
Java開發中記憶體模型詳細解析

Java記憶體模型雖說是一個老生常談的問題 ,也是大廠面試中繞不過的,甚至初級面試也會問到。但是真正要理解起來,還是相當困難,主要這個東西看不見,摸不著。網上已經有大量的部落格,但是人家的終究是人家的,自己也要好好的去理解,去消化。今天我也來班門弄斧,說下Java記憶體模型。
說到Java記憶體模型,不得不說到 計算機硬體方面的知識。
計算機硬體體系
我們都知道CPU 和 記憶體是計算機中比較核心的兩個東西,它們之間會頻繁的互動,隨著CPU發展越來越快,記憶體的讀寫的速度遠遠不如CPU的處理速度,所以CPU廠商在CPU上加了一個 快取記憶體,用來緩解這種問題。我們在看CPU硬體引數的時候,也會看到有這樣的引數:
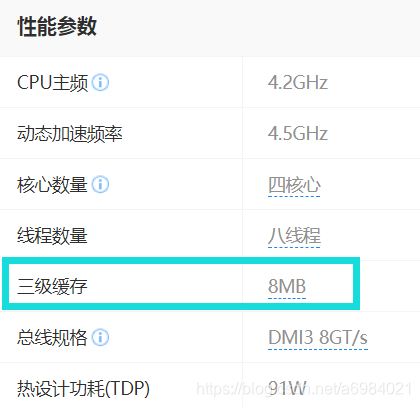
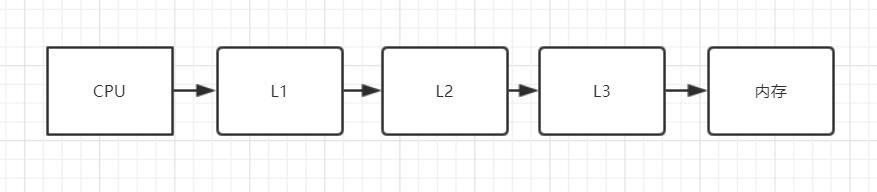
一般快取記憶體有3級:L1,L2,L3,CPU與記憶體的互動,就發生了變化,CPU不再與記憶體直接互動,CPU會先去L1中尋找資料,沒有的話,再去L2中尋找,然後是L3,最後才去記憶體尋找(更準確的來說,應該是CPU中的暫存器去尋找)。
我們可以畫一張圖來理解:
看起來一切都很美好,但是隨著科技的進步,CPU廠商們叒搞事了,推出了多核CPU,每個CPU上又有快取記憶體,CPU與記憶體的互動就變成了下面這個樣子:
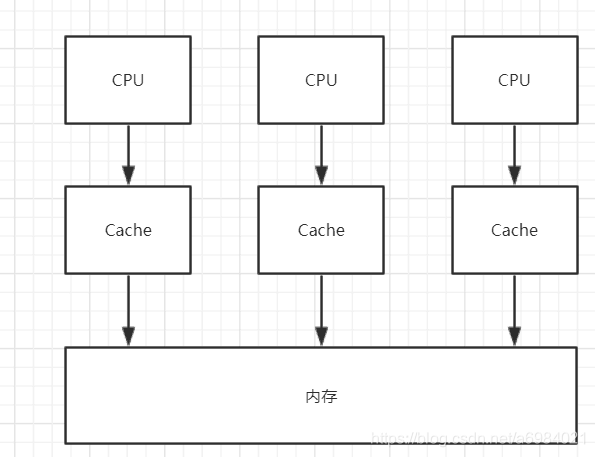
這樣就會引發一個問題:快取不一致。
為什麼會出現這個問題呢?
CPU需要修改某個資料,是先去Cache中找,如果Cache中沒有找到,會去記憶體中找,然後把資料複製到Cache中,下次就不需要再去記憶體中尋找了,然後進行修改操作。而修改操作的過程是這樣的:在Cache裡面修改資料,然後再把資料重新整理到主記憶體。其他CPU需要讀取資料,也是先去Cache中去尋找,如果找到了就不會去記憶體找了。
所以當兩個CPU的Cache同時都擁有某個資料,其中一個CPU修改了資料,另外一個CPU是無感知的,並不知道這個資料已經不是最新的了,它要讀取資料還是從自己的Cache中讀取,這樣就導致了“快取不一致”。
其實對於這樣的描述並不是十分準確,因為計算、讀取等操作都是在CPU的暫存器中進行的,這樣的描述是為了讓問題變得更簡單,相信學過計算機體系的人應該非常清楚整個流程,在這裡就簡單的描述下。
解決這個問題的方法有很多,比如:
匯流排加鎖(此方法效能較低,現在已經不會再使用)MESI協議
這是Intel提出的,MESI協議也是相當複雜,在這裡我就簡單的說下:當一個CPU修改了Cache中的資料,會通知其他快取了這個資料的CPU,其他CPU會把Cache中這份資料的Cache Line置為無效,要讀取資料的話,直接去記憶體中獲取,不會再從Cache中獲取了。
當然還有其他的解決方案,MESI協議是其中比較出名的。
Java執行緒與硬體處理器
其實,我們在Java中開啟一個執行緒,最終Java也會交給CPU去執行。
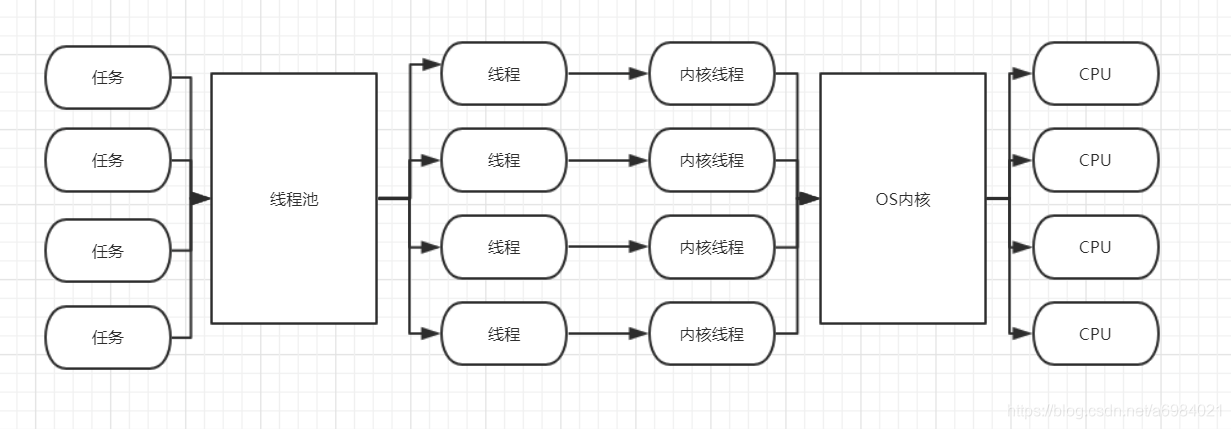
具體的流程是:我們在使用Java執行緒,內部會呼叫作業系統(OS)的核心執行緒(Kernel-Level Thread),這種執行緒是作業系統核心(Kernel)直接支援的,核心通過排程器,對執行緒進行排程,並將執行緒交給各個CPU核心去處理。
如下圖所示:
Java記憶體模型
看到標題,大家肯定會想:我靠,難道上面說的都和Java記憶體模型沒有關係嗎,從這裡才是真正介紹Java記憶體模型嗎?其實,並不是,Java記憶體模型是一個抽象的概念,其實並不存在,它描述的是一種規範,最終Java程式都會交給CPU去執行,所以上面是計算機硬體體系是基礎,有了上面的基礎,才有了Java記憶體模型,或者說Java的記憶體模型就是利用了計算機硬體體系。
還是從一張圖來入手:
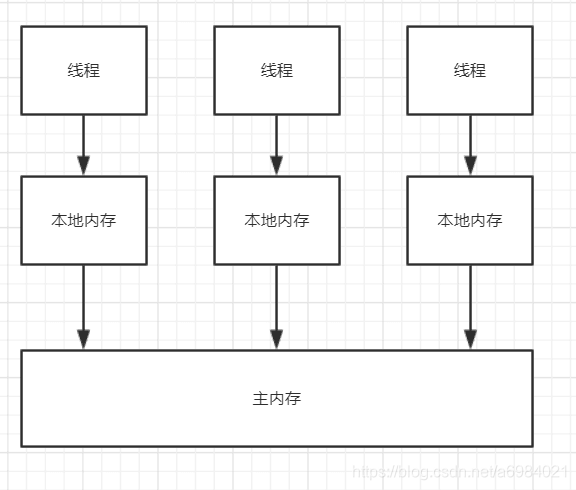
本地記憶體:存放的是 私有變數 和 主記憶體資料的副本。如果私有變數是基本資料型別,則直接存放在本地記憶體,如果是引用型別變數,存放的是引用(指標),實際的資料存放在主記憶體。本地記憶體是不共享的,只有屬於它的執行緒可以訪問。也有好多人把 本地記憶體 稱之為 執行緒棧 或者 工作空間。
主記憶體:存放的是共享的資料,所有執行緒都可以訪問。當然它也有不少其他稱呼,比如 堆記憶體,共享記憶體等等。
Java記憶體模型規定了所有對共享變數的讀寫操作都必須在本地記憶體中進行,需要先從主記憶體中拿到資料,複製到本地記憶體,然後在本地記憶體中對資料進行修改,再重新整理回主記憶體。
通過前面的鋪墊,我們應該認識到Java的執行最終還是會交給CPU去處理,但是Java的記憶體模型和硬體架構又不完全一致。對於硬體來說,只有CPU,Cache和主記憶體,並沒有Java記憶體模型中本地記憶體(執行緒棧、工作空間)或者主記憶體(共享記憶體,堆記憶體)的概念,所以不管是Java記憶體模型中的本地記憶體,還是主記憶體的資料,最終都會儲存在CPU(更準確的來說 是暫存器)、Cache、記憶體上。 所以,Java記憶體模型和計算機硬體架構存在這樣的關係:
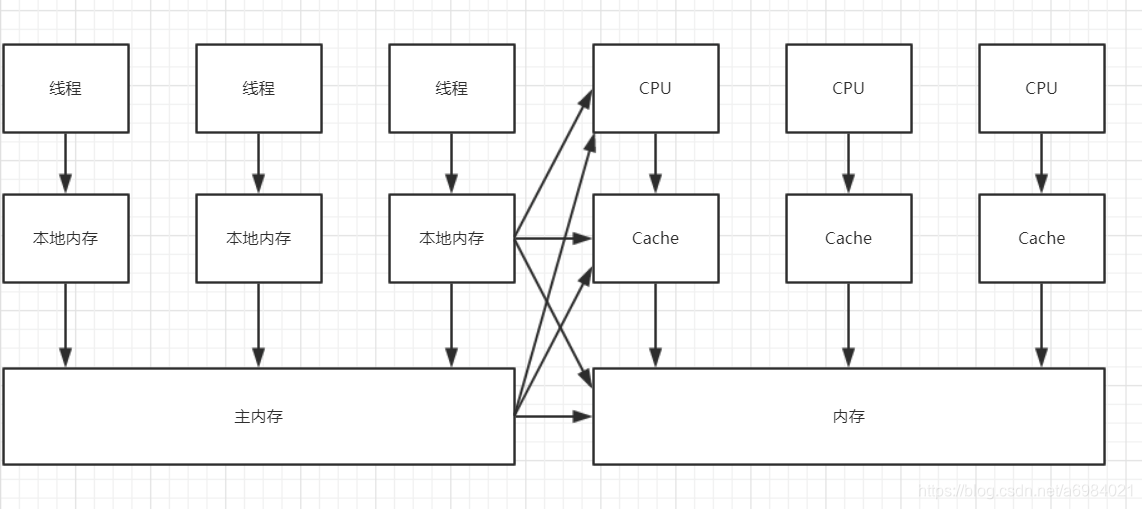
Java記憶體模型就是為了解決多執行緒對共享資料的讀寫一致性問題。
併發程式設計中三個重要特性
原子性:
不可分割,同生共死。
i=1
具有原子性,直接 在本地記憶體中進行賦值操作。
i++;
不具有原子性,有三個步驟
1.把i讀取出來(原子性)
2.在本地記憶體中做自增運算(原子性)
3.再把值寫回i(原子性)
多個原子性操作組合在一起,就不具有原子性了。
一般情況下,基本資料型別的賦值,讀取都是具有原子性的。
可見性
一個執行緒在本地記憶體中修改了共享記憶體的資料,對於其他持有該資料的執行緒是“不可見”的。
有序性
程式碼在執行的時候,執行順序可能並不是嚴格從上到下執行的,會進行指令重排。根據CPU流水線作業,一般來說 簡單的操作會先執行,複雜的操作後執行。
指令重排會有兩個規則:
as-if-seria
不管怎麼重排序,單執行緒的執行結果不能發生改變。正是由於這個特性,在單執行緒中,程式設計師一般無需理會重排序帶來的問題。
happens-before
程式次序規則
一段程式碼在單執行緒中執行的結果是有序的(感覺就是as-if-seria原則)volatile規則(以後會花一整節內容介紹,這裡不展開)鎖定規則如果鎖處於Lock的狀態,必須等Unlock後,才能再次進行Lock操作。
傳遞規則
A happens-before B , B happens-before C,那麼A happens-before C。
Java記憶體模型是個相當複雜的東西,在這裡只能說是“蜻蜓點水 ”般的介紹下。希望通過本文介紹,大家可以對Java模型有一個初步的瞭解。
文章來自:https://www.itjmd.com/news/show-4297.html