
Java IO4:字元編碼
前言
字元編碼,這本不屬於IO的內容,但位元組流之後寫的應該是字元流,既然是字元流,那就涉及一個"字元編碼的"問題,考慮到字元編碼不僅僅是在IO這塊,Java中很多場景都涉及到這個概念,因此這邊文章就專門詳細寫一下字元編碼,具體的網上有很多,但本文目的是儘量講清楚各種編碼方式的作用,個人認為,不求、也沒有必要對字元編碼理解地多麼深入。
字符集和字元編碼
第一個概念就是字符集和字元編碼之間的區別:
字符集(charset)
字符集指的是一個系統支援的所有抽象字元的集合
字元編碼(encoding)
計算機要準確處理各種字符集文字,就要進行字元編碼,以便計算機能夠識別和儲存各種文字。因此字元編碼就是將符號轉換為計算機可以接受的數字系統的數,稱為數字程式碼。
ASCII碼
計算機裡面只有數字0和1(嚴格說連0和1都沒有,只有開和關,無非是用0和1表示開關的狀態罷了),在計算機軟體裡的一切都是用數字標識的額,螢幕上顯示的一個一個字元也是數字。最初使用的計算機在美國,用到的字元很少,因此每一個字元都用一個數字表示,一個位元組所能表示的數字

1、0~31是控制字元,如換行、回車、刪除等
2、32~126是列印字元,可以通過鍵盤輸入並且能夠顯示出來
GB2312和GBK
隨著計算機在其它國家的普及,許多國家把本地字符集引入了計算機,大大擴充套件了計算機中字元的範圍。一個位元組所能表示的範圍不足以容納中文字元(看看上面的ASCII碼錶就知道了),中國大陸將每一箇中文字元都用兩個位元組表示,原有的ASCII碼字元的編碼保持不變。
為了將一箇中文字元與兩個ASCII碼字元相區別,中文字元的每個位元組最高位為1,中國大陸為每一箇中文字元都指定了一個對應的數字,並於1980年制定了一套《資訊科技 中文編碼字符集》,這套規範就是GB2312。GB2312是雙位元組編碼,總的編碼範圍是A1~F7,其實A1~A9是符號區,總共包含682個符號;B0~F7是漢字區,總共包含6763個漢字。
GBK是在1995年制定的後續標準,全稱為《漢字內碼擴充套件規範》,是國家技術監督局為Windows 95所制定的新的漢字內碼規範。GBK的出現是為了擴充套件GBK2312,並加入更多的漢字。GBK的編碼範圍是8140~FEFE(去掉XX7F),總共有23940個碼位,能表示21003個漢字,它的編碼是和GB2312相容的,也就是說用GB2312編碼的漢字可以用GBK來解碼,並且不會有亂碼問題。GBK還是現如今中文Windows作業系統的系統預設編碼。
Unicode
在一個國家的本地化系統中出現的一個字元,通過電子郵件傳送到另外一個國家的本地化系統中,看到的就不是那個原始字元了,而是另外那個國家的一個字元或亂碼,因為計算機裡面並沒有真正的字元,字元都是以數字的形式存在的,通過郵件傳送一個字元,實際上傳送的是這個字元對應的字元編碼,同一個數字在不同的國家和地區代表的很可能是不同的符號。
為了解決各個國家和地區之間各自使用不同的本地化字元編碼帶來的不便,人們將全世界所有的符號進行了統一編碼,稱之為Unicode(統一碼、萬國碼)。所有字元不再區分國家和地區,都是人類共有的符號,如"中"字在Unicode中不再是GBK中的D6D0,而是在任何地方都是4e2d,如果所有的計算機系統都使用這種編碼方式,那麼4e2d這個字在任何地方都代表漢字中的"中"。Unicode編碼的字元都佔用兩個位元組的大小,也就是說全世界所有字元個數不會超過65536個。
當然Unicode只包含65536個字元就想包含全世界所有的字元是遠遠不夠的,所以Unicode提供了字元平面對映,連結地址上就是Wiki百科對於字元平面對映的解讀。另外要提一點的是,Unicode是Java和XML的基礎。
UTF-8和UTF-16(Unicode 的實現方式之一)
Unicode是一種字符集標準,而具體該標準應該如何應用到計算機中,則是另一個話題了,常用的Unicode編碼方式有兩種:
1、UTF-16。兩個位元組表示Unicode轉換格式,這是定長的表示方法。也就是說不管什麼字元都可以使用兩個位元組表示,兩個位元組是16Bit,所以叫做UTF-16。UTF-16編碼非常方便,每兩個位元組表示一個字元,這個在字串操作時大大簡化了操作。
2、UTF-8。UTF-16統一採用了兩個位元組表示一個字元,雖然在表示上非常簡單,但是很大一部分字元用一個位元組表示就夠了,現在需要兩個位元組,儲存空間放大了一倍。UTF-8就採取了一種變長技術,每個編碼區域有不同的字碼長度,不同型別的字元可以是由1~6個位元組組成。
兩種編碼方式比較,相對來說,UTF-16的編碼效率較高,從字元到位元組的相互轉換可以更簡單,進行字串操作也更好,它更適合在本地磁碟和記憶體之間使用,可以進行字元和位元組之間的快速切換。但是UTF-16並不適合在網路之間傳輸,因為網路傳輸易損壞位元組流,一旦位元組流損壞將很難恢復,所以相比較而言UTF-8更適合網路傳輸。另外UTF-8對ASCII字符采用單位元組儲存,單個字元損壞也不會影響後面的其他字元,在編碼效率上介於GBK和UTF-16之間,所以,UTF-8在編碼效率和編碼安全性上做了平衡,是理想的中文編碼方式。
Java與字元編碼
Java中的字元使用的都是Unicode字符集,編碼方式為UTF-16,Java技術在通過Unicode保證跨平臺特性的前提下也支援了全擴充套件的本地平臺字符集,而顯示輸出和鍵盤輸入都是採用的本地編碼。因此,免不了二者的轉化問題。
看一個很簡單的例子:
public static void main(String[] args) throws Exception
{
// 這裡將字串通過getBytes()方法,編碼成GB2312
byte b[] = "大家一起來學習Java語言".getBytes("GB2312");
File file = new File("D:/Files/encoding.txt");
OutputStream out = new FileOutputStream(file);
out.write(b);
out.close();
}看一下檔案中是什麼:

正常輸出,無編碼問題,但是如果這樣:
public static void main(String[] args) throws Exception
{
// 這裡將字串通過getBytes()方法,編碼成ISO8859-1
byte b[] = "大家一起來學習Java語言".getBytes("ISO8859-1");
File file = new File("D:/Files/encoding.txt");
OutputStream out = new FileOutputStream(file);
out.write(b);
out.close();
}再看一下檔案中是什麼:

亂碼問題就出現了,通過上述操作的完整過程分析一下原因。
要再次說明的是,Java中的String都是Unicode字符集的。Java中的各個類,對於英文字元的支援都非常好,可以正常地寫入檔案中,但對於中文字元就未必了。從Java原始碼到輸入檔案正確的內容,要經過"Java原始碼->Java位元組碼->虛擬機器->檔案"幾個步驟,在上述過程中的每一步都必須正確地處理漢字的編碼,才能夠使最終有我們期望的結果。
"Java原始碼->Java位元組碼",標準的Java編譯器Javac使用的字符集是系統預設的字符集,比如在中文Windows作業系統上就是GBK(上面GBK的部分已經說明過了),而在Linux作業系統上就是ISO8859-1,所以大家會發現Linux作業系統上編譯的類中原始檔中的中文字元都出現了問題,解決辦法就是在編譯的時候新增encoding引數,這樣才能夠與平臺無關,用法是:javac -encoding GBK。
"Java位元組碼->虛擬機器->檔案",Java執行環境(JRE)分英文版和國際版,但只有國際版才支援非英文字元。Java開發工具包(JDK)肯定支援多國字元,但並非所有的計算機使用者都安裝了JDK。很多作業系統應用軟體為了能夠更好地支援Java,都內嵌了JRE的國際版本,為支援自己多國字元提供了方便。
問題就出"Java原始碼->Java位元組碼上",這是由於JDK設定環境變數引起的。用程式看一下JDK環境變數:
public static void main(String[] args)
{
System.getProperties().list(System.out);
}看一下輸出的全部資訊,有點長:
-- listing properties --
java.runtime.name=Java(TM) SE Runtime Environment
sun.boot.library.path=E:\MyEclipse10\Common\binary\com.sun....
java.vm.version=11.3-b02
java.vm.vendor=Sun Microsystems Inc.
java.vendor.url=http://java.sun.com/
path.separator=;
java.vm.name=Java HotSpot(TM) 64-Bit Server VM
file.encoding.pkg=sun.io
user.country=CN
sun.java.launcher=SUN_STANDARD
sun.os.patch.level=
java.vm.specification.name=Java Virtual Machine Specification
user.dir=F:\程式碼\MyEclipse\TestIO
java.runtime.version=1.6.0_13-b03
java.awt.graphicsenv=sun.awt.Win32GraphicsEnvironment
java.endorsed.dirs=E:\MyEclipse10\Common\binary\com.sun....
os.arch=amd64
java.io.tmpdir=C:\Users\dell1\AppData\Local\Temp\
line.separator=
java.vm.specification.vendor=Sun Microsystems Inc.
user.variant=
os.name=Windows Vista
sun.jnu.encoding=GBK
java.library.path=E:\MyEclipse10\Common\binary\com.sun....
java.specification.name=Java Platform API Specification
java.class.version=50.0
sun.management.compiler=HotSpot 64-Bit Server Compiler
os.version=6.2
user.home=C:\Users\dell1
user.timezone=
java.awt.printerjob=sun.awt.windows.WPrinterJob
file.encoding=GBK
java.specification.version=1.6
user.name=dell1
java.class.path=F:\程式碼\MyEclipse\TestIO\bin
java.vm.specification.version=1.0
sun.arch.data.model=64
java.home=E:\MyEclipse10\Common\binary\com.sun....
java.specification.vendor=Sun Microsystems Inc.
user.language=zh
awt.toolkit=sun.awt.windows.WToolkit
java.vm.info=mixed mode
java.version=1.6.0_13
java.ext.dirs=E:\MyEclipse10\Common\binary\com.sun....
sun.boot.class.path=E:\MyEclipse10\Common\binary\com.sun....
java.vendor=Sun Microsystems Inc.
file.separator=\
java.vendor.url.bug=http://java.sun.com/cgi-bin/bugreport...
sun.cpu.endian=little
sun.io.unicode.encoding=UnicodeLittle
sun.desktop=windows
sun.cpu.isalist=amd64注意一下34行,表明了JDK使用的是GBK字符集(GBK是GB2312上的擴充套件,所以用GB2312字符集當然是沒有問題的),這意味著Java對String的操作,都做了Unicode到GBK的轉換。既然JDK用的GBK編碼,那麼用ISO8859-1字符集顯示GBK編碼出來的中文當然是有問題的。
這只是一個例子,在我們的應用程式中涉及I/O操作時,一般只要注意指定統一的編解碼Charset集,就不會出現亂碼問題。對有些應用程式如果不注意指定字元編碼,則在中文環境中會使用作業系統的預設編碼。如果編解碼都在中文環境中,通常也沒有問題,但還是強烈建議不要使用作業系統的預設編碼,因為這樣會使你的應用程式的編碼格式和執行時環境繫結起來,這樣在跨環境時很可能出現亂碼問題。
補充:
- Unicode 的問題
第一個問題是,如何才能區別 Unicode 和 ASCII ?計算機怎麼知道三個位元組表示一個符號,而不是分別表示三個符號呢?
第二個問題是,我們已經知道,英文字母只用一個位元組表示就夠了,如果 Unicode 統一規定,每個符號用三個或四個位元組表示,那麼每個英文字母前都必然有二到三個位元組是0,這對於儲存來說是極大的浪費,文字檔案的大小會因此大出二三倍,這是無法接受的。
它們造成的結果是:1)出現了 Unicode 的多種儲存方式,也就是說有許多種不同的二進位制格式,可以用來表示 Unicode。2)Unicode 在很長一段時間內無法推廣,直到網際網路的出現。
2.UTF-8編碼方式
網際網路的普及,強烈要求出現一種統一的編碼方式。UTF-8 就是在網際網路上使用最廣的一種 Unicode 的實現方式。其他實現方式還包括 UTF-16(字元用兩個位元組或四個位元組表示)和 UTF-32(字元用四個位元組表示),不過在網際網路上基本不用。重複一遍,這裡的關係是,UTF-8 是 Unicode 的實現方式之一。
UTF-8 最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個位元組表示一個符號,根據不同的符號而變化位元組長度。
UTF-8 的編碼規則很簡單,只有二條:
1)對於單位元組的符號,位元組的第一位設為0,後面7位為這個符號的 Unicode 碼。因此對於英語字母,UTF-8 編碼和 ASCII 碼是相同的。
2)對於n位元組的符號(n > 1),第一個位元組的前n位都設為1,第n + 1位設為0,後面位元組的前兩位一律設為10。剩下的沒有提及的二進位制位,全部為這個符號的 Unicode 碼。
下表總結了編碼規則,字母x表示可用編碼的位。
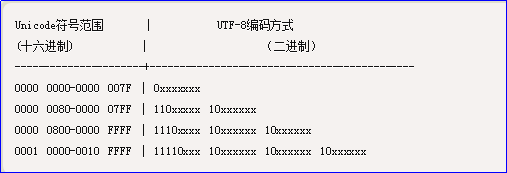
跟據上表,解讀 UTF-8 編碼非常簡單。如果一個位元組的第一位是0,則這個位元組單獨就是一個字元;如果第一位是1,則連續有多少個1,就表示當前字元佔用多少個位元組。
下面,還是以漢字嚴為例,演示如何實現 UTF-8 編碼。
嚴的 Unicode 是4E25(100111000100101),根據上表,可以發現4E25處在第三行的範圍內(0000 0800 - 0000 FFFF),因此嚴的 UTF-8 編碼需要三個位元組,即格式是1110xxxx 10xxxxxx 10xxxxxx。然後,從嚴的最後一個二進位制位開始,依次從後向前填入格式中的x,多出的位補0。這樣就得到了,嚴的 UTF-8 編碼是11100100 10111000 10100101,轉換成十六進位制就是E4B8A5。