
ORACLE中record、varray、table、%type、%rowtype的使用詳解
ORACLE中record、varray、table和%type、%rowtype的使用詳解
2015年05月24日 18:14:42 X-rapido 閱讀數:7585 標籤: recordvarraytable資料庫oracle 更多
個人分類: 資料庫
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/xiaokui_wingfly/article/details/45953633
更早原文1
https://blog.csdn.net/liangweiwei130/article/details/38223319
下面在更早原文1有追加
檢視原文:http://www.ibloger.net/article/230.html
1 說明
定義記錄資料型別。它類似於C語言中的結構資料型別(STRUCTURE),PL/SQL提供了將幾個相關的、分離的、基本資料型別的變數組成一個整體的方法,即RECORD複合資料型別。在使用記錄資料型別變數時,需要在宣告部分先定義記錄的組成、記錄的變數,然後在執行部分引用該記錄變數本身或其中的成員。
定義記錄資料型別的語法如下:
TYPE RECORD_NAME IS RECORD(
V1 DATA_TYPE1 [NOT NULL][:=DEFAULT_VALUE],
V2 DATA_TYPE2 [NOT NULL][:=DEFAULT_VALUE],
VN DATA_TYPEN [NOT NULL][:=DEFAULT_VALUE]);
陣列是具有相同資料型別的一組成員的集合。每個成員都有一個唯一的下標,它取決於成員在陣列中的位置。在PL/SQL中,陣列資料型別是VARRAY(variable array,即可變陣列)。
定義VARRAY資料型別的語法如下:
TYPE VARRAY_NAMEIS VARRAY(SIZE) OF ELEMENT_TYPE [NOT NULL];
其中,varray_name是VARRAY資料型別的名稱,size是正整數,表示可以容納的成員的最大數量,每個成員的資料型別是element_typeo預設時,成員可以取空值,否則需要使用NOT NULL加以限制。
定義記錄表(或索引表)資料型別。它與記錄型別相似,但它是對記錄型別的擴充套件。它可以處理多行記錄,類似於C語言中的二維陣列,使得可以在PL/SQL中模仿資料庫中的表。
定義記錄表型別的語法如下:
TYPE TABLE NAME IS TABLE OF ELEMENT_TYPE [NOT NULL]
INDEX BY [BINARY_INTEGER|PLS_INTEGER|VARRAY2];
關鍵字INDEX BY表示建立一個主鍵索引,以便引用記錄表變數中的特定行。
BINARY_INTEGER的說明
如語句:TYPE NUMBERS IS TABLE OF NUMBER INDEX BY BINARY_INTEGER;其作用是,加了”INDEX BYBINARY_INTEGER ”後,NUMBERS型別的下標就是自增長,NUMBERS型別在插入元素時,不需要初始化,不需要每次EXTEND增加一個空間。
而如果沒有這句話“INDEXBY BINARY_INTEGER”,那就得要顯示對初始化,且每插入一個元素到NUMBERS型別的TABLE中時,都需要先EXTEND。
2 舉例
-
--組織機構結構表 -
CREATE TABLE SF_ORG -
( -
ORG_ID INT NOT NULL, --組織機構主鍵ID -
ORG_NAME VARCHAR2(50),--組織機構名稱 -
PARENT_ID INT--組織機構的父級 -
) -
--一級組織機構 -
INSERT INTO SF_ORG(ORG_ID, ORG_NAME, PARENT_ID) VALUES(1, '一級部門1',0); -
--二級部門 -
INSERT INTO SF_ORG(ORG_ID, ORG_NAME, PARENT_ID) VALUES(2, '二級部門2',1); -
INSERT INTO SF_ORG(ORG_ID, ORG_NAME, PARENT_ID) VALUES(3, '二級部門3',1); -
INSERT INTO SF_ORG(ORG_ID, ORG_NAME, PARENT_ID) VALUES(4, '二級部門4',1);
2.2 RECORD的使用舉例
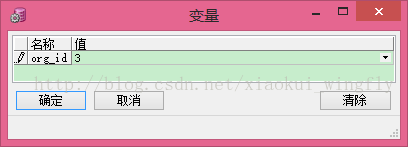
先定義一個只與SF_ORG表中某幾個列的資料型別相同的記錄資料型別TYPE_ORG_RECORD,然後宣告一個該資料型別的記錄變數V_ORG_RECORD,最後用替換變數&ORG_ID接受輸入的僱員編碼,查詢並顯示該僱員的這幾列中的資訊。注意,在使用RECORD資料型別的變數時要用“.”運算子指定記錄變數名限定詞。
一個記錄型別的變數只能儲存從資料庫中查詢出的一行記錄,如果查詢出了多行記錄,就會出現錯誤。
-
-- RECORD的使用舉例 -
declare -
type type_org_record is record( -
v_name sf_org.org_name%type, -
v_parent sf_org.parent_id%type); -
v_record type_org_record; -
begin -
select org_name, parent_id into v_record from sf_org so -
where so.org_id = &org_id; -
dbms_output.put_line('部門名稱:' || v_record.v_name); -
dbms_output.put_line('上級部門編碼:' || to_char(v_record.v_parent)); -
end;
執行時會彈出一個輸入框,如下圖,執行完畢以後可以在輸出中檢視效果

2.3 VARRAY的使用舉例
先定義一個能儲存5個VARCHAR2(25)資料型別的成員的VARRAY資料型別ORG_VARRAY_TYPE,然後宣告一個該資料型別的VARRAY變數V_ORG_VARRAY,最後用與ORG_VARRAY_TYPE資料型別同名的建構函式語法給V_ORG_VARRAY變數賦予初值並顯示賦值結果。
注意,在引用陣列中的成員時.需要在一對括號中使用順序下標,下標從1開始而不是從0開始。
-
-- VARRAY的使用舉例 -
declare -
type org_varray_type is varray(5) of varchar2(25); -
v_arr_set org_varray_type; -
begin -
v_arr_set := org_varray_type('1','2','3','4','5'); -
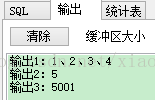
dbms_output.put_line('輸出1:' || v_arr_set(1) || '、'|| v_arr_set(2) || '、'|| v_arr_set(3) || '、'|| v_arr_set(4)); -
dbms_output.put_line('輸出2:' || v_arr_set(5)); -
v_arr_set(5) := '5001'; -
dbms_output.put_line('輸出3:' || v_arr_set(5)); -
end;
2.4 TABLE使用舉例
這個和VARRAY類似。但是賦值方式稍微有點不同,不能使用同名的建構函式進行賦值。具體的如下:
-
-- 儲存單列多行 -
declare -
type org_table_type is table of varchar2(25) -
index by binary_integer; -
v_org_table org_table_type; -
begin -
v_org_table(1) := '1'; -
v_org_table(2) := '2'; -
v_org_table(3) := '3'; -
v_org_table(4) := '4'; -
v_org_table(5) := '5'; -
dbms_output.put_line('輸出1:' || v_org_table(1) || '、'|| v_org_table(2) || '、'|| v_org_table(3) || '、'|| v_org_table(4)||'、'|| v_org_table(5)); -
end;
2.4.2 儲存多列多行和ROWTYPE結合使用
採用bulkcollect可以將查詢結果一次性地載入到collections中。而不是通過cursor一條一條地處理。
-
-- 儲存多列多行和rowtype結合使用 -
declare -
type t_type is table of sf_org%rowtype; -
v_type t_type; -
begin -
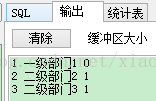
select org_id, org_name, parent_id bulk collect into v_type from sf_org where sf_org.org_id <= 3; -
for v_index in v_type.first .. v_type.last loop -
dbms_output.put_line(v_type(v_index).org_id ||' '|| v_type(v_index).org_name ||' '|| v_type(v_index).parent_id ); -
end loop; -
end;
2.4.3 儲存多列多行和RECORD結合使用
採用bulkcollect可以將查詢結果一次性地載入到collections中。而不是通過cursor一條一條地處理。
-
-- 儲存多列多行和RECORD結合使用 -
declare -
type test_emp is record -
( -
c1 sf_org.org_name%type, -
c2 sf_org.parent_id%type -
); -
type t_type is table of test_emp; -
v_type t_type; -
begin -
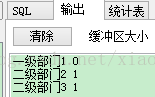
select org_name, parent_id bulk collect into v_type from sf_org where sf_org.org_id <= 3; -
for v_index in v_type.first .. v_type.last loop -
dbms_output.put_line(v_type(v_index).c1 || ' ' || v_type(v_index).c2); -
end loop; -
end;
3 問題
varry和table集合不能直接對其進行查詢。只能對其進行遍歷。
4 其他
在我的Oracle 建立 split 和 splitstr 函式文章中,有包含table的查詢示例圖:http://blog.csdn.net/xiaokui_wingfly/article/details/45922141
%TYPE說明
為了使一個變數的資料型別與另一個已經定義了的變數(尤其是表的某一列)的資料型別相一致,Oracle提供了%TYPE定義方式。當被參照的那個變數的資料型別改變了之後,這個新定義的變數的資料型別會自動跟隨其改變,容易保持一致,也不用修改PL/SQL程式了。當不能確切地知道被參照的那個變數的資料型別時,就只能採用這種方法定義變數的資料型別。
%ROWTYP說明
如果一個表有較多的列,使用%ROWTYPE來定義一個表示表中一行記錄的變數,比分別使用%TYPE來定義表示表中各個列的變數要簡潔得多,並且不容易遺漏、出錯。這樣會增加程式的可維護性。
為了使一個變數的資料型別與一個表中記錄的各個列的資料型別相對應、一致,Oracle提供%ROWTYPE定義方式。當表的某些列的資料型別改變了之後,這個新定義的變數的資料型別會自動跟隨其改變,容易保持一致,也不用修改PL/SQL程式了。當不能確切地知道被參照的那個表的結構及其資料型別時,就只能採用這種方法定義變數的資料型別。
一行記錄可以儲存從一個表或遊標中查詢到的整個資料行的各列資料。一行記錄的各個列與表中一行的各個列有相同的名稱和資料型別。
參考文章:http://blog.csdn.net/liangweiwei130/article/details/38223319
https://blog.csdn.net/xiaokui_wingfly/article/details/45953633
%type、%rowtype,varry、record、table 的使用詳解
2018年08月02日 23:20:30 魚丸丶粗麵 閱讀數:106
版權宣告:轉載、討論時,請在明顯位置註明出處。 https://blog.csdn.net/qq_34745941/article/details/81368648
0、基礎資料準備
CREATE TABLE stu(
ID NUMBER(3) PRIMARY KEY,
xm NVARCHAR2(30)
)
INSERT INTO stu(ID, xm) VALUES(1, '小遊子');
INSERT INTO stu(ID, xm) VALUES(2, '小倩子');- 1
- 2
- 3
- 4
- 5
- 6
1、基礎資料型別定義
1.1 %type
單條記錄的資料型別定義
v_id System.stu.id%type;
好處:若 id 欄位型別改變,v_id 欄位型別也會自動跟著改變- 1
- 2
- 3
1.2 %rowtype
所有記錄的資料型別定義
v_row System.stu%rowtype;
好處:v_row 中所有的欄位型別始終與 stu 表中的欄位那型別保持一致。- 1
- 2
- 3
1.3 record
%type 是宣告 單條記錄的資料型別,%rowtype 是宣告 所有記錄的資料型別,如果想 宣告多個數據型別(但不是 所有資料型別),該怎麼辦了?此時就用
record
DECLARE
TYPE type_stu_record IS RECORD(
v_id system.stu.id%TYPE,
v_xm system.stu.xm%TYPE
);
v_stu_record type_stu_record;
BEGIN
SELECT t.id, -- 型別,個數都必須與宣告時,保持一致
t.xm
INTO v_stu_record
FROM stu t
WHERE ROWNUM = 1; -- 如果想 賦值多條記錄,請看 集合資料型別定義
dbms_output.put_line(v_stu_record.v_id ||' : '||v_stu_record.v_xm);
EXCEPTION WHEN OTHERS THEN
dbms_output.put_line(Sqlerrm);
END;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1、集合資料型別定義
基本資料型別,
select into時,只能一條條插入記錄
集合資料型別,可使用select bulk collect into一次性插入所有資料
1.1 varry
指定長度的陣列,下標從 1 開始。遍歷輸出所有項
type 陣列名 varray(size) of 元素型別 [not null];
size : 陣列長度,必填項。
DECLARE
TYPE type_var_stu IS VARRAY(4) OF VARCHAR2(30);
v_arr type_var_stu;
BEGIN
v_arr := type_var_stu('a','b','c','d');
dbms_output.put_line('輸出第一個:'||v_arr(3));
v_arr(3) := 'dd'; -- 下標3,必須已存在值,否則報錯。
dbms_output.put_line('輸出第三個:'||v_arr(3));
FOR v_index IN v_arr.first .. v_arr.last LOOP
-- 迴圈遍歷陣列
dbms_output.put_line(v_arr(v_index));
END LOOP;
EXCEPTION WHEN OTHERS THEN
dbms_output.put_line(sqlerrm);
END;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1.2 table
type table_name is table of element_type[not null]
index by [binary_integer|pls_integer|varray2];
index by : 建立一個主鍵索引,以便引用記錄表變數中的特定行。
binary_integer : 下標自增(無需‘初始化’)- 1
- 2
- 3
- 4
- 5
1.3.1 儲存單行單列
DECLARE
TYPE type_table_stu IS TABLE OF VARCHAR2(30)
INDEX BY BINARY_INTEGER;
v_t type_table_stu;
BEGIN
v_t(1) := '1';
v_t(2) := '2';
v_t(3) := '3';
dbms_output.put_line('輸出第一個: '||v_t(1));
EXCEPTION WHEN OTHERS THEN
dbms_output.put_line(Sqlerrm);
END;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.3.2 儲存多行多列與rowtype聯用
要插入的列與表資料型別完全一致
DECLARE
TYPE type_table_stu IS TABLE OF system.stu%ROWTYPE;
v_stu type_table_stu;
BEGIN
SELECT t.id, -- 插入的值,個數、型別 都必須和宣告時完全一致。
t.xm
BULK COLLECT -- 一次性提取資料至集合內
INTO v_stu
FROM stu t;
FOR v_index IN v_stu.first .. v_stu.last LOOP
dbms_output.put_line(v_stu(v_index).id||' : '||v_stu(v_index).xm);
END LOOP;
EXCEPTION WHEN OTHERS THEN
dbms_output.put_line(Sqlerrm);
END;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.3.3 儲存多行多列與record聯用
DECLARE
TYPE type_record_stu IS RECORD(
v_id system.stu.id%TYPE,
v_xm system.stu.xm%TYPE
);
TYPE type_table_stu IS TABLE OF type_record_stu; -- 將記錄作為 table 的資料型別
v_stu type_table_stu;
BEGIN
SELECT t.id,
t.xm
BULK COLLECT
INTO v_stu
FROM stu t;
FOR v_index IN v_stu.first .. v_stu.last LOOP
dbms_output.put_line(v_stu(v_index).v_id||' : '||v_stu(v_index).v_xm);
END LOOP;
EXCEPTION WHEN OTHERS THEN
dbms_output.put_line(Sqlerrm);
END;https://blog.csdn.net/qq_34745941/article/details/81368648
oracle 複合型別-record、陣列、%type、%rowtype、plsql table型別
- 部落格分類:
- oracle10g
知識點:
1,ORACLE 在 PL/SQL 中除了提供象前面介紹的各種型別外,還提供一種稱為複合型別的型別---
記錄和表.
記錄型別類似於C語言中的結構資料型別,它把邏輯相關的、分離的、基本資料型別的變數組成一個整體儲存起來,它必須包括至少一個標量型或RECORD 資料型別的成員,稱作PL/SQL RECORD 的域(FIELD),其作用是存放互不相同但邏輯相關的資訊。在使用記錄資料型別變數時,需要先在宣告部分先定義記錄的組成、記錄的變數,然後在執行部分引用該記錄變數本身或其中的成員。
定義記錄型別語法如下:
Java程式碼

- TYPE record_name IS RECORD(
- v1 data_type1 [NOT NULL] [:= default_value ],
- v2 data_type2 [NOT NULL] [:= default_value ],
- ...... [color=red]//注意末尾不能帶逗號[/color]
- vn data_typen [NOT NULL] [:= default_value ] );
例項1:
Java程式碼
- declare
- type test_rec is record(
- name varchar2(30) not null := '胡勇',
- info varchar2(100) --該處末尾不能新增逗號
- );
- rec_book test_rec;
- begin
- rec_book.name := '陳超陽';
- rec_book.info := '中華人民共和國';
- dbms_output.put_line(rec_book.name || ',' || rec_book.info);
- end;
例項2:
Java程式碼
- declare
- --定義與hr.employees表中的這幾個列相同的記錄資料型別
- type record_type_emp is record(
- v_ename emp.ename%type,
- v_job emp.job%type,
- v_sal emp.sal%type
- );
- --宣告一個該記錄資料型別的記錄變數
- v_emp_record record_type_emp;
- begin
- --注意查詢的型別應該與複合變數成員的順序一致
- select ename,job,sal into v_emp_record from emp where empno = 7369;
- dbms_output.put_line(v_emp_record.v_ename);
- dbms_output.put_line(v_emp_record.v_job);
- dbms_output.put_line(v_emp_record.v_sal);
- end;
輸出如下:
SMITH
CLERK
800
例項3:
Java程式碼
- declare
- type type_mytype is record(
- ename scott.emp.ename%type,
- job scott.emp.job%type,
- sal scott.emp.sal%type
- );
- v_mytype type_mytype;
- begin
- select e.ename,e.job,e.sal into v_mytype from scott.emp e where empno = '7499';
- dbms_output.put_line(v_mytype.ename);
- end;
注意:一個記錄型別的變數只能儲存從資料庫中查詢出的一行記錄,若查詢出了多行記錄,就會出現錯誤。否則會報錯:
ORA-01422: 實際返回的行數超出請求的行數
ORA-06512: 在 line 11
第二種複合型別--陣列
資料是具有相同資料型別的一組成員的集合。每個成員都有一個唯一的下標,它取決於成員在陣列中的位置。在PL/SQL中,陣列資料型別是VARRAY。
定義VARRY資料型別語法如下:
Java程式碼
- TYPE varray_name IS VARRAY(size) OF element_type [NOT NULL];
varray_name是VARRAY資料型別的名稱,size是下整數,表示可容納的成員的最大數量,每個成員的資料型別是element_type。預設成員可以取空值,否則需要使用NOT NULL加以限制。對於VARRAY資料型別來說,必須經過三個步驟,分別是:定義、宣告、初始化。
例項1:
Java程式碼
- --定義陣列型別
- declare
- --定義一個最多儲存5個varchar(25)資料型別成員的varray資料型別
- type reg_varray_type is varray(5) of varchar(25);
- --宣告一個該varray資料型別的變數
- v_reg_varray reg_varray_type;
- begin
- --用建構函式賦予初值(注意賦值方式--建構函式)
- [color=red] --訪問陣列是從下標1開始的(不是0)[/color]
- v_reg_varray := reg_varray_type('中國','美國','英國','日本','河南');
- dbms_output.put_line(v_reg_varray(1));
- dbms_output.put_line(v_reg_varray(2));
- dbms_output.put_line(v_reg_varray(3));
- dbms_output.put_line(v_reg_varray(4));
- dbms_output.put_line(v_reg_varray(5));
- end;
例項2:
--陣列 varray例項
declare
type type_myVarray is varray(3) of Varchar2(30);
v_myvarrayType type_myVarray;
begin
--第一種賦值方法:建構函式賦值
v_myvarrayType := type_myVarray('男人','女人','不男不女');
dbms_output.put_line(v_myvarrayType(1));
dbms_output.put_line(v_myvarrayType(2));
dbms_output.put_line(v_myvarrayType(3));
--第二種賦值方法:一個一個的賦值
select e.ename,e.job,to_char(e.sal) into v_myvarrayType(1),v_myvarrayType(2),v_myvarrayType(3) from scott.emp e where empno = 7369;
--這種方式不行:會報錯:---PLS-00642: 在 SQL 語句中不允許使用本地收集型別(這種賦值方式只適應與record型別的變數)
--select e.ename,e.job,to_char(e.sal) into v_myvarrayType from scott.emp e where empno = 7369;
dbms_output.put_line(v_myvarrayType(1));
dbms_output.put_line(v_myvarrayType(2));
dbms_output.put_line(v_myvarrayType(3));
end;
第三種類型:%type
定義一個變數,其資料型別與已經定義的某個資料變數(尤其是表的某一列)的資料型別相一致,這時可以使用%TYPE。
使用%TYPE特性的優點在於:
所引用的資料庫列的資料型別可以不必知道;
所引用的資料庫列的資料型別可以實時改變,容易保持一致,也不用修改PL/SQL序。
例項:
Java程式碼
- DECLARE
- -- 用%TYPE 型別定義與表相配的欄位
- TYPE T_Record IS RECORD(
- T_no emp.empno%TYPE,
- T_name emp.ename%TYPE,
- T_sal emp.sal%TYPE );
- -- 宣告接收資料的變數
- v_emp T_Record;
- BEGIN
- SELECT empno, ename, sal INTO v_emp FROM emp WHERE empno=7788;
- DBMS_OUTPUT.PUT_LINE(TO_CHAR(v_emp.t_no)||' '||v_emp.t_name||' ' ||
- TO_CHAR(v_emp.t_sal));
- end;
第四種類型:%rowtype
PL/SQL 提供%ROWTYPE操作符, 返回一個記錄型別, 其資料型別和資料庫表的資料結構相一致。 使用%ROWTYPE特性的優點在於:
所引用的資料庫中列的個數和資料型別可以不必知道;
所引用的資料庫中列的個數和資料型別可以實時改變,容易保持一致,也不用修改PL/SQL程式。
例項:
Java程式碼
- declare
- v_empno emp.empno%type := &no;
- rec emp%rowtype;
- begin
- select * into rec from emp where empno = v_empno;
- dbms_output.put_line(rec.ename);
- dbms_output.put_line(rec.job);
- dbms_output.put_line(rec.sal);
- dbms_output.put_line(rec.deptno);
- end;
待續**************************************************************
第五種:更高階的資料型別psql表型別;
在前面我們已經講解了varray,record型別,可以看出他們都是一維的。下面我們要講解的是綜合上面兩種型別的資料型別plsql 表,該表示二維的。可以囊括上面的兩種型別。
定義記錄表(或索引表)資料型別。它與記錄型別相似,但它是對記錄型別的擴充套件。它可以處理多行記錄,類似於高階中的二維陣列,使得可以在PL/SQL中模仿資料庫中的表。
分享到: 

oracle10g 系統自帶函式-subStr,sys_connec ... | oracle 檢視(view)
評論