
Redis Cluster學習整理
阿新 • • 發佈:2018-12-25
目錄
redis介紹
主從
叢集
安裝部署
原理
總結
檢視原文
中介軟體交流群:461333361
redis介紹
redis是一個基於記憶體的K-V儲存資料庫。支援儲存的型別有string,list,set,zset(sorted set),hash等。這些資料型別都支援push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。redis支援各種不同方式的排序。保證效率的情況下,資料快取在記憶體中。同時redis提供了持久化策略,不同的策略觸發同步到磁碟或者把修改操作寫入追加的記錄檔案,在此基礎上實現了master-slave。
它是一個高效能的儲存系統,能支援超過 100K+ 每秒的讀寫頻率。同時還支援訊息的釋出/訂閱,從而讓你在構建高效能訊息佇列系統時多了另一種選擇。
Redis支援主從同步。資料可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹複製。存檔可以有意無意的對資料進行寫操作。由於完全實現了釋出/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可擴充套件性和資料冗餘很有幫助。
主從 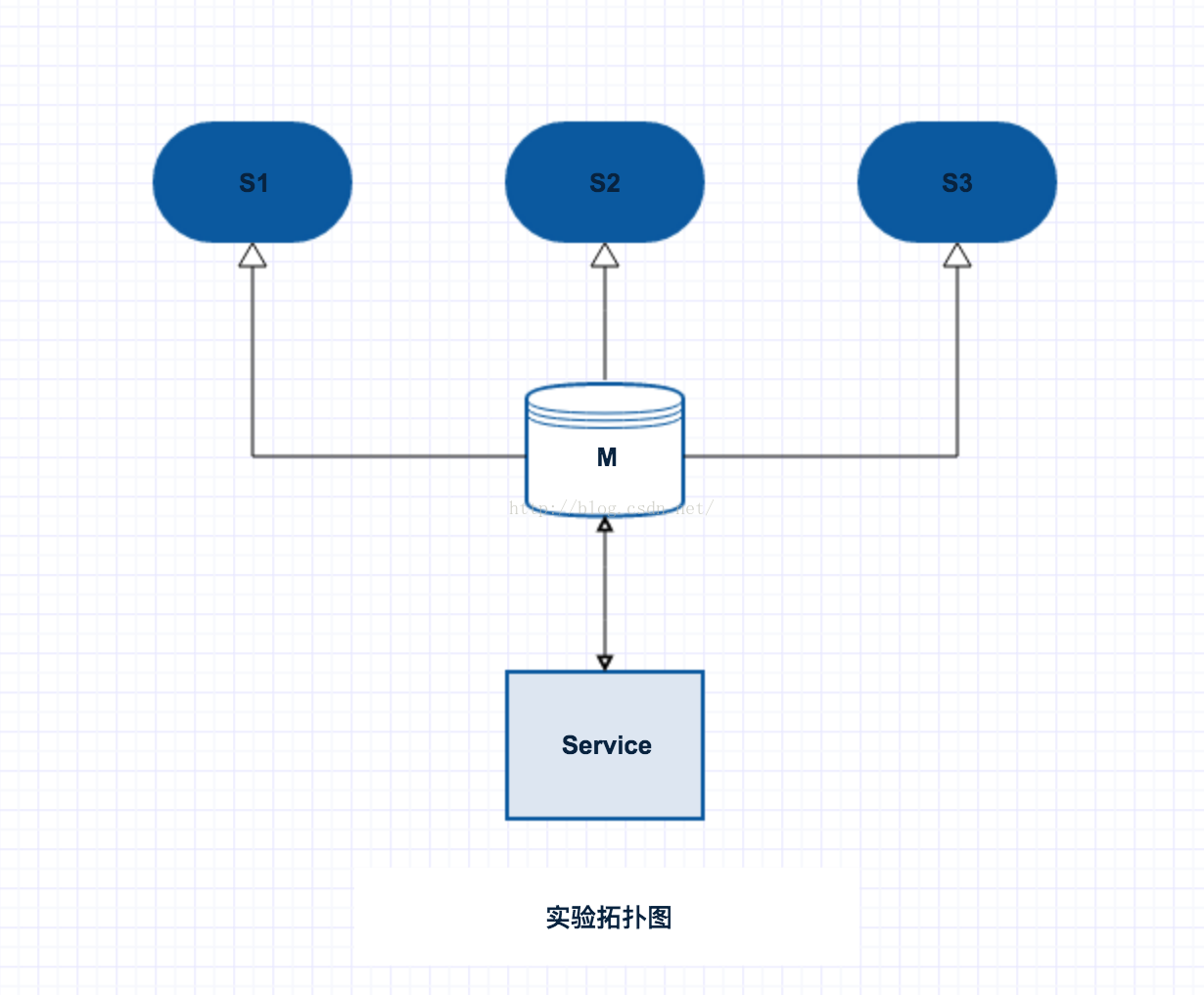
主從模式採用一主三從,主從都配置auth認證,讀寫分離。 主要實驗的動作: 1)多個app 同時寫,測定寫速率; 2)多個app 同時寫,同時有讀的程序,測定讀寫速率; 3)master主機宕機,app依然進行讀寫。 2.cluster拓撲圖如下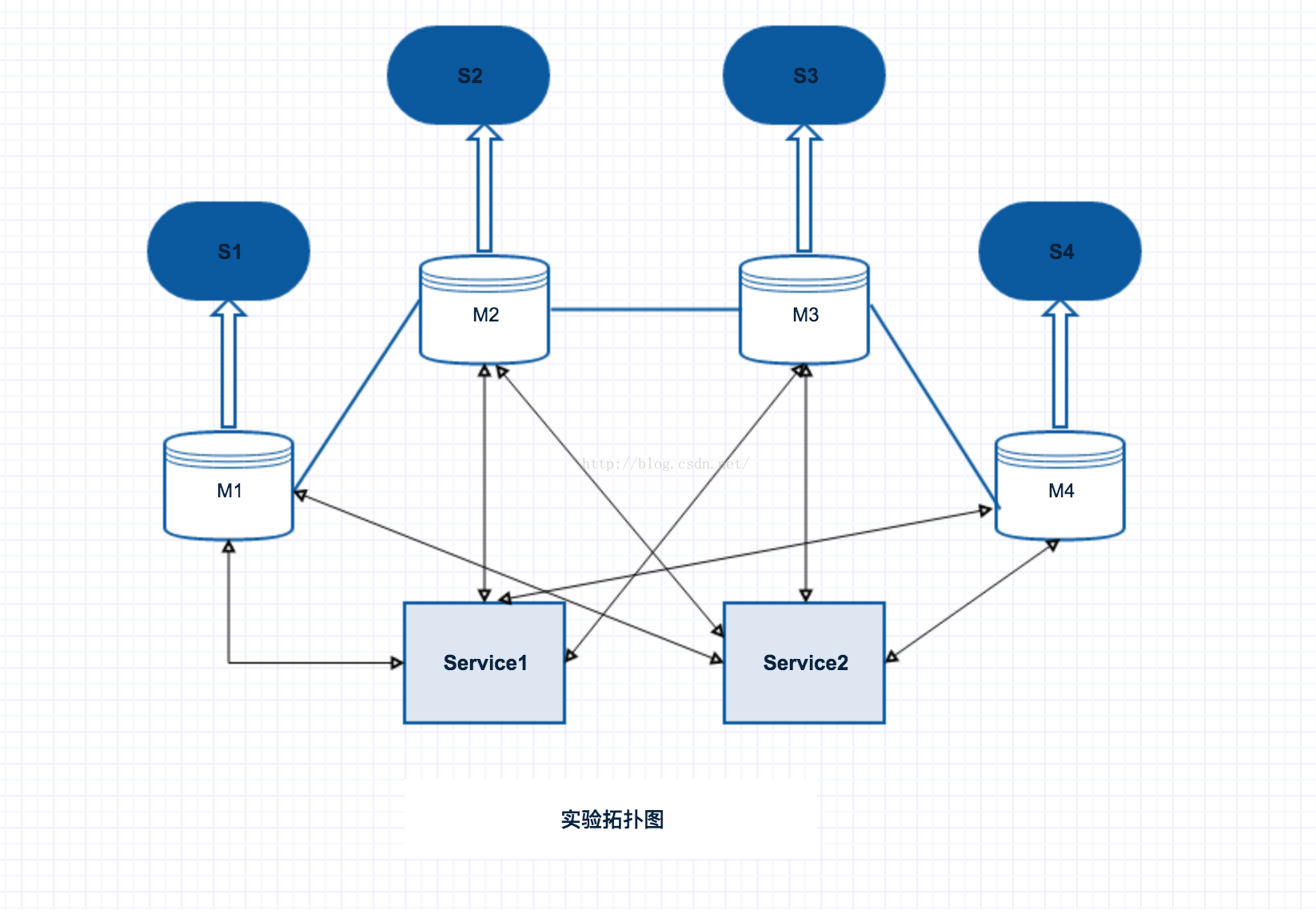
叢集模式採用四主四從,也是採用讀寫分離。 主要實驗的動作: 1)有一個master宕機,觀察日誌,新的slave成為master; 2)master宕機後,重新啟動,master成為slave; 3)叢集全部宕機,redis主機重啟,資料未丟失。 原理 1.一致性 filesnapshot:預設redis是會以快照的形式將資料持久化到磁碟,在配置檔案中的格式是:save N M表示在N秒之內,redis至少發生M次修改則redis抓快照到磁碟。 工作原理:當redis需要做持久化時,redis會fork一個子程序;子程序將資料寫到磁碟上一個臨時RDB檔案中;當子程序完成寫臨時檔案後, 將原來的RDB替換掉,這樣的好處就是可以copy-on-write。 Append-only:filesnapshotting方法在redis異常死掉時, 最近的資料會丟失(丟失資料的多少視你save策略的配置),所以這是它最大的缺點,當業務量很大時,丟失的資料是很多的。Append-only方法可 以做到全部資料不丟失,但redis的效能就要差些。AOF就可以做到全程持久化,只需要在配置檔案中開啟(預設是no),appendonly yes開啟AOF之後,redis每執行一個修改資料的命令,都會把它新增到aof檔案中,當redis重啟時,將會讀取AOF檔案進行“重放”以恢復到 redis關閉前的最後時刻。 AOF檔案重新整理的方式,有三種,參考配置引數appendfsync :appendfsync always每提交一個修改命令都呼叫fsync重新整理到AOF檔案,非常非常慢,但也非常安全; appendfsync everysec每秒鐘都呼叫fsync重新整理到AOF檔案,很快,但可能會丟失一秒以內的資料;appendfsync no依靠OS進行重新整理, redis不主動重新整理AOF,這樣最快,但安全性就差。預設並推薦每秒重新整理,這樣在速度和安全上都做到了兼顧。 Slave同樣可以接受其它Slaves的連線和同步請求,這樣可以有效的分載Master的同步壓力。因此我們可以將Redis的Replication架構視為圖結構。 Master Server是以非阻塞的方式為Slaves提供服務。所以在Master-Slave同步期間,客戶端仍然可以提交查詢或修改請求。 Slave Server同樣是以非阻塞的方式完成資料同步。在同步期間,如果有客戶端提交查詢請求,Redis則返回同步之前的資料。 為了分載Master的讀操作壓力,Slave伺服器可以為客戶端提供只讀操作的服務,寫服務仍然必須由Master來完成。即便如此,系統的伸縮性還是得到了很大的提高。 Master可以將資料儲存操作交給Slaves完成,從而避免了在Master中要有獨立的程序來完成此操作。 Redis在master是非阻塞模式,也就是說在slave執行資料同步的時候,master是可以接受客戶端的請求的,並不影響同步資料的一致性,然而在slave端是阻塞模式的,slave在同步master資料時,並不能夠響應客戶端的查詢。 2.Replication的工作原理 (1)Slave伺服器連線到Master伺服器. (2)Slave伺服器傳送SYCN命令. (3)Master伺服器備份資料庫到.rdb檔案. (4)Master伺服器把.rdb檔案傳輸給Slave伺服器. (5)Slave伺服器把.rdb檔案資料匯入到資料庫中。 在Slave啟動並連線到Master之後,它將主動傳送一個SYNC命令。此後Master將啟動後臺存檔程序,同時收集所有接收到的用於修改資料集 的命令,在後臺程序執行完畢後,Master將傳送整個資料庫檔案到Slave,以完成一次完全同步。而Slave伺服器在接收到資料庫檔案資料之後將其 存檔並載入到記憶體中。此後,Master繼續將所有已經收集到的修改命令,和新的修改命令依次傳送給Slaves,Slave將在本次執行這些資料修改命 令,從而達到最終的資料同步。 如果Master和Slave之間的連結出現斷連現象,Slave可以自動重連Master,但是在連線成功之後,一次完全同步將被自動執行。 3.一致性雜湊 叢集要實現的目的是要將不同的 key 分散放置到不同的 redis 節點,這裡我們需要一個規則或者演算法,通常的做法是獲取 key 的雜湊值,然後根據節點數來求模,但這種做法有其明顯的弊端,當我們需要增加或減少一個節點時,會造成大量的 key 無法命中,這種比例是相當高的,所以就有人提出了一致性雜湊的概念。 一致性雜湊有四個重要特徵: 均衡性:也有人把它定義為平衡性,是指雜湊的結果能夠儘可能分佈到所有的節點中去,這樣可以有效的利用每個節點上的資源。 單調性:對於單調性有很多翻譯讓我非常的不解,而我想要的是當節點數量變化時雜湊的結果應儘可能的保護已分配的內容不會被重新分派到新的節點。 分散性和負載:這兩個其實是差不多的意思,就是要求一致性雜湊演算法對 key 雜湊應儘可能的避免重複。 Redis 叢集中內建了 16384 個雜湊槽,當需要在 Redis 叢集中放置一個 key-value 時,redis 先對 key 使用 crc16 演算法算出一個結果,然後把結果對 16384 求餘數,這樣每個 key 都會對應一個編號在 0-16383 之間的雜湊槽,redis 會根據節點數量大致均等的將雜湊槽對映到不同的節點。 使用雜湊槽的好處就在於可以方便的新增或移除節點。 當需要增加節點時,只需要把其他節點的某些雜湊槽挪到新節點就可以了; 當需要移除節點時,只需要把移除節點上的雜湊槽挪到其他節點就行了; 當設定了主從關係後,slave 在第一次連線或者重新連線 master 時,slave 都會發送一條同步指令給 master ; master 接到指令後,開始啟動後臺儲存程序儲存資料,接著收集所有的資料修改指令。後臺儲存完了,master 就把這份資料傳送給 slave,slave 先把資料儲存到磁碟,然後把它載入到記憶體中,master 接著就把收集的資料修改指令一行一行的發給 slave,slave 接收到之後重新執行該指令,這樣就實現了資料同步。 slave 在與 master 失去聯絡後,自動的重新連線。如果 master 收到了多個 slave 的同步請求,它會執行單個後臺儲存來為所有的 slave 服務。 4.節點失效檢測 以下是節點失效檢查的實現方法: 1)當一個節點向另一個節點發送 PING 命令,但是目標節點未能在給定的時限內返回 PING 命令的回覆時,那麼傳送命令的節點會將目標節點標記為PFAIL (possible failure,可能已失效)。 2)等待 PING 命令回覆的時限稱為“節點超時時限(node timeout)”,是一個節點選項(node-wise setting)。 3)每次當節點對其他節點發送 PING 命令的時候,它都會隨機地廣播三個它所知道的節點的資訊,這些資訊裡面的其中一項就是說明節點是否已經被標記為 PFAIL 或者 FAIL 。 4)當節點接收到其他節點發來的資訊時,它會記下那些被其他節點標記為失效的節點。這稱為失效報告(failure report)。 5)如果節點已經將某個節點標記為 PFAIL ,並且根據節點所收到的失效報告顯式,叢集中的大部分其他主節點也認為那個節點進入了失效狀態,那麼節點會將那個失效節點的狀態標記為 FAIL 。 6)一旦某個節點被標記為 FAIL ,關於這個節點已失效的資訊就會被廣播到整個叢集,所有接收到這條資訊的節點都會將失效節點標記為 FAIL 。 簡單來說,一個節點要將另一個節點標記為失效,必須先詢問其他節點的意見,並且得到大部分主節點的同意才行。因為過期的失效報告會被移除,所以主節點要將某個節點標記為 FAIL 的話,必須以最近接收到的失效報告作為根據。 在以下兩種情況中,節點的 FAIL 狀態會被移除: 1)如果被標記為 FAIL 的是從節點,那麼當這個節點重新上線時, FAIL 標記就會被移除。保持(retaning)從節點的 FAIL 狀態是沒有意義的,因為它不處理任何槽,一個從節點是否處於 FAIL 狀態,決定了這個從節點在有需要時能否被提升為主節點。 2)如果一個主節點被打上 FAIL 標記之後,經過了節點超時時限的四倍時間,再加上十秒鐘之後,針對這個主節點的槽的故障轉移操作仍未完成,並且這個主節點已經重新上線的話,那麼移除對這個節點的 FAIL 標記。 在第二種情況中,如果故障轉移未能順利完成,並且主節點重新上線,那麼叢集就繼續使用原來的主節點,從而免去管理員介入的必要。 5.從節點選舉 一旦某個主節點進入 FAIL 狀態,如果這個主節點有一個或多個從節點存在,那麼其中一個從節點會被升級為新的主節點,而其他從節點則會開始對這個新的主節點進行復制。 新的主節點由已下線主節點屬下的所有從節點中自行選舉產生,以下是選舉的條件: 1)這個節點是已下線主節點的從節點。 2)已下線主節點負責處理的槽數量非空。 3)從節點的資料被認為是可靠的,也即是,主從節點之間的複製連線(replication link)的斷線時長不能超過節點超時時限(node timeout)乘以REDIS_CLUSTER_SLAVE_VALIDITY_MULT 常量得出的積。 如果一個從節點滿足了以上的所有條件,那麼這個從節點將向叢集中的其他主節點發送授權請求,詢問它們,是否允許自己(從節點)升級為新的主節點。 如果傳送授權請求的從節點滿足以下屬性,那麼主節點將向從節點返回 FAILOVER_AUTH_GRANTED 授權,同意從節點的升級要求: 1)傳送授權請求的是一個從節點,並且它所屬的主節點處於 FAIL 狀態。 2)在已下線主節點的所有從節點中,這個從節點的節點 ID 在排序中是最小的。 3)從節點處於正常的執行狀態:它沒有被標記為 FAIL 狀態,也沒有被標記為 PFAIL 狀態。 一旦某個從節點在給定的時限內得到大部分主節點的授權,它就會開始執行以下故障轉移操作: 1)通過 PONG 資料包(packet)告知其他節點,這個節點現在是主節點了。 2)通過 PONG 資料包告知其他節點,這個節點是一個已升級的從節點(promoted slave)。 3)接管(claiming)所有由已下線主節點負責處理的雜湊槽。 4)顯式地向所有節點廣播一個 PONG 資料包,加速其他節點識別這個節點的進度,而不是等待定時的 PING / PONG 資料包。 5)所有其他節點都會根據新的主節點對配置進行相應的更新,特別地: a.所有被新的主節點接管的槽會被更新。 b.已下線主節點的所有從節點會察覺到 PROMOTED 標誌,並開始對新的主節點進行復制。 c.如果已下線的主節點重新回到上線狀態,那麼它會察覺到 PROMOTED 標誌,並將自身調整為現任主節點的從節點。 在叢集的生命週期中,如果一個帶有 PROMOTED 標識的主節點因為某些原因轉變成了從節點,那麼該節點將丟失它所帶有的 PROMOTED 標識。 總結 Redis叢集具有高可用,易於遷移,存取速度快等特點。也可以作為訊息佇列使用,支援pub/sub模式,具體優缺點總結如下: 優點: 1、redis 在主節點下線後,從節點會自動提升為主節點,提供服務 2、redis 宕機節點恢復後,自動會新增到叢集中,變成從節點 3、動態擴充套件和刪除節點,rehash slot的分配,基於桶的資料分佈方式大大降低了遷移成本,只需將資料桶從一個Redis Node遷移到另一個Redis Node即可完成遷移。 4、Redis Cluster使用非同步複製。 缺點: 1、由於redis的複製使用非同步機制,在自動故障轉移的過程中,叢集可能會丟失寫命令。然而 redis 幾乎是同時執行(將命令恢復傳送給客戶端,以及將命令複製到從節點)這兩個操作,所以實際中,命令丟失的視窗非常小。 2、普通的主從模式支援auth加密認證,雖然比較弱,但寫或者讀都要通過密碼驗證,cluster對密碼支援不太友好,如果對叢集設定密碼,那麼requirepass和masterauth都需要設定,否則發生主從切換時,就會遇到授權問題,可以模擬並觀察日誌。
主從模式採用一主三從,主從都配置auth認證,讀寫分離。 主要實驗的動作: 1)多個app 同時寫,測定寫速率; 2)多個app 同時寫,同時有讀的程序,測定讀寫速率; 3)master主機宕機,app依然進行讀寫。 2.cluster拓撲圖如下
叢集模式採用四主四從,也是採用讀寫分離。 主要實驗的動作: 1)有一個master宕機,觀察日誌,新的slave成為master; 2)master宕機後,重新啟動,master成為slave; 3)叢集全部宕機,redis主機重啟,資料未丟失。 原理 1.一致性 filesnapshot:預設redis是會以快照的形式將資料持久化到磁碟,在配置檔案中的格式是:save N M表示在N秒之內,redis至少發生M次修改則redis抓快照到磁碟。 工作原理:當redis需要做持久化時,redis會fork一個子程序;子程序將資料寫到磁碟上一個臨時RDB檔案中;當子程序完成寫臨時檔案後, 將原來的RDB替換掉,這樣的好處就是可以copy-on-write。 Append-only:filesnapshotting方法在redis異常死掉時, 最近的資料會丟失(丟失資料的多少視你save策略的配置),所以這是它最大的缺點,當業務量很大時,丟失的資料是很多的。Append-only方法可 以做到全部資料不丟失,但redis的效能就要差些。AOF就可以做到全程持久化,只需要在配置檔案中開啟(預設是no),appendonly yes開啟AOF之後,redis每執行一個修改資料的命令,都會把它新增到aof檔案中,當redis重啟時,將會讀取AOF檔案進行“重放”以恢復到 redis關閉前的最後時刻。 AOF檔案重新整理的方式,有三種,參考配置引數appendfsync :appendfsync always每提交一個修改命令都呼叫fsync重新整理到AOF檔案,非常非常慢,但也非常安全; appendfsync everysec每秒鐘都呼叫fsync重新整理到AOF檔案,很快,但可能會丟失一秒以內的資料;appendfsync no依靠OS進行重新整理, redis不主動重新整理AOF,這樣最快,但安全性就差。預設並推薦每秒重新整理,這樣在速度和安全上都做到了兼顧。 Slave同樣可以接受其它Slaves的連線和同步請求,這樣可以有效的分載Master的同步壓力。因此我們可以將Redis的Replication架構視為圖結構。 Master Server是以非阻塞的方式為Slaves提供服務。所以在Master-Slave同步期間,客戶端仍然可以提交查詢或修改請求。 Slave Server同樣是以非阻塞的方式完成資料同步。在同步期間,如果有客戶端提交查詢請求,Redis則返回同步之前的資料。 為了分載Master的讀操作壓力,Slave伺服器可以為客戶端提供只讀操作的服務,寫服務仍然必須由Master來完成。即便如此,系統的伸縮性還是得到了很大的提高。 Master可以將資料儲存操作交給Slaves完成,從而避免了在Master中要有獨立的程序來完成此操作。 Redis在master是非阻塞模式,也就是說在slave執行資料同步的時候,master是可以接受客戶端的請求的,並不影響同步資料的一致性,然而在slave端是阻塞模式的,slave在同步master資料時,並不能夠響應客戶端的查詢。 2.Replication的工作原理 (1)Slave伺服器連線到Master伺服器. (2)Slave伺服器傳送SYCN命令. (3)Master伺服器備份資料庫到.rdb檔案. (4)Master伺服器把.rdb檔案傳輸給Slave伺服器. (5)Slave伺服器把.rdb檔案資料匯入到資料庫中。 在Slave啟動並連線到Master之後,它將主動傳送一個SYNC命令。此後Master將啟動後臺存檔程序,同時收集所有接收到的用於修改資料集 的命令,在後臺程序執行完畢後,Master將傳送整個資料庫檔案到Slave,以完成一次完全同步。而Slave伺服器在接收到資料庫檔案資料之後將其 存檔並載入到記憶體中。此後,Master繼續將所有已經收集到的修改命令,和新的修改命令依次傳送給Slaves,Slave將在本次執行這些資料修改命 令,從而達到最終的資料同步。 如果Master和Slave之間的連結出現斷連現象,Slave可以自動重連Master,但是在連線成功之後,一次完全同步將被自動執行。 3.一致性雜湊 叢集要實現的目的是要將不同的 key 分散放置到不同的 redis 節點,這裡我們需要一個規則或者演算法,通常的做法是獲取 key 的雜湊值,然後根據節點數來求模,但這種做法有其明顯的弊端,當我們需要增加或減少一個節點時,會造成大量的 key 無法命中,這種比例是相當高的,所以就有人提出了一致性雜湊的概念。 一致性雜湊有四個重要特徵: 均衡性:也有人把它定義為平衡性,是指雜湊的結果能夠儘可能分佈到所有的節點中去,這樣可以有效的利用每個節點上的資源。 單調性:對於單調性有很多翻譯讓我非常的不解,而我想要的是當節點數量變化時雜湊的結果應儘可能的保護已分配的內容不會被重新分派到新的節點。 分散性和負載:這兩個其實是差不多的意思,就是要求一致性雜湊演算法對 key 雜湊應儘可能的避免重複。 Redis 叢集中內建了 16384 個雜湊槽,當需要在 Redis 叢集中放置一個 key-value 時,redis 先對 key 使用 crc16 演算法算出一個結果,然後把結果對 16384 求餘數,這樣每個 key 都會對應一個編號在 0-16383 之間的雜湊槽,redis 會根據節點數量大致均等的將雜湊槽對映到不同的節點。 使用雜湊槽的好處就在於可以方便的新增或移除節點。 當需要增加節點時,只需要把其他節點的某些雜湊槽挪到新節點就可以了; 當需要移除節點時,只需要把移除節點上的雜湊槽挪到其他節點就行了; 當設定了主從關係後,slave 在第一次連線或者重新連線 master 時,slave 都會發送一條同步指令給 master ; master 接到指令後,開始啟動後臺儲存程序儲存資料,接著收集所有的資料修改指令。後臺儲存完了,master 就把這份資料傳送給 slave,slave 先把資料儲存到磁碟,然後把它載入到記憶體中,master 接著就把收集的資料修改指令一行一行的發給 slave,slave 接收到之後重新執行該指令,這樣就實現了資料同步。 slave 在與 master 失去聯絡後,自動的重新連線。如果 master 收到了多個 slave 的同步請求,它會執行單個後臺儲存來為所有的 slave 服務。 4.節點失效檢測 以下是節點失效檢查的實現方法: 1)當一個節點向另一個節點發送 PING 命令,但是目標節點未能在給定的時限內返回 PING 命令的回覆時,那麼傳送命令的節點會將目標節點標記為PFAIL (possible failure,可能已失效)。 2)等待 PING 命令回覆的時限稱為“節點超時時限(node timeout)”,是一個節點選項(node-wise setting)。 3)每次當節點對其他節點發送 PING 命令的時候,它都會隨機地廣播三個它所知道的節點的資訊,這些資訊裡面的其中一項就是說明節點是否已經被標記為 PFAIL 或者 FAIL 。 4)當節點接收到其他節點發來的資訊時,它會記下那些被其他節點標記為失效的節點。這稱為失效報告(failure report)。 5)如果節點已經將某個節點標記為 PFAIL ,並且根據節點所收到的失效報告顯式,叢集中的大部分其他主節點也認為那個節點進入了失效狀態,那麼節點會將那個失效節點的狀態標記為 FAIL 。 6)一旦某個節點被標記為 FAIL ,關於這個節點已失效的資訊就會被廣播到整個叢集,所有接收到這條資訊的節點都會將失效節點標記為 FAIL 。 簡單來說,一個節點要將另一個節點標記為失效,必須先詢問其他節點的意見,並且得到大部分主節點的同意才行。因為過期的失效報告會被移除,所以主節點要將某個節點標記為 FAIL 的話,必須以最近接收到的失效報告作為根據。 在以下兩種情況中,節點的 FAIL 狀態會被移除: 1)如果被標記為 FAIL 的是從節點,那麼當這個節點重新上線時, FAIL 標記就會被移除。保持(retaning)從節點的 FAIL 狀態是沒有意義的,因為它不處理任何槽,一個從節點是否處於 FAIL 狀態,決定了這個從節點在有需要時能否被提升為主節點。 2)如果一個主節點被打上 FAIL 標記之後,經過了節點超時時限的四倍時間,再加上十秒鐘之後,針對這個主節點的槽的故障轉移操作仍未完成,並且這個主節點已經重新上線的話,那麼移除對這個節點的 FAIL 標記。 在第二種情況中,如果故障轉移未能順利完成,並且主節點重新上線,那麼叢集就繼續使用原來的主節點,從而免去管理員介入的必要。 5.從節點選舉 一旦某個主節點進入 FAIL 狀態,如果這個主節點有一個或多個從節點存在,那麼其中一個從節點會被升級為新的主節點,而其他從節點則會開始對這個新的主節點進行復制。 新的主節點由已下線主節點屬下的所有從節點中自行選舉產生,以下是選舉的條件: 1)這個節點是已下線主節點的從節點。 2)已下線主節點負責處理的槽數量非空。 3)從節點的資料被認為是可靠的,也即是,主從節點之間的複製連線(replication link)的斷線時長不能超過節點超時時限(node timeout)乘以REDIS_CLUSTER_SLAVE_VALIDITY_MULT 常量得出的積。 如果一個從節點滿足了以上的所有條件,那麼這個從節點將向叢集中的其他主節點發送授權請求,詢問它們,是否允許自己(從節點)升級為新的主節點。 如果傳送授權請求的從節點滿足以下屬性,那麼主節點將向從節點返回 FAILOVER_AUTH_GRANTED 授權,同意從節點的升級要求: 1)傳送授權請求的是一個從節點,並且它所屬的主節點處於 FAIL 狀態。 2)在已下線主節點的所有從節點中,這個從節點的節點 ID 在排序中是最小的。 3)從節點處於正常的執行狀態:它沒有被標記為 FAIL 狀態,也沒有被標記為 PFAIL 狀態。 一旦某個從節點在給定的時限內得到大部分主節點的授權,它就會開始執行以下故障轉移操作: 1)通過 PONG 資料包(packet)告知其他節點,這個節點現在是主節點了。 2)通過 PONG 資料包告知其他節點,這個節點是一個已升級的從節點(promoted slave)。 3)接管(claiming)所有由已下線主節點負責處理的雜湊槽。 4)顯式地向所有節點廣播一個 PONG 資料包,加速其他節點識別這個節點的進度,而不是等待定時的 PING / PONG 資料包。 5)所有其他節點都會根據新的主節點對配置進行相應的更新,特別地: a.所有被新的主節點接管的槽會被更新。 b.已下線主節點的所有從節點會察覺到 PROMOTED 標誌,並開始對新的主節點進行復制。 c.如果已下線的主節點重新回到上線狀態,那麼它會察覺到 PROMOTED 標誌,並將自身調整為現任主節點的從節點。 在叢集的生命週期中,如果一個帶有 PROMOTED 標識的主節點因為某些原因轉變成了從節點,那麼該節點將丟失它所帶有的 PROMOTED 標識。 總結 Redis叢集具有高可用,易於遷移,存取速度快等特點。也可以作為訊息佇列使用,支援pub/sub模式,具體優缺點總結如下: 優點: 1、redis 在主節點下線後,從節點會自動提升為主節點,提供服務 2、redis 宕機節點恢復後,自動會新增到叢集中,變成從節點 3、動態擴充套件和刪除節點,rehash slot的分配,基於桶的資料分佈方式大大降低了遷移成本,只需將資料桶從一個Redis Node遷移到另一個Redis Node即可完成遷移。 4、Redis Cluster使用非同步複製。 缺點: 1、由於redis的複製使用非同步機制,在自動故障轉移的過程中,叢集可能會丟失寫命令。然而 redis 幾乎是同時執行(將命令恢復傳送給客戶端,以及將命令複製到從節點)這兩個操作,所以實際中,命令丟失的視窗非常小。 2、普通的主從模式支援auth加密認證,雖然比較弱,但寫或者讀都要通過密碼驗證,cluster對密碼支援不太友好,如果對叢集設定密碼,那麼requirepass和masterauth都需要設定,否則發生主從切換時,就會遇到授權問題,可以模擬並觀察日誌。