
MySQL索引與Index Condition Pushdown(employees示例)
實驗
先從一個簡單的實驗開始直觀認識ICP的作用。
安裝資料庫
首先需要安裝一個支援ICP的MariaDB或MySQL資料庫。我使用的是MariaDB 5.5.34,如果是使用MySQL則需要5.6版本以上。
Mac環境下可以通過brew安裝:
- brew install mairadb
其它環境下的安裝請參考MariaDB官網關於下載安裝的文件。
匯入示例資料
與前文一樣,我們使用Employees Sample Database,作為示例資料庫。完整示例資料庫的下載地址為:https://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2
將下載的壓縮包解壓後,會看到一系列的檔案,其中employees.sql就是匯入資料的命令檔案。執行
- mysql -h[host] -u[user] -p < employees.sql
就可以完成建庫、建表和load資料等一系列操作。此時資料庫中會多一個叫做employees的資料庫。庫中的表如下:
- MariaDB [employees]> SHOW TABLES;
- +---------------------+
- | Tables_in_employees |
- +---------------------+
- | departments |
- | dept_emp |
- | dept_manager |
- | employees |
- | salaries |
- | titles |
- +---------------------+
- 6 rows in set (0.00 sec)
我們將使用employees表做實驗。
建立聯合索引
employees表包含僱員的基本資訊,表結構如下:
- MariaDB [employees]> DESC employees.employees;
- +------------+---------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +------------+---------------+------+-----+---------+-------+
- | emp_no | int(11) | NO | PRI | NULL | |
- | birth_date | date | NO | | NULL | |
- | first_name | varchar(14) | NO | | NULL | |
- | last_name | varchar(16) | NO | | NULL | |
- | gender | enum('M','F') | NO | | NULL | |
- | hire_date | date | NO | | NULL | |
- +------------+---------------+------+-----+---------+-------+
- 6 rows in set (0.01 sec)
這個表預設只有一個主索引,因為ICP只能作用於二級索引,所以我們建立一個二級索引:
- ALTER TABLE employees.employees ADD INDEX first_name_last_name (first_name, last_name);
這樣就建立了一個first_name和last_name的聯合索引。
查詢
為了明確看到查詢效能,我們啟用profiling並關閉query cache:
- SET profiling = 1;
- SET query_cache_type = 0;
- SET GLOBAL query_cache_size = 0;
然後我們看下面這個查詢:
- MariaDB [employees]> SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
- +--------+------------+------------+-----------+--------+------------+
- | emp_no | birth_date | first_name | last_name | gender | hire_date |
- +--------+------------+------------+-----------+--------+------------+
- | 254642 | 1959-01-17 | Mary | Botman | M | 1989-11-24 |
- | 471495 | 1960-09-24 | Mary | Dymetman | M | 1988-06-09 |
- | 211941 | 1962-08-11 | Mary | Hofman | M | 1993-12-30 |
- | 217707 | 1962-09-05 | Mary | Lichtman | F | 1987-11-20 |
- | 486361 | 1957-10-15 | Mary | Oberman | M | 1988-09-06 |
- | 457469 | 1959-07-15 | Mary | Weedman | M | 1996-11-21 |
- +--------+------------+------------+-----------+--------+------------+
根據MySQL索引的字首匹配原則,兩者對索引的使用是一致的,即只有first_name採用索引,last_name由於使用了模糊字首,沒法使用索引進行匹配。我將查詢聯絡執行三次,結果如下:
- +----------+------------+---------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+---------------------------------------------------------------------------+
- | 38 | 0.00084400 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 39 | 0.00071800 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 40 | 0.00089600 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- +----------+------------+---------------------------------------------------------------------------+
然後我們關閉ICP:
- SET optimizer_switch='index_condition_pushdown=off';
在執行三次相同的查詢,結果如下:
- +----------+------------+---------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+---------------------------------------------------------------------------+
- | 42 | 0.00264400 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 43 | 0.01418900 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 44 | 0.00234200 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- +----------+------------+---------------------------------------------------------------------------+
有意思的事情發生了,關閉ICP後,同樣的查詢,耗時是之前的三倍以上。下面我們用explain看看兩者有什麼區別:
- MariaDB [employees]> EXPLAIN SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
- | 1 | SIMPLE | employees | ref | first_name_last_name | first_name_last_name | 44 | const | 224 | Using index condition |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
- 1 row in set (0.00 sec)
- MariaDB [employees]> EXPLAIN SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
- | 1 | SIMPLE | employees | ref | first_name_last_name | first_name_last_name | 44 | const | 224 | Using where |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
- 1 row in set (0.00 sec)
前者是開啟ICP,後者是關閉ICP。可以看到區別在於Extra,開啟ICP時,用的是Using index condition;關閉ICP時,是Using where。
其中Using index condition就是ICP提高查詢效能的關鍵。下一節說明ICP提高查詢效能的原理。
[email protected]:3306.sock [employees]> EXPLAIN format=json SELECT * FROM employees
-> WHERE first_name='Mary' AND last_name LIKE '%man'\G;
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "268.80"
},
"table": {
"table_name": "employees",
"access_type": "ref",
"possible_keys": [
"first_name_last_name"
],
"key": "first_name_last_name",
"used_key_parts": [
"first_name"
],
"key_length": "58",
"ref": [
"const"
],
"rows_examined_per_scan": 224,
"rows_produced_per_join": 24,
"filtered": "11.11",
"index_condition": "(employees.employees.last_name like '%man')",
"cost_info": {
"read_cost": "224.00",
"eval_cost": "4.98",
"prefix_cost": "268.80",
"data_read_per_join": "3K"
},
"used_columns": [
"emp_no",
"birth_date",
"first_name",
"last_name",
"gender",
"hire_date"
]
}
}
}
1 row in set, 1 warning (0.00 sec)
原理
ICP的原理簡單說來就是將可以利用索引篩選的where條件在儲存引擎一側進行篩選,而不是將所有index access的結果取出放在server端進行where篩選。
以上面的查詢為例,在沒有ICP時,首先通過索引字首從儲存引擎中讀出224條first_name為Mary的記錄,然後在server段用where篩選last_name的like條件;而啟用ICP後,由於last_name的like篩選可以通過索引欄位進行,那麼儲存引擎內部通過索引與where條件的對比來篩選掉不符合where條件的記錄,這個過程不需要讀出整條記錄,同時只返回給server篩選後的6條記錄,因此提高了查詢效能。
下面通過圖兩種查詢的原理詳細解釋。
關閉ICP
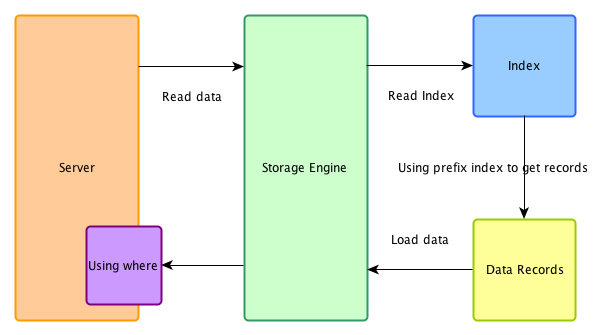
在不支援ICP的系統下,索引僅僅作為data access使用。
開啟ICP
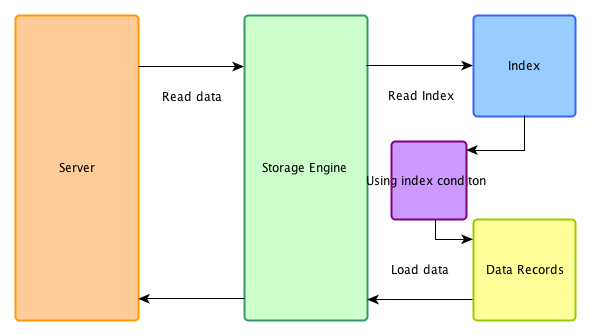
在ICP優化開啟時,在儲存引擎端首先用索引過濾可以過濾的where條件,然後再用索引做data access,被index condition過濾掉的資料不必讀取,也不會返回server端。
注意事項
有幾個關於ICP的事情要注意:
- ICP只能用於二級索引,不能用於主索引。
- 也不是全部where條件都可以用ICP篩選,如果某where條件的欄位不在索引中,當然還是要讀取整條記錄做篩選,在這種情況下,仍然要到server端做where篩選。
- ICP的加速效果取決於在儲存引擎內通過ICP篩選掉的資料的比例。
-
ICP的使用限制
1 當sql需要全表訪問時,ICP的優化策略可用於range, ref, eq_ref, ref_or_null 型別的訪問資料方法 。
2 支援InnoDB和MyISAM表。
3 ICP只能用於二級索引,不能用於主索引。
4 並非全部where條件都可以用ICP篩選。
如果where條件的欄位不在索引列中,還是要讀取整表的記錄到server端做where過濾。
5 ICP的加速效果取決於在儲存引擎內通過ICP篩選掉的資料的比例。
6 5.6 版本的不支援分表的ICP 功能,5.7 版本的開始支援。
7 當sql 使用覆蓋索引時,不支援ICP 優化方法。
參考
[1] https://mariadb.com/kb/en/index-condition-pushdown/
[2] http://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html