
java編寫WordCound的Spark程式,Scala編寫wordCound程式
1、建立一個maven專案,專案的相關資訊如下:
| <groupId>cn.toto.spark</groupId> <artifactId>bigdata</artifactId> <version>1.0-SNAPSHOT</version> |
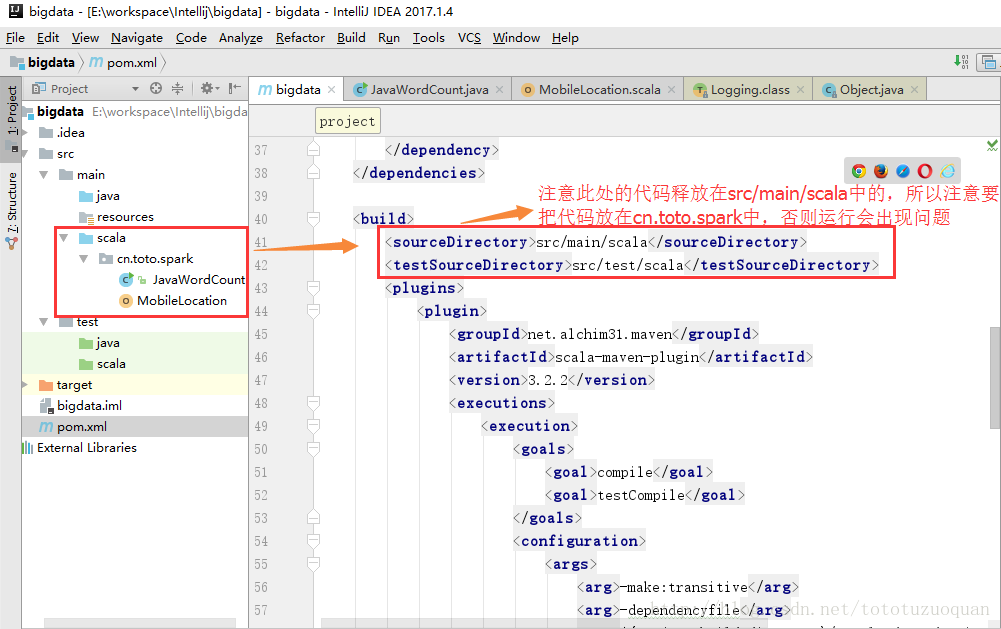
2、修改Maven倉庫的位置配置:
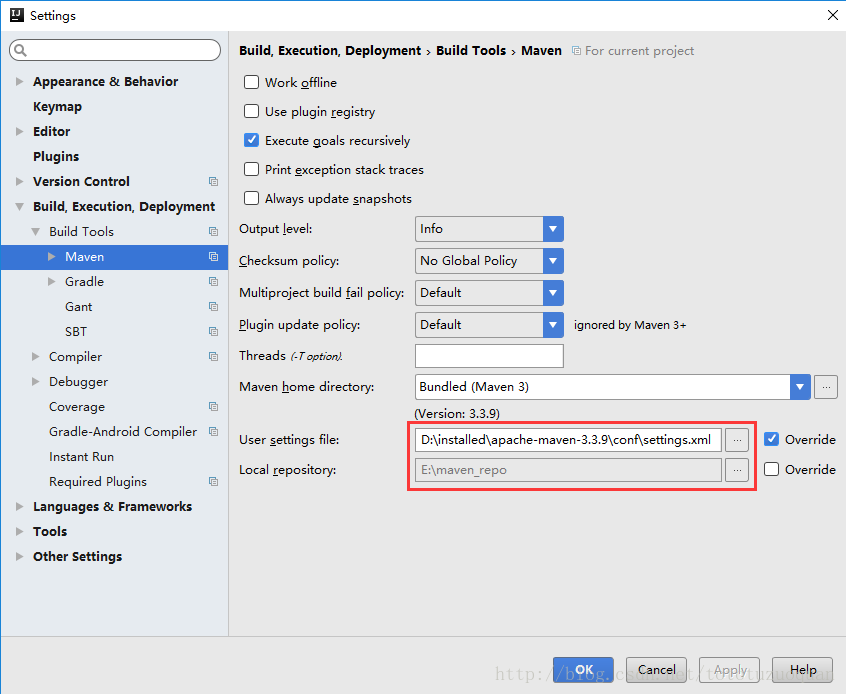
3、首先要編寫Maven的Pom檔案
| <?xml version="1.0" encoding="UTF-8"?> <groupId>cn.toto.spark</groupId> <properties> <dependencies> <dependency> <dependency> <build> <plugin> </project> |
4、編寫Java程式碼
| package cn.toto.spark; import org.apache.spark.SparkConf; import java.util.Arrays; /** public static void main(String[] args) { //儲存 |
5、準備資料
資料放置在E:\wordcount\input中:
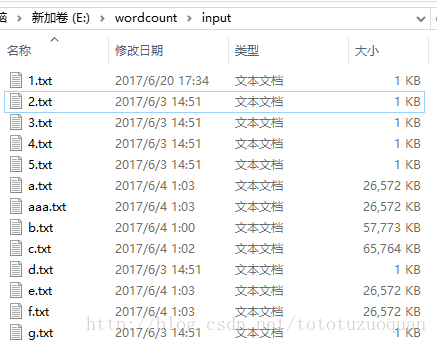
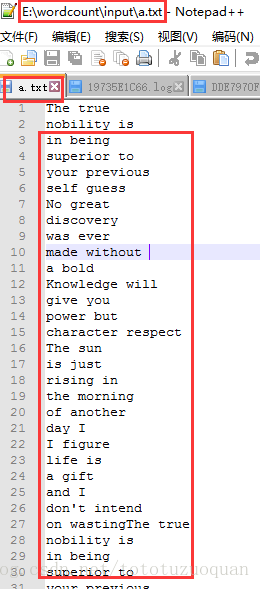
裡面的檔案內容是:
6、通過工具傳遞引數:
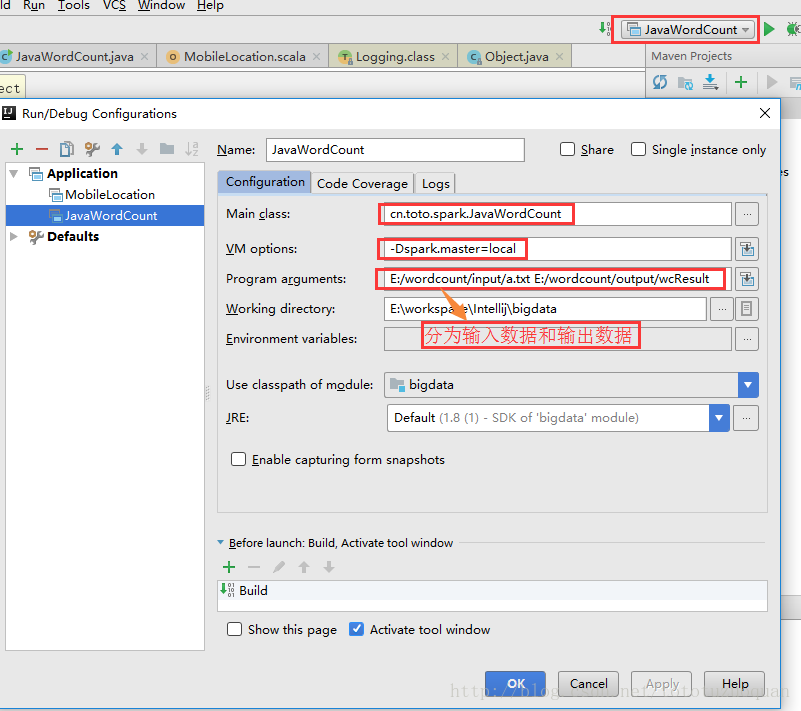
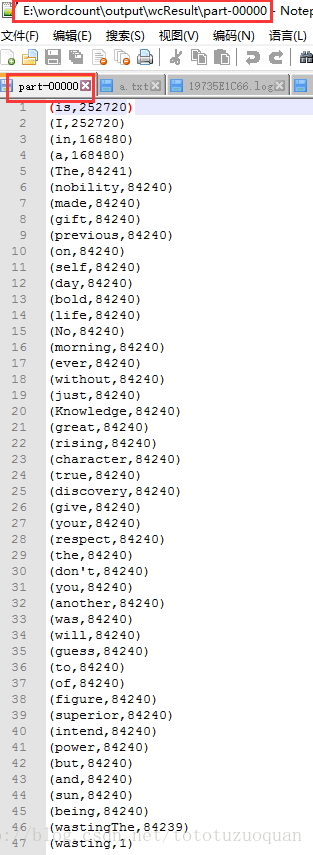
7、執行結果:
8、scala編寫wordCount
單詞統計的程式碼如下:
| import org.apache.spark.rdd.RDD /** def main(args: Array[String]) { val conf = new SparkConf().setAppName("ScalaWordCount") //textFile方法生成了兩個RDD: HadoopRDD[LongWritable, Text] -> MapPartitionRDD[String] //Map方法生成了一個MapPartitionRDD[(String, Int)] val counts: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_) val sortedCounts: RDD[(String, Int)] = counts.sortBy(_._2, false) } |