
redis叢集實現(五) sentinel的架構與raft協議
redis在3.0.0版本開始支援叢集功能,但是實現叢集就要求redis能夠承受單點故障,保證redis的高可用性,在各種軟體和硬體的故障情況下仍然能夠提供服務。一般來說有兩種解決思路,一種是每一個節點互相之間都會進行資料互動以及監控,出現故障的時候,各個節點都可以做協調任務,比如kv分散式儲存cassendra。另一種就是增加一個協調元件來對叢集進行實時監控以及故障處理,比如zookeeper,chubby等。現在使用比較廣泛的是第二種方案,各個模組之間低耦合,工程師能夠專注於自己本身的程式碼邏輯而不需要考慮太多方面,工程實現也比較簡單(相對第一種而言)。
說到分散式協調元件,就不能不說下分散式一致性協議。從集中式變到分散式,雖然解決了單個主機宕機帶來的服務不可用的問題,但是隨之帶來的就是分散式的各個節點一致性的問題。在分散式系統的一致性協議方面,paxos
這裡也有raft協議的各種語言的實現,一併奉獻出來。
瞭解了raft協議,我們就看一下redis的一致性解決方案sentinel的架構設計。sentinel被設計成為類似於chubby,zookeeper之類的一個獨立於資料節點的協調元件,sentinel叢集內的每一個節點都會監控叢集內部的每一個節點的狀態,並將定時交換監控的資訊,如下圖所示:
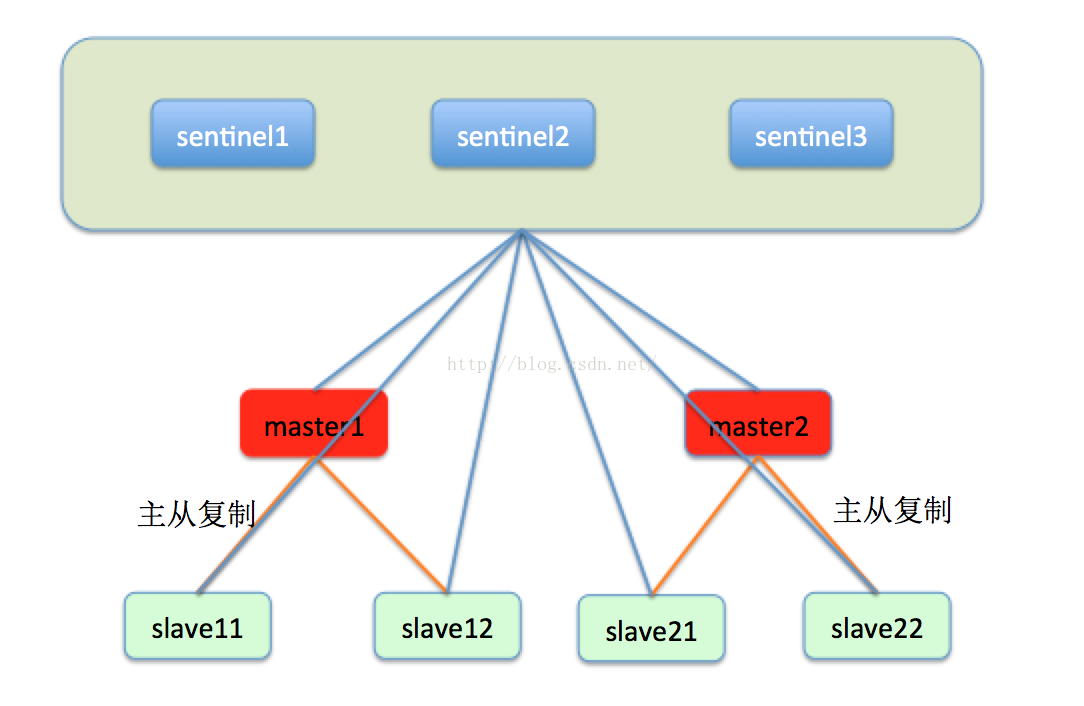
一般來說,sentinel都由五個節點組成,這樣能夠保證即使一臺節點宕機還有四個節點可用,能夠提供比較高的可用性和效能,而又不需要太多的節點。sentinel叢集中的每一個節點都會實時的監控每一個master和slave,master和slave都會定期的向sentinel1,sentinel2,sentinel3彙報自己的狀態。
sentinel在3.0.0版本內並沒有提供分散式事務以及分散式鎖等同步以及事務的功能,僅僅是提供了故障轉移以解決節點宕機問題。我們來看下sentinel是怎麼用raft協議來實現節點宕機處理的。
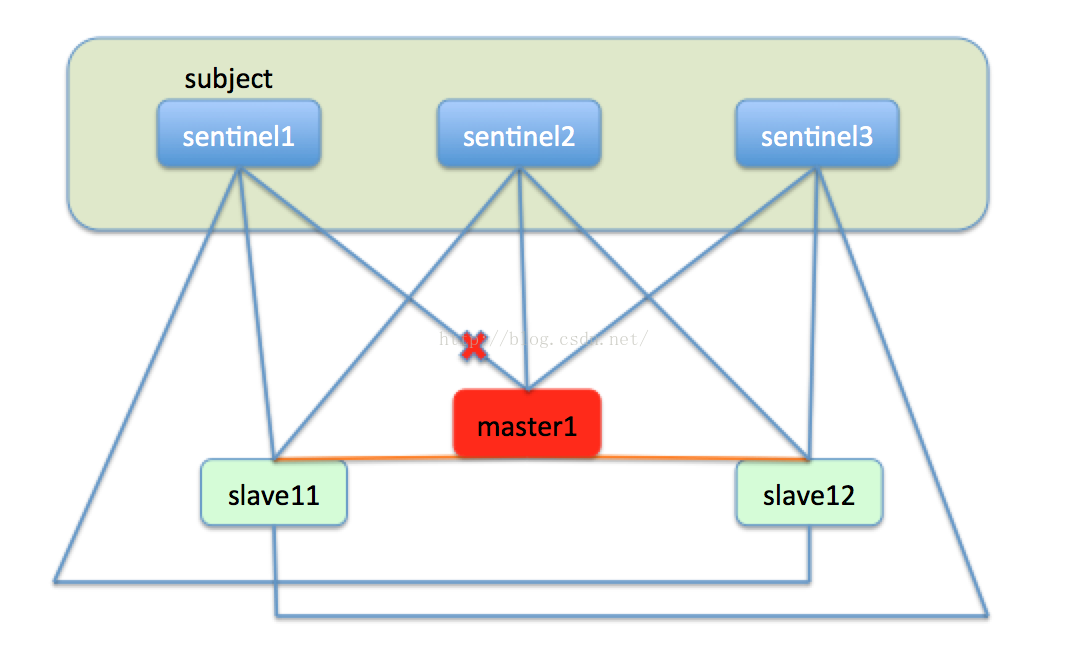
如果一臺master節點,比如master1節點宕機下線,sentinel1發現master1沒有彙報自己的狀態,在sentinel內部有一個節點沒有彙報的最長時間上線,當一個節點超出了這個時間上限,就會在本機標記此節點主觀下線,就是說在本sentinel節點的視角來看,此節點是下線狀態。如下圖:
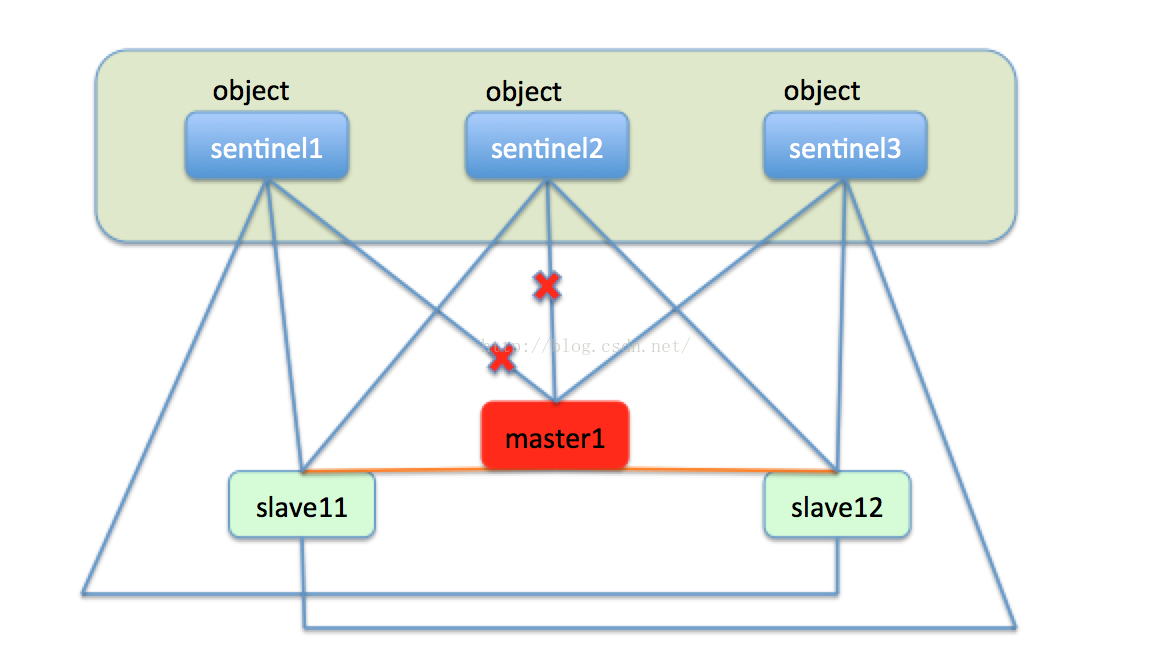
由於sentinel叢集中有三個sentinel節點,只有sentinel1認為master1下線,這就僅僅是主觀下線,還不能處理故障轉移。然後過了一段時間,sentinel2也發現master1好久沒有彙報資訊,也把master1標記未主觀下線。sentinel叢集中的三臺機器會定時交流自己的監控資訊,當sentinel1發現sentinel2也認為master1主觀下線了,就是說叢集中有超過一半的節點認為節點下線了,這時sentinel叢集就會達成一個一致,認為master1已經客觀下線了。如下圖:
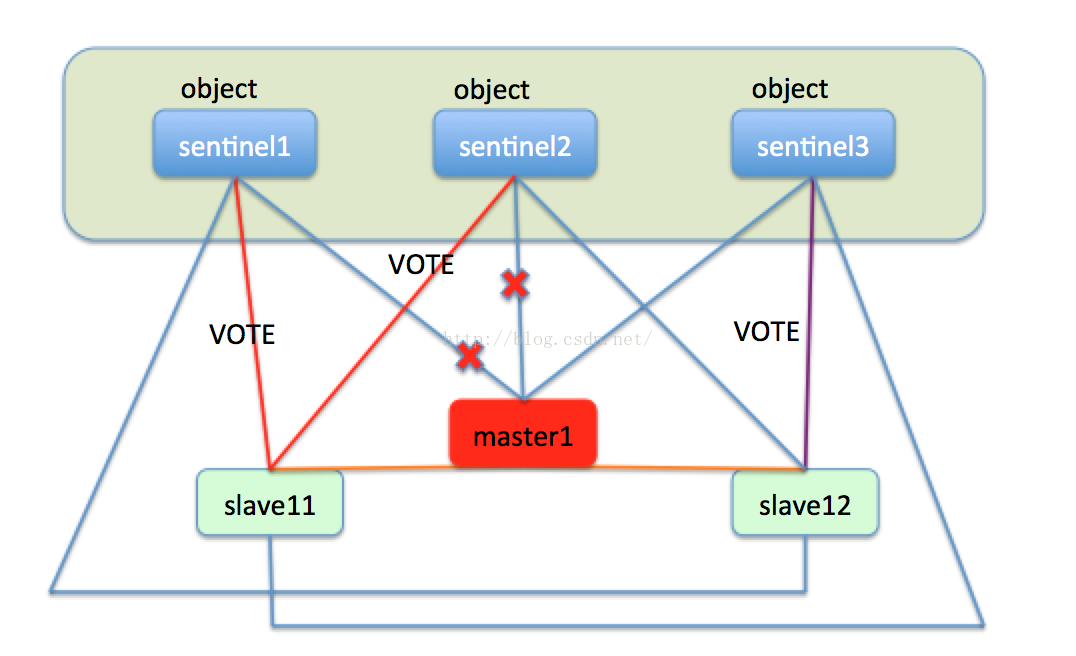
此時sentinel就會開始執行故障轉移,在slave11和slave12中選出新的master節點。首先slave11和slave12變成候選者,等待一個0到1s內的隨機值,然後向sentinel叢集的每一個節點發送求票資訊,希望能選舉自己成為master,每一個sentinel只能投一次票,最終必然有一個節點成為新的master。比如slave11獲取了sentinel1和sentinel2的選票,slave12獲取了sentinel3的選票,最終的結果就是slave11成為master。如下圖:
然後slave11成為master,slave12成為slave11的slave,轉而向slave11進行主從複製。如下圖:
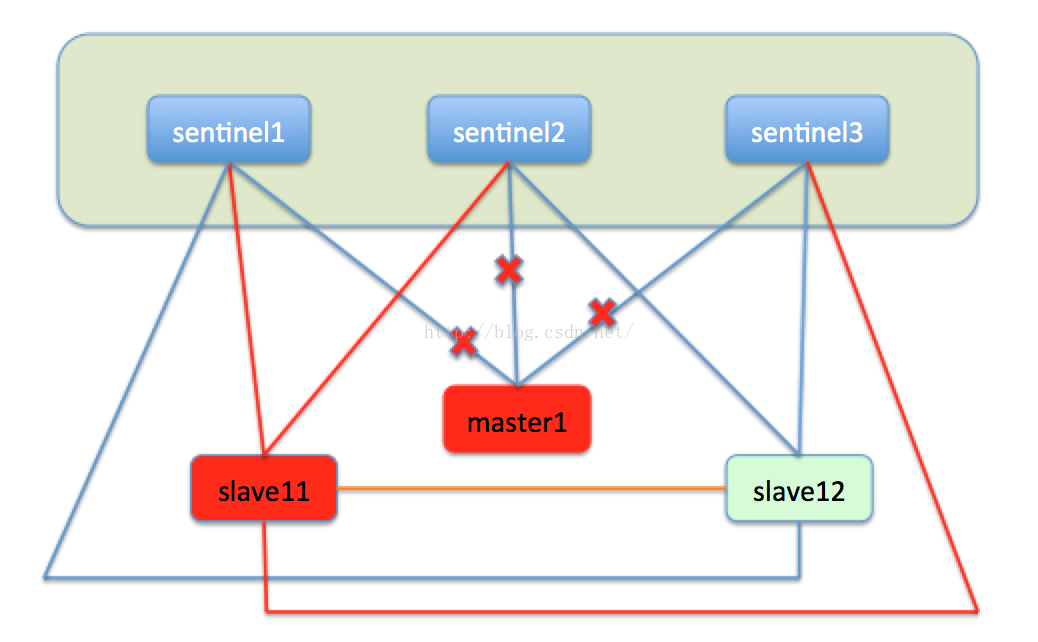
同時sentinel也會監視master1,如果master1經過修復後重新上線,這時的master就會變成slave11的從節點,轉而向master進行主從複製。如下圖:
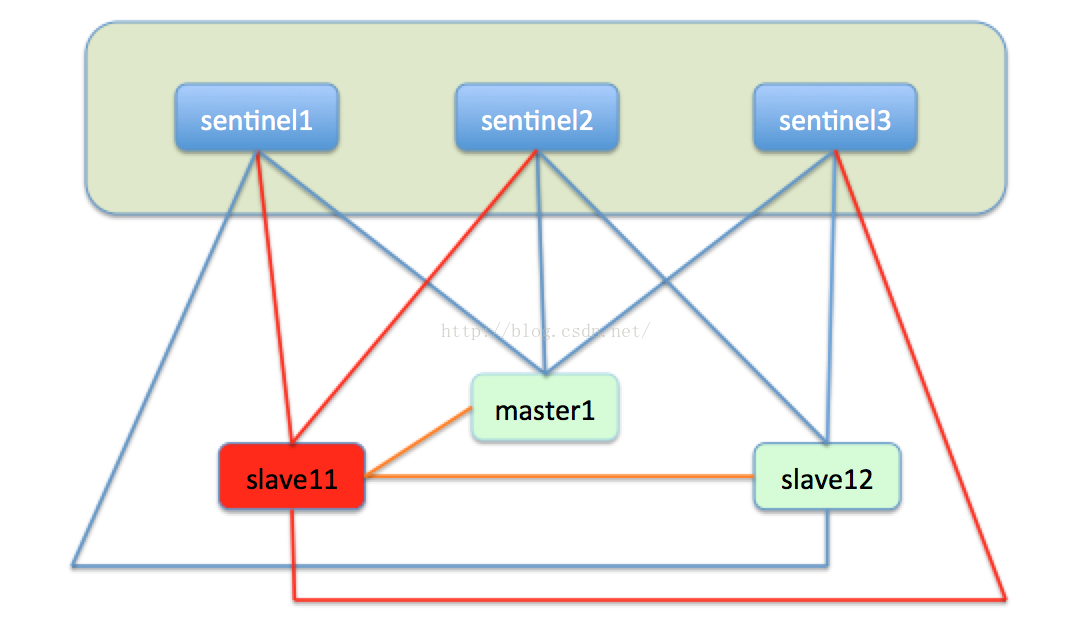
至此,redis的故障轉移就完成了,redis利用比較易於實現的raft協議實現了節點宕機的自動化處理,保障了叢集的高可用性。