
CUDA系列學習(五)GPU基礎演算法: Reduce, Scan, Histogram
———-
1. Task complexity
task complexity包括step complexity(可以並行成幾個操作) & work complexity(總共有多少個工作要做)。
e.g. 下面的tree-structure圖中每個節點表示一個運算元,每條邊表示一個操作,同層edge表示相同操作,問該圖表示的task的step complexity & work complexity分別是多少。
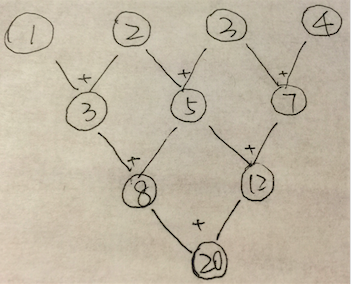
Ans:
step complexity: 3;
work complexity: 6。
下面會有更具體的例子。
2. Reduce
引入:我們考慮一個task:1+2+3+4+…
1) 最簡單的順序執行順序組織為((1+2)+3)+4…
2) 由於operation之間沒有依賴關係,我們可以用Reduce簡化操作,它可以減少serial implementation的步數。
2.1 what is reduce?
Reduce input:
- set of elements
- reduction operation
- binary: 兩個輸入一個輸出
- 操作滿足結合律: ([email protected])@c = [email protected]([email protected]), 其中@表示operator
e.g +, 按位與 都符合;a^b(expotentiation)和減法都不是
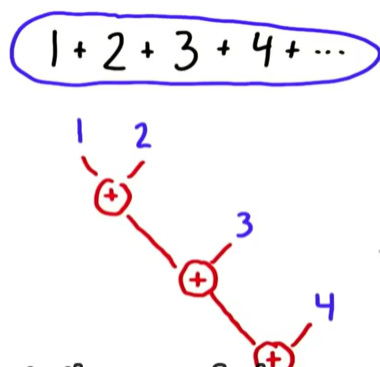
2.1.1 Serial implementation of Reduce:
reduce的每一步操作都依賴於其前一個操作的結果。比如對於前面那個例子,n個數相加,work complexity 和 step complexity都是O(n)(原因不言自明吧~)我們的目標就是並行化操作,降下來step complexity. e.g add serial reduce -> parallel reduce。
2.1.2 Parallel implementation of Reduce:
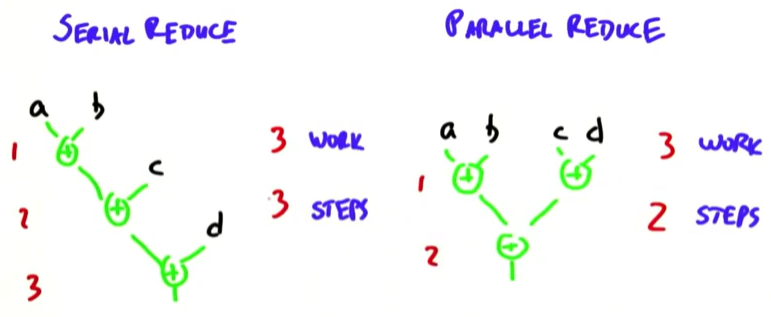
也就是說,我們把step complexity降到了
舉個栗子,如下圖所示:

那麼如果對

也就是進行兩步操作,第一步分成1024個block,每個block做加法;第二步將這1024個結果再用1個1024個thread的block進行求和。kernel code:
__global__ void parallel_reduce_kernel(float *d_out, float* d_in){
int myID = threadIdx.x + blockIdx.x * blockDim.x;
int tid = threadIdx.x;
//divide threads into two parts according to threadID, and add the right part to the left one, lead to reducing half elements, called an iteration; iterate until left only one element
for(unsigned int s = blockDim.x / 2 ; s>0; s>>=1){
if(tid<s){
d_in[myID] += d_in[myID + s];
}
__syncthreads(); //ensure all adds at one iteration are done
}
if (tid == 0){
d_out[blockIdx.x] = d_in[myId];
}
}Quiz: 看一下上面的code可以從哪裡進行優化?
Ans:我們在上一講中提到了global,shared & local memory的速度,那麼這裡對於global memory的操作可以更改為shared memory,從而進行提速:
__global__ void parallel_shared_reduce_kernel(float *d_out, float* d_in){
int myID = threadIdx.x + blockIdx.x * blockDim.x;
int tid = threadIdx.x;
extern __shared__ float sdata[];
sdata[tid] = d_in[myID];
__syncthreads();
//divide threads into two parts according to threadID, and add the right part to the left one, lead to reducing half elements, called an iteration; iterate until left only one element
for(unsigned int s = blockDim.x / 2 ; s>0; s>>=1){
if(tid<s){
sdata[tid] += sdata[tid + s];
}
__syncthreads(); //ensure all adds at one iteration are done
}
if (tid == 0){
d_out[blockIdx.x] = sdata[myId];
}
}
優化的程式碼中還有一點要注意,就是宣告的時候記得我們第三講中說過的kernel通用表示形式:
kernel<<<grid of blocks, block of threads, shmem>>>parallel_reduce_kernel<<<blocks, threads, threads*sizeof(float)>>>(data_out, data_in);好,那麼問題來了,對於這兩個版本(parallel_reduce_kernel 和 parallel_shared_reduce_kernel), parallel_reduce_kernel比parallel_shared_reduce_kernel多用了幾倍的global memory頻寬? Ans: 分別考慮兩個版本的讀寫操作:
parallel_reduce_kernel| Times | Read Ops | Write Ops |
| 1 | 1024 | 512 |
| 2 | 512 | 256 |
| 3 | 256 | 128 |
| … | ||
| n | 1 | 1 |
parallel_shared_reduce_kernel| Times | Read Ops | Write Ops |
| 1 | 1024 | 1 |
所以,parallel_reduce_kernel所需的頻寬是parallel_shared_reduce_kernel的3倍。
3. Scan
3.1 what is scan?
Example:
- input: 1,2,3,4
- operation: Add
- ouput: 1,3,6,10(out[i]=sum(in[0:i]))
目的:解決難以並行的問題
拍拍腦袋想想上面這個問題O(n)的一個解法是out[i] = out[i-1] + in[i].下面我們來引入scan。
Inputs to scan:
- input array
- 操作:binary & 滿足結合律(和reduce一樣)
- identity element [I op a = a], 其中I 是identity element
quiz: what is the identity for 加法,乘法,邏輯與,邏輯或?
Ans:
| op | Identity |
| 加法 | 0 |
| 乘法 | 1 |
| 邏輯或|| | False |
| 邏輯與&& | True |
3.2 what scan does?
| I/O | content | ||||
|---|---|---|---|---|---|
| input | [ |
… | |||
| output | [ |
… |
其中
3.2.1 Serial implementation of Scan
很簡單:
int acc = identity;
for(i=0;i<elements.length();i++){
acc = acc op elements[i];
out[i] = acc;
}work complexity:
step complexity:
那麼,對於scan問題,我們怎樣對其進行並行化呢?
3.2.1 Parallel implementation of Scan
考慮scan的並行化,可以平行計算n個output,每個output元素i相當於
Q: 那麼問題的work complexity和step complexity分別變為多少了呢?
Ans:
- step complexity:
取決於n個reduction中耗時最長的,即O(log2n) - work complexity:
對於每個output元素進行計算,總計算量為0+1+2+…+(n-1),所以複雜度為O(n2) .
可見,step complexity降下來了,可惜work complexity上去了,那麼怎麼解決呢?這裡有兩種Scan演算法:
| more step efficiency | more work efficiency |
| hillis + steele (1986) | √ |
| blelloch (1990) | √ |
- Hillis + Steele
對於Scan加法問題,hillis+steele演算法的解決方案如下:
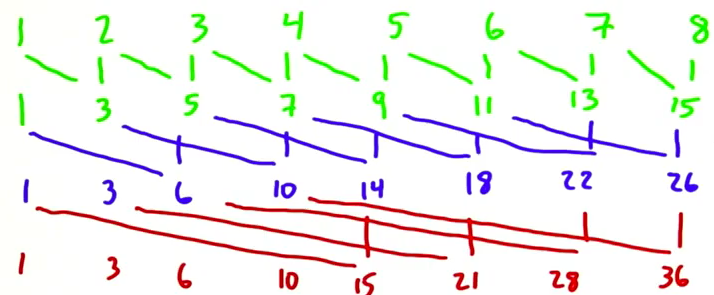
即streaming’s
step 0: out[i] = in[i] + in[i-1];
step 1: out[i] = in[i] + in[i-2];
step 2: out[i] = in[i] + in[i-4];
如果元素不存在(向下越界)就記為0;可見step 2的output就是scan 加法的結果(想想為什麼,我們一會再分析)。
那麼問題來了。。。
Q: hillis + steele演算法的work complexity 和 step complexity分別為多少?
| O(n^2) | ||||
| work complexity | √ | |||
| step complexity | √ |
解釋:
為了不妨礙大家思路,我在表格中將答案設為了白色,選中表格可見答案。
- step complexity:
因為第i個step的結果為上一步輸出作為in, out[idx] = in[idx] + in[idx - 2^i], 所以step complexity =O(log(n)) - work complexity:
workload =(n−1)+(n−2)+(n−4)+... ,共有log(n) 項元素相加,所以可以近似看做一個矩陣,對應上圖,長log(n) , 寬n,所以複雜度為nlog(n) 。
2 .Blelloch
基本思路:Reduce + downsweep
還是先講做法。我們來看Blelloch演算法的具體流程,分為reduce和downsweep 兩部分,如圖所示。
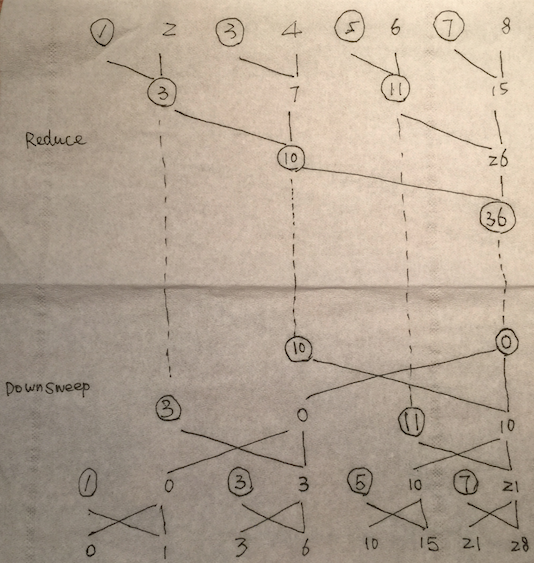
reduce部分:
每個step對相鄰兩個元素進行求和,但是每個元素在input中只出現一次,即window size=2, step = 2的求和。
Q: reduce部分的step complexity 和 work complexity?
Ans:Reduce part in Blelloch log(n) O(n‾‾√) O(n) O(nlogn) O(n^2) work complexity √ step complexity √ 我們依然將答案用白色標出,請選中看答案。
downsweep部分:
簡單地說,downsweep部分的輸入元素是reduce部分鏡面反射的結果,對於每一組輸入in1 & in2有兩個輸出,左邊輸出out1 = in2,右邊輸出out2 = in1 op in2 (這裡的op就是reduce部分的op),如圖:
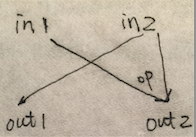
如上上圖中的op為加法,那舉個例子就有:in1 = 11, in2 = 10, 可得out1 = in2 = 10, out2 = in1 + in2 = 21。由此可以推出downsweep部分的所有value,如上上圖。
這裡畫圈的元素都是從reduce部分直接“天降”(鏡面反射)過來的,注意,每一個元素位置只去reduce出來該位置的最終結果,而且由於是鏡面反射,step層數越大的reduce計算結果“天降”越快,即從reduce的“天降”順序為
| 36 |
| 10 |
| 3, 11 |
| 1, 3, 5, 7 |
Q: downsweep部分的step complexity 和 work complexity?
And:downsweep是reduce部分的mirror,所以當然和reduce部分的complexity都一樣啦。
綜上,Blelloch方法的work complexity為
ANS:這取決於所用的GPU,問題規模,以及實現時的優化方法。這一邊是一個不斷變化的問題:一開始我們有很多data(work > processor), 更適合用work efficient parallel algorithm (e.g Blelloch), 隨著程式執行,工作量被減少了(processor > work),適合改用step efficient parallel algorithm,這樣而後資料又多起來啦,於是我們又適合用work efficient parallel algorithm…
總結一下,見下表為每種方法的complexity,以及適於解決的問題:
| serial | Hillis + Steele | Blelloch | |
| work | O(n) | O(nlogn) | O(n) |
| step | n | log(n) | 2*log(n) |
| 512個元素的vector 512個processor |
√ | ||
| 一百萬的vector 512個processor |
√ | ||
| 128k的vector 1個processor |
√ |
4. Histogram
4.1. what is histogram?
顧名思義,統計直方圖就是將一個統計量在直方圖中顯示出來。
4.2. Histogram 的 Serial 實現:
分兩部分:1. 初始化,2. 統計
for(i = 0; i < bin.count; i++)
res[i] = 0;
for(i = 0; i<nElements; i++)
res[computeBin(i)] ++;4.3. Histogram 的 Parallel 實現:
- 直接實現:
kernel:
__global__ void naive_histo(int* d_bins, const int* d_in, const in BIN_COUNT){
int myID = threadIdx.x + blockDim.x * blockIdx.x;
int myItem = d_in[myID];
int myBin = myItem % BIN_COUNT;
d_bins[myBin]++;
}來想想這樣有什麼問題?又是我們上次說的read-modify-write問題,而serial implementation不會有這個問題,那麼想實現parallel histogram計算有什麼方法呢?
法1. accumulate using atomics
即,將最後一句變成
atomicAdd(&(d_bins[myBin]), 1);
但是對於atomics的方法而言,不管GPU多好,並行執行緒數都被限制到histogram個數N,也就是最多隻有N個執行緒並行。
法2. local memory + reduce
設定n個並行執行緒,每個執行緒都有自己的local histogram(一個長為bin數的vector);即每個local histogram都被一個thread順序訪問,所以這樣沒有shared memory,即便沒有用atomics也不會出現read-modify-write問題。
然後,我們將這n個histogram進行合併(即加和),可以通過reduce實現。