
圖解Java常用資料結構(一)\JDK原始碼分析(二)——LinkedList
最近在整理資料結構方面的知識, 系統化看了下Java中常用資料結構, 突發奇想用動畫來繪製資料流轉過程.
主要基於jdk8, 可能會有些特性與jdk7之前不相同, 例如LinkedList LinkedHashMap中的雙向列表不再是迴環的.
HashMap中的單鏈表是尾插, 而不是頭插入等等, 後文不再贅敘這些差異, 本文目錄結構如下:

LinkedList
經典的雙鏈表結構, 適用於亂序插入, 刪除. 指定序列操作則效能不如ArrayList, 這也是其資料結構決定的.
add(E) / addLast(E)

add(index, E)
這邊有個小的優化, 他會先判斷index是靠近隊頭還是隊尾, 來確定從哪個方向遍歷鏈入.

1 if (index < (size >> 1)) { 2 Node<E> x = first; 3 for (int i = 0; i < index; i++) 4 x = x.next; 5 return x; 6 } else { 7 Node<E> x = last; 8 for (int i = size - 1; i > index; i--) 9 x = x.prev; 10 return x; 11 }

靠隊尾

get(index)
也是會先判斷index, 不過效能依然不好, 這也是為什麼不推薦用for(int i = 0; i < lengh; i++)的方式遍歷linkedlist, 而是使用iterator的方式遍歷.


remove(E)

ArrayList
底層就是一個數組, 因此按序查詢快, 亂序插入, 刪除因為涉及到後面元素移位所以效能慢.
add(index, E)

擴容
一般預設容量是10, 擴容後, 會length*1.5.

remove(E)
迴圈遍歷陣列, 判斷E是否equals當前元素, 刪除效能不如LinkedList.

Stack
經典的資料結構, 底層也是陣列, 繼承自Vector, 先進後出FILO, 預設new Stack()容量為10, 超出自動擴容.
push(E)

pop()

字尾表示式
Stack的一個典型應用就是計算表示式如 9 + (3 - 1) * 3 + 10 / 2, 計算機將中綴表示式轉為字尾表示式, 再對字尾表示式進行計算.
中綴轉字尾
- 數字直接輸出
- 棧為空時,遇到運算子,直接入棧
- 遇到左括號, 將其入棧
- 遇到右括號, 執行出棧操作,並將出棧的元素輸出,直到彈出棧的是左括號,左括號不輸出。
- 遇到運算子(加減乘除):彈出所有優先順序大於或者等於該運算子的棧頂元素,然後將該運算子入棧
- 最終將棧中的元素依次出棧,輸出。

計算字尾表達
- 遇到數字時,將數字壓入堆疊
- 遇到運算子時,彈出棧頂的兩個數,用運算子對它們做相應的計算, 並將結果入棧
- 重複上述過程直到表示式最右端
- 運算得出的值即為表示式的結果

佇列
與Stack的區別在於, Stack的刪除與新增都在隊尾進行, 而Queue刪除在隊頭, 新增在隊尾.
ArrayBlockingQueue
生產消費者中常用的阻塞有界佇列, FIFO.
put(E)

put(E) 佇列滿了
1 final ReentrantLock lock = this.lock;
2 lock.lockInterruptibly();
3 try {
4 while (count == items.length)
5 notFull.await();
6 enqueue(e);
7 } finally {
8 lock.unlock();
9 }

take()
當元素被取出後, 並沒有對陣列後面的元素位移, 而是更新takeIndex來指向下一個元素.
takeIndex是一個環形的增長, 當移動到佇列尾部時, 會指向0, 再次迴圈.
1 private E dequeue() {
2 // assert lock.getHoldCount() == 1;
3 // assert items[takeIndex] != null;
4 final Object[] items = this.items;
5 @SuppressWarnings("unchecked")
6 E x = (E) items[takeIndex];
7 items[takeIndex] = null;
8 if (++takeIndex == items.length)
9 takeIndex = 0;
10 count--;
11 if (itrs != null)
12 itrs.elementDequeued();
13 notFull.signal();
14 return x;
15 }

HashMap
最常用的雜湊表, 面試的童鞋必備知識了, 內部通過陣列 + 單鏈表的方式實現. jdk8中引入了紅黑樹對長度 > 8的連結串列進行優化, 我們另外篇幅再講.
put(K, V)

put(K, V) 相同hash值

resize 動態擴容
當map中元素超出設定的閾值後, 會進行resize (length * 2)操作, 擴容過程中對元素一通操作, 並放置到新的位置.
具體操作如下:
- 在jdk7中對所有元素直接rehash, 並放到新的位置.
- 在jdk8中判斷元素原hash值新增的bit位是0還是1, 0則索引不變, 1則索引變成"原索引 + oldTable.length".
1 //定義兩條鏈
2 //原來的hash值新增的bit為0的鏈,頭部和尾部
3 Node<K,V> loHead = null, loTail = null;
4 //原來的hash值新增的bit為1的鏈,頭部和尾部
5 Node<K,V> hiHead = null, hiTail = null;
6 Node<K,V> next;
7 //迴圈遍歷出鏈條鏈
8 do {
9 next = e.next;
10 if ((e.hash & oldCap) == 0) {
11 if (loTail == null)
12 loHead = e;
13 else
14 loTail.next = e;
15 loTail = e;
16 }
17 else {
18 if (hiTail == null)
19 hiHead = e;
20 else
21 hiTail.next = e;
22 hiTail = e;
23 }
24 } while ((e = next) != null);
25 //擴容前後位置不變的鏈
26 if (loTail != null) {
27 loTail.next = null;
28 newTab[j] = loHead;
29 }
30 //擴容後位置加上原陣列長度的鏈
31 if (hiTail != null) {
32 hiTail.next = null;
33 newTab[j + oldCap] = hiHead;
34 }

LinkedHashMap
繼承自HashMap, 底層額外維護了一個雙向連結串列來維持資料有序. 可以通過設定accessOrder來實現FIFO(插入有序)或者LRU(訪問有序)快取.
put(K, V)

get(K)
accessOrder為false的時候, 直接返回元素就行了, 不需要調整位置.
accessOrder為true的時候, 需要將最近訪問的元素, 放置到隊尾.

removeEldestEntry 刪除最老的元素

===============================
目錄
LinkedList
JDK api對LinkedList的介紹:
Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
大意是LinkedList基於雙向連結串列實現了List介面和Deque(double ended queue 雙向佇列)介面,允許插入任意物件,包括Null。LinkedList是一個在平常開發中經常使用的類,由於它是基於連結串列實現的,插入刪除相對於ArrayList需要考慮動態擴容,複製原陣列到新陣列來說,非常簡單。它實現了Deque介面,在我們需要進行先進先出FIFO操作時非常方便。
LinkedList繼承結構
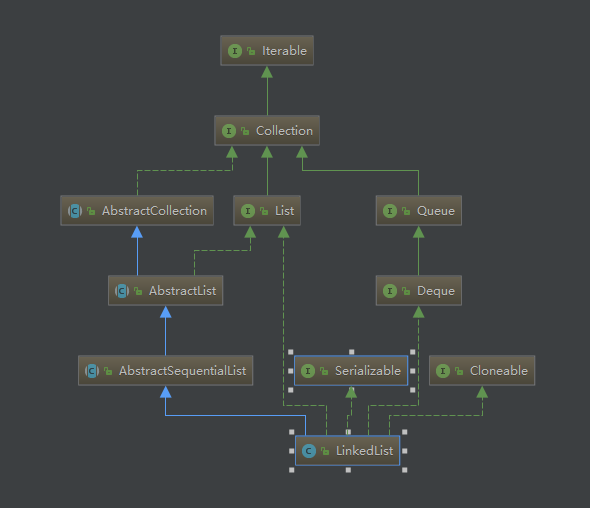
LinkedList 是一個繼承於AbstractSequentialList的雙向連結串列,AbstractSequentialList 提供了一套基於順序訪問的介面。通過繼承此類,子類僅需實現部分程式碼即可擁有完整的一套訪問某種序列表(比如連結串列)的介面。實現了List介面,實現了Deque,Queue介面,能夠進行佇列先進先出FIFO操作。
LinkedList內部類Node
內部類Node實現雙向連結串列的基礎。
private static class Node<E> {
//資料域
E item;
//指向下一個節點
Node<E> next;
//指向上一個節點
Node<E> prev;
//構造方法
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}LinkedList成員屬性
//表示連結串列的長度
transient int size = 0;
//連結串列的第一個節點
transient Node<E> first;
//連結串列的最後一個節點
transient Node<E> last;LinkedList構造方法
無參構造方法
提供的無參構造方法是一個空方法,即size為0,first,last為null。因為LinkedList是連結串列結構,不必要像ArrayList去初始化底層陣列。
public LinkedList() {
}有參構造方法
首先呼叫無參構造方法,再呼叫addAll方法,在後面詳細介紹這個方法。
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}重要方法
add(E e)
add方法主要呼叫了linkLast方法,也就是從連結串列尾部插入元素,首先新建一個節點,它的前一個節點是連結串列的尾部節點,下一個節點為空,再將last指向這個新插入的節點,如果之前的last不為空(即連結串列不是第一次插入元素),我們把之前的last節點的next指向現在的last節點,如果為空,說明我們是第一次插入元素,之前的first,last都為null,那我們就把first也只想新插入的節點。下圖展示了連結串列的結構和插入過程: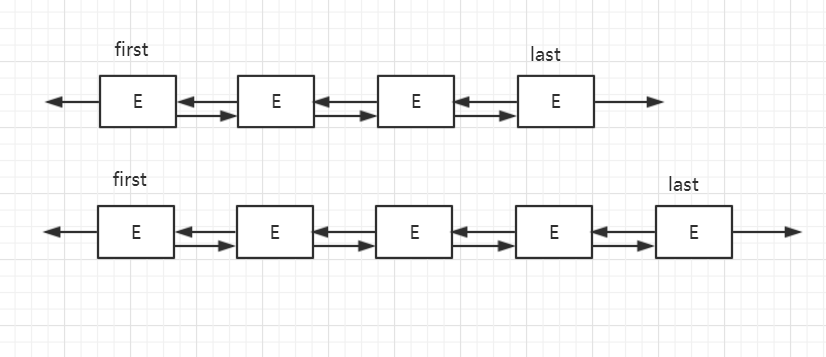

public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}add(int index, E element)
把新元素插入連結串列指定索引位置index處。首先檢查待插入位置index是否合法(0<=index<=size),如果index不合法,丟擲異常。index在範圍內,若index等於size,就表示要把這個新元素插入到LinkedList的末尾,呼叫linkLast方法;否則,說明要把這個新元素插入到LinkedList的中間,呼叫linkBefore方法,把元素插入到指定節點的前面,需要傳入兩個引數:插入資料e,節點,我們使用node(int index)找到這個節點,作為傳入引數,linkBefore具體註釋在程式碼裡。
由此可以看出,LinkedList插入元素相對簡單,只需要找到插入元素的位置並改變指向前一個節點和指向後一個節點,就能夠順利的插入元素,這是由於連結串列的特性決定的。
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//找到succ的上一個節點
final Node<E> pred = succ.prev;
//新節點插入到前繼節點pred,後繼節點succ之間
final Node<E> newNode = new Node<>(pred, e, succ);
//後繼節點的prev指向新節點
succ.prev = newNode;
//前繼節點pred為空,則新節點作為首節點first,否則把前一個節點的next指向新節點
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
Node<E> node(int index) {
// assert isElementIndex(index);
//如果index<size/2,從前半部分找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}addAll(Collection<? extends E> c)
LinkedList的有參構造方法呼叫了addAll(Collection<? extends E> c)方法,將一個集合物件儲存的元素插入到LinkedList的末尾。首先呼叫toArray方法將集合物件轉換為陣列,再找到插入位置的前繼節點pred和後繼節點succ,然後把陣列中的元素依次連線到連結串列上去。
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
//Collection物件轉換為Object陣列
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
//pred插入位置的前繼節點,succ插入位置
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
//將陣列元素連線到連結串列上,每次通過節點Node構造方法指定前繼節點
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
//根據succ插入位置節點是否為空確定for迴圈最後一個元素的後繼節點
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}get(int index)
通過索引找到這個位置節點,返回這個節點儲存的資料。首先檢查元素索引是否合法(注意與插入位置索引的範圍區別,插入元素可以到size,作為最後一個元素,查詢元素最大隻能到size-1),索引合法,通過node(int index)方法找到這個元素。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}set(int index, E element)
將指定索引位置處節點儲存的值設定為新的傳入的資料,並返回儲存的老的資料。set方法的實現其實就比get方法多一步:把原來的資料替換為新的資料。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}remove(int index)
根據索引找到對應位置的節點,將節點移除,返回移除節點的資料。首先通過checkElementIndex檢查傳入的索引是否合法,索引在範圍內,呼叫node(int index)找到這個節點,呼叫unlink移除這個節點,首先儲存待移除節點x的下一個節點next,上一個節點prev,如果prev為空,說明待移除的節點是首節點,那麼移除了這個節點,下一個節點就是首節點;prev不為空,將prev的next指向next節點,待移除節點x的prev置為空。如果next為空,說明待移除節點是末尾節點,那麼移除了這個節點,上一個節點prev就是末尾節點了;若不為空,把next的prev指向prev節點,同時把待移除節點的next置為空。
移除節點主要分為兩部,把待移除節點的前後兩個節點相互連線起來,把節點從連結串列移除;把待移除節點的prev,next置為空,和連結串列斷除聯絡。正好是插入的逆過程。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}Deque方法的實現
offer(E e)
Deque介面繼承了Queue介面,LinkedList實現了佇列先進先出的特性,offer方法將元素插入到佇列,呼叫了linkLast方法。
public boolean offer(E e) {
return add(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}poll()
從佇列中取出元素,佇列中取元素肯定是從佇列的頭部取元素,並返回節點儲存的值。(f == null) ? null : unlinkFirst(f)三目表示式判斷首節點是否為空,若為空直接返回null,不為空,呼叫unlinkFirst方法。通過呼叫unlinkFirst方法移除首節點。
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
//儲存首節點的下一個節點next
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
//next為空,那麼總共只有一個節點,直接令last為空,不為空的話next就是首節點,把它的prev指向null
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}remove()
從佇列中取出元素,這個方法與poll方法唯一的差別是首節點是空的話remove方法會拋異常,poll方法不會。JDK的解釋:Retrieves and removes the head of this queue. This method differs from poll only in that it throws an exception if this queue is empty.從佇列取出元素還是建議用poll方法。
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}peek()
返回佇列首節點儲存的值,不從佇列中移除首節點。只通過一個三目運算子就實現了功能。
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}push(E e)
Deque介面代表著雙端佇列,那麼意味著也能從隊首插入元素,隊尾取出元素。push方法表示將這個LinkedList作為一個先進後出的棧Stack使用。從棧的頂部插入元素,也就是從list的頭部插入元素,呼叫了linkFirst方法。
public void push(E e) {
addFirst(e);
}
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
//新元素作為首節點
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}pop()
pop方法表示將這個LinkedList作為一個先進後出的棧Stack使用。從棧的頂部取出元素,呼叫了removeFirst方法。
public E pop() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}遍歷
listIterator()
通過iterator或listIterator方法返回一個ListIterator迭代器,迭代器是通過一個內部類ListItr實現ListIterator介面實現的。
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}ListItr內部類
使用foreach遍歷最終是通過迭代器來進行遍歷的,由於LinkedList是執行緒不安全的,所以迭代時通過比較modCount值是否改變來判斷是否有其他執行緒在使用LinkedList。
private class ListItr implements ListIterator<E> {
//上一個迭代元素
private Node<E> lastReturned;
//下一個要迭代的元素
private Node<E> next;
//下一個迭代元素的下標
private int nextIndex;
private int expectedModCount = modCount;
//呼叫iterator方法預設index為零,從頭開始遍歷
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
//判斷是否還有沒有遍歷完的元素,比較下一個元素的下標與size的大小關係
public boolean hasNext() {
return nextIndex < size;
}
//把lastReturned,next依次向後移,並返回之前next指向元素儲存的資料
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
//與next配合使用
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
//比較是否有多個執行緒操作LinkedList,確保fail-fast機制
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}總結
LinkedList是基於雙向連結串列實現的List,適用於頻繁增加、刪除元素的場景,LinkedList不是執行緒安全的,在多執行緒環境下不能
正常的使用。LinkedList的原始碼總體上分析比較簡單,但是LinkedList的功能很多的,能做普通的List使用,LinkedList實現了雙向佇列Deque,也可以做先入先出的佇列或先入後出的棧使用。