagPattern模式,即抽取key的一部分keyTag做sharding,這樣通過合理命名key,可以將一組相關聯的key放入同一個Redis節點,這在避免跨節點訪問相關資料時很重要。
Redis Sharding採用客戶端Sharding方式,服務端Redis還是一個個相對獨立的Redis例項節點,沒有做任何變動。同時,我們也不需要增加額外的中間處理元件,這是一種非常輕量、靈活的Redis多例項叢集方法。
當然,Redis Sharding這種輕量靈活方式必然在叢集其它能力方面做出妥協。比如擴容,當想要增加Redis節點時,儘管採用一致性雜湊,畢竟還是會有key匹配不到而丟失,這時需要鍵值遷移。
作為輕量級客戶端sharding,處理Redis鍵值遷移是不現實的,這就要求應用層面允許Redis中資料丟失或從後端資料庫重新載入資料。但有些時候,擊穿快取層,直接訪問資料庫層,會對系統訪問造成很大壓力。有沒有其它手段改善這種情況?
Redis作者給出了一個比較討巧的辦法–presharding,即預先根據系統規模儘量部署好多個Redis例項,這些例項佔用系統資源很小,一臺物理機可部署多個,讓他們都參與sharding,當需要擴容時,選中一個例項作為主節點,新加入的Redis節點作為從節點進行資料複製。資料同步後,修改sharding配置,讓指向原例項的Shard指向新機器上擴容後的Redis節點,同時調整新Redis節點為主節點,原例項可不再使用。
presharding是預先分配好足夠的分片,擴容時只是將屬於某一分片的原Redis例項替換成新的容量更大的Redis例項。參與sharding的分片沒有改變,所以也就不存在key值從一個區轉移到另一個分片區的現象,只是將屬於同分片區的鍵值從原Redis例項同步到新Redis例項。
並不是只有增刪Redis節點引起鍵值丟失問題,更大的障礙來自Redis節點突然宕機。在《Redis持久化》一文中已提到,為不影響Redis效能,儘量不開啟AOF和RDB檔案儲存功能,可架構Redis主備模式,主Redis宕機,資料不會丟失,備Redis留有備份。
這樣,我們的架構模式變成一個Redis節點切片包含一個主Redis和一個備Redis。在主Redis宕機時,備Redis接管過來,上升為主Redis,繼續提供服務。主備共同組成一個Redis節點,通過自動故障轉移,保證了節點的高可用性。則Sharding架構演變成:
Redis Sentinel提供了主備模式下Redis監控、故障轉移功能達到系統的高可用性。
高訪問量下,即使採用Sharding分片,一個單獨節點還是承擔了很大的訪問壓力,這時我們還需要進一步分解。通常情況下,應用訪問Redis讀操作量和寫操作量差異很大,讀常常是寫的數倍,這時我們可以將讀寫分離,而且讀提供更多的例項數。
可以利用主從模式實現讀寫分離,主負責寫,從負責只讀,同時一主掛多個從。在Sentinel監控下,還可以保障節點故障的自動監測。
3.利用代理中介軟體實現大規模Redis叢集
上面分別介紹了多Redis伺服器叢集的兩種方式,它們是基於客戶端sharding的Redis Sharding和基於服務端sharding的Redis Cluster。
客戶端sharding技術其優勢在於服務端的Redis例項彼此獨立,相互無關聯,每個Redis例項像單伺服器一樣執行,非常容易線性擴充套件,系統的靈活性很強。其不足之處在於:
- 由於sharding處理放到客戶端,規模進步擴大時給運維帶來挑戰。
- 服務端Redis例項群拓撲結構有變化時,每個客戶端都需要更新調整。
- 連線不能共享,當應用規模增大時,資源浪費制約優化。
服務端sharding的Redis Cluster其優勢在於服務端Redis叢集拓撲結構變化時,客戶端不需要感知,客戶端像使用單Redis伺服器一樣使用Redis叢集,運維管理也比較方便。
不過Redis Cluster正式版推出時間不長,系統穩定性、效能等都需要時間檢驗,尤其在大規模使用場合。
能不能結合二者優勢?即能使服務端各例項彼此獨立,支援線性可伸縮,同時sharding又能集中處理,方便統一管理?本篇介紹的Redis代理中介軟體twemproxy就是這樣一種利用中介軟體做sharding的技術。
twemproxy處於客戶端和伺服器的中間,將客戶端發來的請求,進行一定的處理後(如sharding),再轉發給後端真正的Redis伺服器。也就是說,客戶端不直接訪問Redis伺服器,而是通過twemproxy代理中介軟體間接訪問。
參照Redis Sharding架構,增加代理中介軟體的Redis叢集架構如下:
twemproxy中介軟體的內部處理是無狀態的,它本身可以很輕鬆地叢集,這樣可避免單點壓力或故障。
twemproxy後端不僅支援redis,同時也支援memcached,這是twitter系統具體環境造成的。
由於使用了中介軟體,twemproxy可以通過共享與後端系統的連線,降低客戶端直接連線後端伺服器的連線數量。同時,它也提供sharding功能,支援後端伺服器叢集水平擴充套件。統一運維管理也帶來了方便。
當然,也是由於使用了中介軟體代理,相比客戶端直連伺服器方式,效能上會有所損耗,實測結果大約降低了20%左右。
一致性雜湊
一致性雜湊演算法是分散式系統中常用的演算法。比如,一個分散式的儲存系統,要將資料儲存到具體的節點上, 如果採用普通的hash方法,將資料對映到具體的節點上,如mod(key,d),key是資料的key,d是機器節點數, 如果有一個機器加入或退出這個叢集,則所有的資料對映都無效了。
一致性雜湊演算法解決了普通餘數Hash演算法伸縮性差的問題,可以保證在上線、下線伺服器的情況下儘量有多的請求命中原來路由到的伺服器。
環形Hash空間按照常用的hash演算法來將對應的key雜湊到一個具有2^32次方個桶的空間中,即0~(2^32)-1的數字空間中。
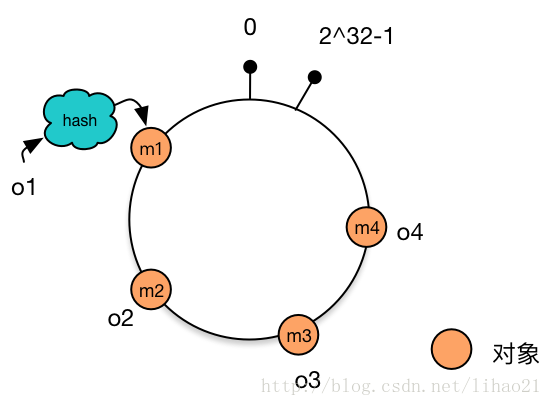
現在我們可以將這些數字頭尾相連,想象成一個閉合的環形。
把資料通過一定的hash演算法處理後對映到環上
現在我們將object1、object2、object3、object4四個物件通過特定的Hash函式計算出對應的key值,然後雜湊到Hash環上。如下圖: Hash(object1) = key1; Hash(object2) = key2; Hash(object3) = key3; Hash(object4) = key4;
將機器通過hash演算法對映到環上
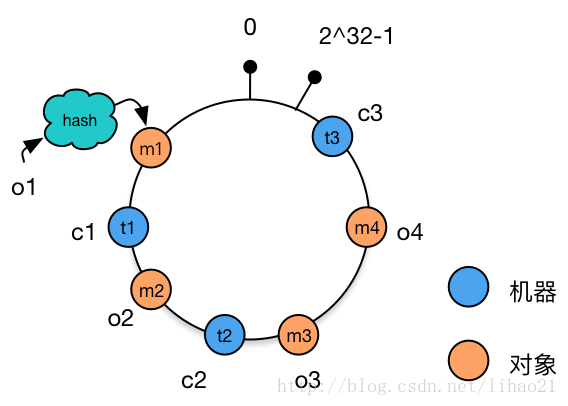
在採用一致性雜湊演算法的分散式叢集中將新的機器加入,其原理是通過使用與物件儲存一樣的Hash演算法將機器也對映到環中。
假設現在有NODE1,NODE2,NODE3三臺機器,通過Hash演算法得到對應的KEY值,對映到環中,其示意圖如下: Hash(NODE1) = KEY1; Hash(NODE2) = KEY2; Hash(NODE3) = KEY3;
可以看出物件與機器處於同一雜湊空間中,這樣按順時針轉動object1儲存到了NODE1中,object3儲存到了NODE2中,object2、object4儲存到了NODE3中;
在這樣的部署環境中,hash環是不會變更的,因此,通過算出物件的hash值就能快速的定位到對應的機器中,這樣就能找到物件真正的儲存位置,但是還是有可能發生節點退出而不能命中的情況。
節點(機器)的刪除以上面的分佈為例,如果NODE2出現故障被刪除了,那麼按照順時針遷移的方法,object3將會被遷移到NODE3中,這樣僅僅是object3的對映位置發生了變化,其它的物件沒有任何的改動。
節點(機器)的新增 如果往叢集中新增一個新的節點NODE4,通過對應的雜湊演算法得到KEY4,並對映到環中
通過按順時針遷移的規則,那麼object2被遷移到了NODE4中,其它物件還保持著原有的儲存位置。 通過對節點的新增和刪除的分析,一致性雜湊演算法在保持了單調性的同時,還是資料的遷移達到了最小,這樣的演算法對分散式叢集來說是非常合適的,避免了大量資料遷移,減小了伺服器的的壓力。
平衡性–虛擬節點
進行刪除節點後,資料向後面一個節點滑移,造成後面節點的單點壓力,如上面只部署了NODE1和NODE3的情況(NODE2被刪除的圖),object1儲存到了NODE1中,而object2、object3、object4都儲存到了NODE3中,這樣就照成了非常不平衡的狀態。在一致性雜湊演算法中,為了儘可能的滿足平衡性,其引入了虛擬節點。
以上面只部署了NODE1和NODE3的情況(NODE2被刪除的圖)為例,之前的物件在機器上的分佈很不均衡,現在我們以2個副本(複製個數)為例,這樣整個hash環中就存在了4個虛擬節點,最後物件對映的關係圖如下:
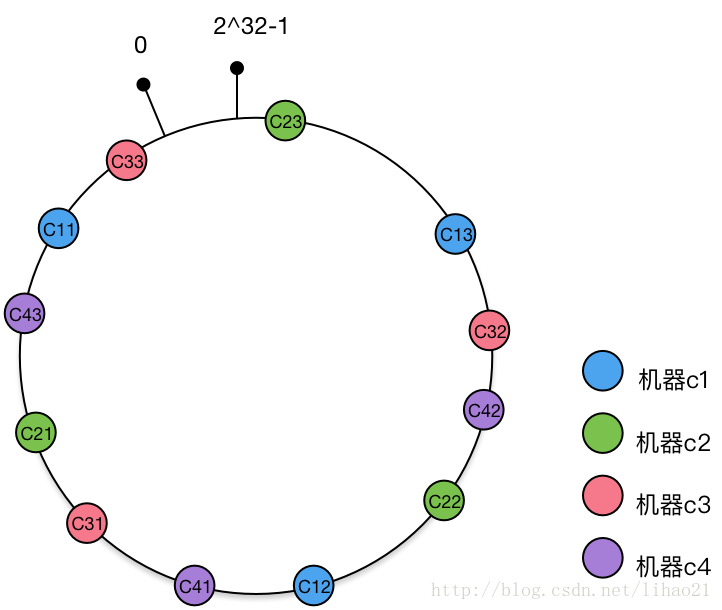
引入“虛擬節點”後,計算“虛擬節”點NODE1-1和NODE1-2的hash值: Hash(“192.168.1.100#1”); // NODE1-1 Hash(“192.168.1.100#2”); // NODE1-2
然後將新的[NODE1-1,NODE1-2,NODE2-1,NODE2-2 …]按照隨機排序即可。
redis叢集配置了Sentinel 模式,就不會出現資料遷移的情況。