
scan演算法進行磁碟排程
阿新 • • 發佈:2018-12-26
要求:


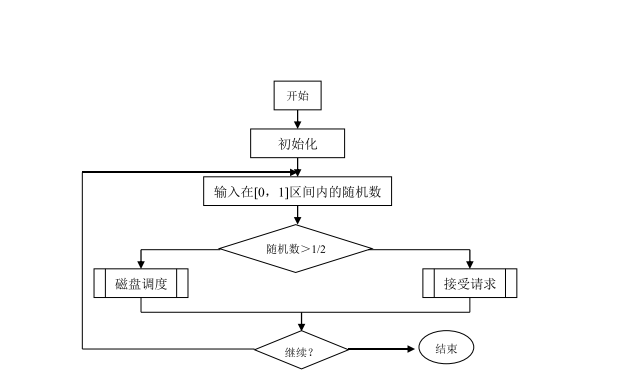
兩種實現方式:
1,使用陣列儲存請求佇列:
#include<cstdio> #include<stdlib.h> #include<time.h> using namespace std; const int N = 500; //設定得大點,防止溢位 const int MIN = 10000; //設定得大於最大磁軌號即可 struct process{ //請求程序的結構 int name; int track; }; process p_queue[N]; // 請求佇列 void ask(int n) { //請求 process temp; temp.name = rand() % 50000; //隨機生成程序名 但是有出現同名請求的風險 temp.track = rand() / 200; //隨機生成請求磁軌 printf("建立請求:id: %d track: %d\n\n", temp.name, temp.track); p_queue[n] = temp; //將隨機生成的請求加入請求佇列 } void print_IO(int track, int dire, process p, int n) { //列印請求IO表, 當前磁軌號,移臂方向,被選中的程序名和其要求的磁軌printf("處理請求===當前請求IO表:\n"); printf("程序名\t請求磁軌\n"); for(int i = 0; i < n; i++) { if(p_queue[i].name!= -1) printf("%d\t%d\n", p_queue[i].name, p_queue[i].track); } printf("當前磁軌號: %d\t臂方向: %d\n", track, dire); printf("被選中的程序名: %d\t要求的磁軌號: %d\n\n", p.name, p.track); }void scheduling(int *dire, int *track, int n) { //處理 int trackName = 0, min = MIN; while(min == MIN) { //scan演算法 if(*dire == 0) { for(int i = 0; i < n; i++) if(p_queue[i].name != -1 && p_queue[i].track > *track && p_queue[i].track - *track < min) { trackName = p_queue[i].name; min = p_queue[i].track - *track; } } else { for(int i = 0; i < n; i++) if(p_queue[i].name != -1 && p_queue[i].track < *track && *track - p_queue[i].track < min) { trackName = p_queue[i].name; min = *track - p_queue[i].track; } } if(min == MIN) *dire = ((*dire) == 0 ? 1 : 0); //如果到達了一端頂點, 磁臂反向 } for(int k = 0; k < n; k++) { if(p_queue[k].name == trackName) { print_IO(*track, *dire, p_queue[k], n); //列印請求資訊 *track = p_queue[k].track; //更新track(當前磁軌) p_queue[k].name = -1; //將程序名設為-1即代表登出程序,但是實際上登出程序仍然在請求佇列中,只是通過判斷條件使其對程式不可見 break; } } } // dire表示磁頭運動方向 0:由 0 -> 199 1: 由 199 -> 0 // track表示磁頭當前所在磁軌 int main() { int dire, track, n = 0, remain = 0; //當前方向,磁軌, 總請求數目, 未處理的請求 srand((unsigned int)time(NULL)); //隨機生成初始方向和磁軌 dire = rand() % 2; track = rand() % 200; printf("初始化: dire: %d track: %d\n", dire, track); //初始化5個請求 for(int i = 0; i < 5; i++) { ask(n++); remain++; } while(remain > 0) { int k = rand() % 3; //通過調節K值,調節產生兩種程序的機率 if(k == 1 || k == 2) { //處理一個請求 scheduling(&dire, &track, n); remain--; } else { //產生一個請求 ask(n++); remain++; } } printf("請求佇列已完成\n"); return 0; }
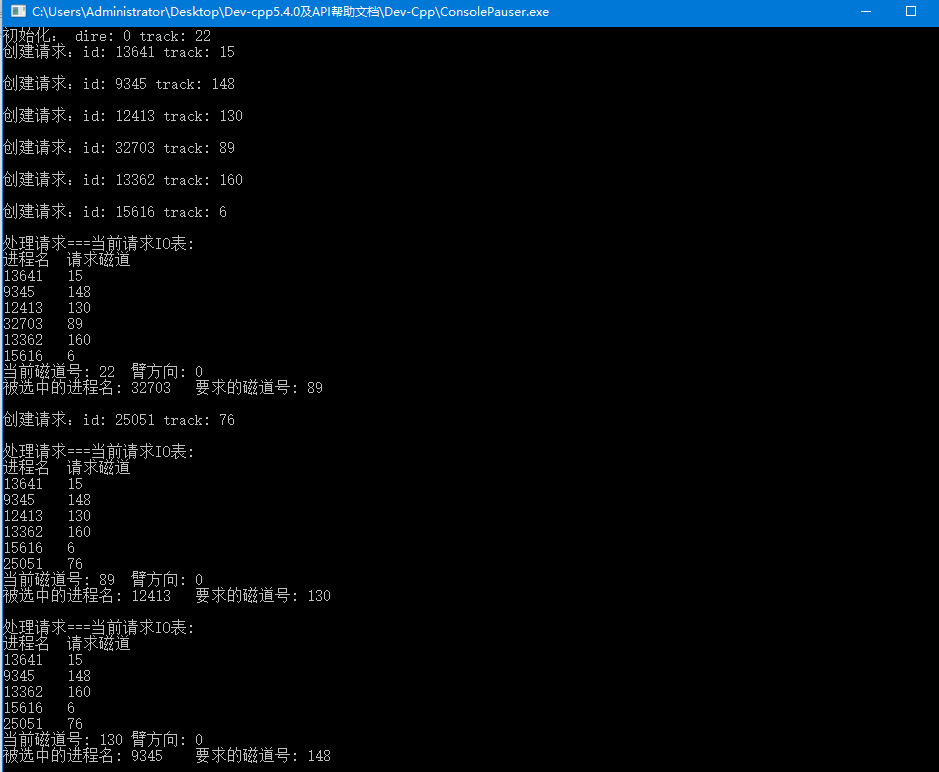
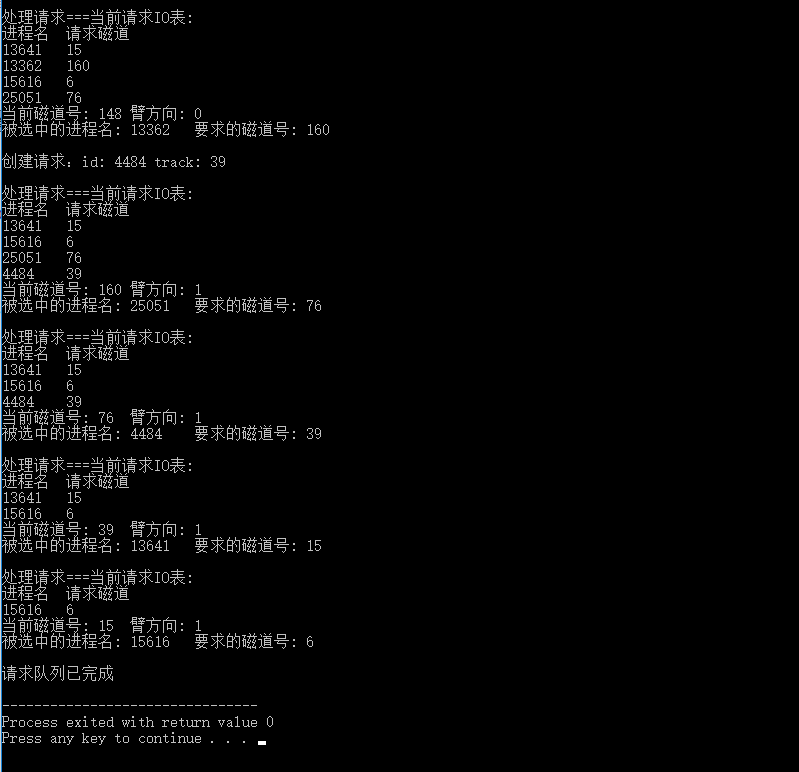
2:使用可變長陣列儲存請求佇列:
#include<iostream> #include<cstdio> #include<stdlib.h> #include<time.h> #include<vector> using namespace std; const int N = 1000; struct request{ int id; int reqTrack; }; vector<request> req; void init(int *dire, int *track) { *dire = rand() % 2; *track = rand() % 200; } void schedAsk(){ //隨機生成一個排程請求 request temp; temp.id = rand() % 10000; temp.reqTrack = rand() / 200; printf("建立請求:id: %d track: %d\n", temp.id, temp.reqTrack); req.push_back(temp); } /* // 不考慮id重複的情況 // 考慮方向問題(未解決) */ void diskSchedu(int *dire, int *track) { int need, n = req.size(), min = N; while(min == N) { //scan演算法 if(*dire == 0) { for(int i = 0; i < n; i++) if(req[i].reqTrack > *track && req[i].reqTrack - *track < min) { need = req[i].id; min = req[i].reqTrack - *track; } } else { for(int i = 0; i < n; i++) if(req[i].reqTrack < *track && *track - req[i].reqTrack < min) { need = req[i].id; min = *track - req[i].reqTrack; } } if(min == N) *dire = ((*dire) == 0 ? 1 : 0); //如果到達了一端頂點, 磁臂反向 } vector<request>::iterator it; for(it = req.begin(); it != req.end();) { if((*it).id == need) { *track = (*it).reqTrack; //更新track printf("磁碟排程:id: %d track: %d dire: %d\n", (*it).id, (*it).reqTrack, *dire); it = req.erase(it); break; } else it++; } } /* // dire表示磁頭運動方向 0:由 0 -> 199 1: 由 199 -> 0 // track表示磁頭當前所在磁軌 // k = 1 執行磁碟排程 k= 2 執行接收請求 */ int main() { srand((unsigned int)time(NULL)); int dire, track, n = 2; init(&dire, &track); printf("初始化: dire: %d track: %d\n", dire, track); for(int i = 0; i < n; i++) { //預先放置5個請求 schedAsk(); } printf("===========初始化結束========\n"); while(req.size() != 0) { int k = rand() % 3; //通過調節K值,調節產生兩種程序的機率 if(k == 1 || k == 2) diskSchedu(&dire, &track); else { schedAsk(); } } if(req.size() == 0) cout << "已處理所有請求\n"; return 0; }
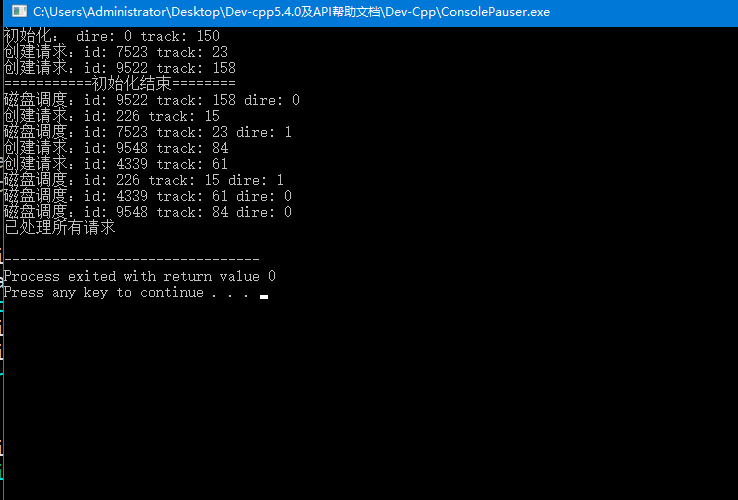
第二個程式的輸出就寫簡單點了,主要是懶。。。。
本質上兩個程式是一樣的。