
面試題錦集
阿新 • • 發佈:2018-12-26
第一部分 Python基礎篇(80題)
1. 為什麼學習Python?
IT行業是目前乃至以後的趨勢,並且我也對IT行業有濃厚的興趣,現在都是實體與網際網路相結合,生活中小到掃碼付款,大到淘寶京東,甚至買房都可以在通過網際網路實現,而我從知乎和其他網站了解到的,
在眾多語言當中,python是未來語言,python不僅可以寫網站,前後端互動,還涉及人工智慧,金融,爬蟲,人臉識別等等,美國早在幾年前就將python納入大學的基本課程,現在中國杭州和一些試點城市,
從小學都開始普及Python課程,所以我要學習Python。
2. 通過什麼途徑學習的Python?
在學校期間無意間看到別人在弄這個人臉識別,通過一張照片能分辨出性別,年齡範圍和顏值,然後就從網上搜了一下python,發現有好多的文件和路飛學誠等都有python的課程與講解,
讓後我通過閱讀相關書籍以及網上的一些課程進行學習。
3.Python和Java、PHP、C、C#、C++等其他語言的對比?
python,php是解釋性語言,程式碼執行期間逐行翻譯成目標機器碼,下次執行時逐行解釋
而C、Java是編譯型語言,編譯後再執行。
python和以上語言對比,第一點開發效率快,有非常強大的第三方模組支援,第二點語法清晰簡單,第三點有非常強大的跨平臺和擴充套件性
4.簡述解釋型和編譯型程式語言?
編譯型:執行前先由編譯器將高階語言程式碼編譯為對應機器的cpu彙編指令集,再由彙編器彙編為目標機器碼,生成可執行檔案,然最後執行生成的可執行檔案。最典型的代表語言為C/C++,一般生成的可執行檔案及.exe檔案。 解釋型:在執行時由翻譯器將高階語言程式碼翻譯成易於執行的中間程式碼,並由直譯器(例如瀏覽器、虛擬機器)逐一將該中間程式碼解釋成機器碼並執行(可看做是將編譯、執行合二為一了)。最典型的代表語言為JavaScript、Python、Ruby和Perl等。 總結: 編譯型的語言就類似於去飯店點菜,菜上來了就吃 解釋型的語言就類似於去飯店吃火鍋,以一邊吃一邊涮
解釋性:邊解釋變執行(py,php)
編譯型:編譯後再執行(jaca,c,c#)"""
5.Python直譯器種類以及特點?
CPython:# c語言開發的,官方推薦,最常用 當 從Python官方網站下載並安裝好Python2.7後,就直接獲得了一個官方版本的直譯器:Cpython,這個直譯器是用C語言開發的,所以叫 CPython,在命名行下執行python,就是啟動CPython直譯器,CPython是使用最廣的Python直譯器。 IPython:# 基於CPython之上的互動式直譯器,只是在互動上有增強 IPython是基於CPython之上的一個互動式直譯器,也就是說,IPython只是在互動方式上有所增強,但是執行Python程式碼的功能和CPython是完全一樣的,好比很多國產瀏覽器雖然外觀不同,但核心其實是呼叫了IE。 JPython:JAVA寫的直譯器 PyPy# 是另一個Python直譯器,它的目標是執行速度,PyPy採用JIT技術,對Python程式碼進行動態編譯,所以可以顯著提高Python程式碼的執行速度。 Pypy:python寫的直譯器,目前執行速度最快的直譯器,採用JTT技術,對python進行動態編譯 IronPython:c#寫的直譯器 IronPython和Jython類似,只不過IronPython是執行在微軟.Net平臺上的Python直譯器,可以直接把Python程式碼編譯成.Net的位元組碼。 在Python的直譯器中,使用廣泛的是CPython,對於Python的編譯,除了可以採用以上直譯器進行編譯外,技術高超的開發者還可以按照自己的需求自行編寫Python直譯器來執行Python程式碼,十分的方便! Qpython 安卓端的一個python直譯器,Qpython是一種通用叫法,其實它分為兩款,分別是Qpython和Qpython3分別對應的是python2和python3
6.位和位元組的關係?
1位元組=8位
1byte=8bit(資料儲存以位元組為單位)
7.b、B、KB、MB、GB 的關係?
1B=8bit; 1KB=1024B 1MB=1024KB
8.請至少列舉5個 PEP8 規範(越多越好)。
空格使用 各種右括號前不要加空格 逗號,冒號,分號前不要加空格 函式的左括號前不要加空格func(1) 序列的左括號前不要加空格list[1,2] 操作符左右各加一個空格,不要為了對齊增加空格 函式預設引數使用的賦值符左右省略空格 不要將多句語句寫在同一行,儘管使用; if/for/while語句中,即使執行語句只有一句,也必須另起一行 程式碼編排 縮排,四個空格,而不是tab鍵 每行長度79,換行可使用反斜槓,做好使用圓括號 類與類之間空兩行 方法之間空一行 1.縮排。4個空格的縮排(編輯器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。 2.每行最大長度79,換行可以使用反斜槓,最好使用圓括號。換行點要在操作符的後邊敲回車。 3.類和top-level函式定義之間空兩行;類中的方法定義之間空一行;函式內邏輯無關段落之間空一行;其他地方儘量不要再空行 4.註釋 總體原則,錯誤的註釋不如沒有註釋。所以當一段程式碼發生變化時,第一件事就是要修改註釋!註釋必須使用英文,最好是完整的句子,首字母大寫,句後要有結束符,結束符後跟兩個空格,開始下一句。如果是短語,可以省略結束符。 塊註釋,在一段程式碼前增加的註釋。在‘#’後加一空格。段落之間以只有‘#’的行間隔。 行註釋,在一句程式碼後加註釋。比如:(但是這種方式儘量少使用) 避免無謂的註釋 5.文件描述為所有的共有模組、函式、類、方法寫docstrings;非共有的沒有必要,但是可以寫註釋(在def的下一行)。 如果docstring要換行 6.命名規範總體原則,新編程式碼必須按下面命名風格進行,現有庫的編碼儘量保持風格。 儘量單獨使用小寫字母‘l’,大寫字母‘O’等容易混淆的字母。 模組命名儘量短小,使用全部小寫的方式,可以使用下劃線。 包命名儘量短小,使用全部小寫的方式,不可以使用下劃線。 類的命名使用CapWords的方式,模組內部使用的類採用_CapWords的方式。 異常命名使用CapWords+Error字尾的方式。 全域性變數儘量只在模組內有效,類似C語言中的static。實現方法有兩種,一是all機制;二是字首一個下劃線。 函式命名使用全部小寫的方式,可以使用下劃線。 常量命名使用全部大寫的方式,可以使用下劃線。 類的屬性(方法和變數)命名使用全部小寫的方式,可以使用下劃線。 類的屬性有3種作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public屬性前,字首一條下劃線。 類的屬性若與關鍵字名字衝突,字尾一下劃線,儘量不要使用縮略等其他方式。 為避免與子類屬性命名衝突,在類的一些屬性前,字首兩條下劃線。比如:類Foo中宣告__a,訪問時,只能通過Foo._Foo__a,避免歧義。如果子類也叫Foo,那就無能為力了。 類的方法第一個引數必須是self,而靜態方法第一個引數必須是cls。 具體詳情請檢視
9.通過程式碼實現如下轉換:
二進位制轉換成十進位制:v = “0b1111011”
十進位制轉換成二進位制:v = 18
八進位制轉換成十進位制:v = “011”
十進位制轉換成八進位制:v = 30
十六進位制轉換成十進位制:v = “0x12”
十進位制轉換成十六進位制:v = 87
print(int(0b1111011)) # 123=(1+2+2**3+2**4+2**5+2**6),0b是二進位制符號,不參與運算 print(bin(18)) # 0b10010 print(int("011")) # 11 print(oct(30)) # 0o36 print(int(0x12)) # 18 print(hex(87)) # 0x57
相關知識點
# bin(18) 將整數轉換為2進位制 0b 二進位制識別符號 # oct(30)轉整數轉換為8進位制 0o 八進位制識別符號 # hex(87) 轉整數轉換為16進位制 0x 十六進位制識別符號 # hex(integer) 將integer轉換為16進位制,形式為0x0123456789abcdef。integer必須為整型 print(hex(87)) # 0x57 # otc(integer) 將integer轉換為8進位制 print(oct(30)) # bin(integer) 將integer轉換為2進位制 print(bin(18)) # format(integer, 'x') 將integer轉換為16進位制,不帶0x。integer為整型,'x'可換為'o','b','d'相對應八、二、十進位制。 print(format(10,'x')) # a 轉化為16進位制的數 print(format(10,'o')) # 12 轉化為8進位制的數 print(format(10,'b')) # 1010 轉化為2進位制的數 print(format(10,'d')) # 10 轉化為10進位制的數 # int(string, number)將任意進位制的s(string型別)轉換為十進位制。s與number的進位制型別需匹配,如s是16進位制,則number = 16,否側會出錯。若s為16進位制,0x可帶可不帶,其他進位制同。 print(int("011",8)) print(int("0x12",16)) print(int("12",16)) # 若string前面帶有表示進位制的符號,可以用int直接轉 print(int(0o011)) print(int(0x12))
10.請編寫一個函式實現將IP地址轉換成一個整數。
如 10.3.9.12 轉換規則為:
10 00001010
3 00000011
9 00001001
12 00001100
再將以上二進位制拼接起來計算十進位制結果:00001010 00000011 00001001 00001100 = ?
ip = "10.3.9.12" def ip_to_int(ip): # 將ip轉化為整數 ip_list = ip.split('.') sum = 0 for i in range(4): # 0,1,2,3 sum = sum + int(ip_list[i]) * 256 ** (3 - i) # 相當於256進位制的數在向10進位制轉化,這裡只有4位,前4位均為0 return sum num = ip_to_int(ip) # print(ret) # num = 167971084 def int_to_ip(sum): int_list = [] ys = sum for i in reversed(range(4)): # 3,2,1,0 res = divmod(ys, 256 ** i) int_list.append(str(res[0])) ys = res[1] return ".".join(int_list) a = int_to_ip(num) print(a)
11.python遞迴的最大層數?
python預設是998層,實際和計算機效能關係很大,windows一般再3000多,MAC一般在1萬以上
12.求結果:
v1 = 1 or 3 1 v2 = 1 and 3 3 v3 = 0 and 2 and 1 0 v4 = 0 and 2 or 1 1 v5 = 0 and 2 or 1 or 4 1 v6 = 0 or Flase and 1 Flase # 優先順序:()>not>and>or #a or b #a為真,返回a,否則返回b # and 相反,記住一個演算法就行
13.ascii、unicode、utf-8、gbk 區別?
ASCII: 由於計算機是美國人發明的,因此最早只把127個字元編碼到計算機裡,即大小寫英文字母、數字、部分西歐字元和一些常用符號等。 ASCII碼只需要1個位元組(1byte=8bit)即可存放。 Unicode: 如果想要處理非ASCII碼錶裡的字元,顯然1個位元組是不夠用的,因此,中國將中文字元編入了GB2312,日本將日文編入了Shift-JIS、韓國將韓文編入了Euc-kr,其他國家也有自己的編碼,
這樣做的結果就是如果將含有多種編碼格式的字元存放到同一個文本里,就會出現令人頭痛的亂碼問題(亂碼問題本質就是解碼的字典不同導致的。) 鑑於上述原因,Unicode應運而生,它將所有字元都統一編入在一個字典裡,之前用2個位元組表示一個字元,後來發現兩個位元組不能表示全部字元後來改為4個位元組表示一個字元,
這樣再也不用擔心不同的字符集裡的字元放在一起出現亂碼的問題了。所以現在Unicode是有兩個版本,之前的版本是2個位元組表示一個字元,現在是4個位元組表示一個字元,
python3x使用的unicode全部是4個位元組表示一個字元。 Unicode和ASCII的區別就是: 1,前者是用4個位元組(或者2個位元組)表示一個字元,後者是用1個位元組表示的。 2,前者叫萬國碼,包含有記錄的所有的文字,而後者只包含數字,字母,特殊符號。 UTF-8: Unicode的出現似乎完美的解決了亂碼問題,但是會帶來一個新的問題:如果你的文字基本全是英文或數字,那麼用Unicode儲存會比ASCII儲存多出幾倍的空間,而且傳輸起來也不划算(要佔用更多的頻寬),
怎麼辦呢?能不能根據字元的種類來決定採取佔用的位元組呢? 回答是可以的,這就是UTF-8,也就是“可變長編碼”,它能根據Unicode字元的種類來決定儲存的長度,例如:常用的英文編碼成1個位元組,漢字編碼成3個位元組 如果你的文本里含有大量的英文字元、數字、常用符號,那麼使用UTF-8將會節省大量的儲存空間,傳輸起來也會快很多 GB2312和GBK: GB2312是中國自己釋出的一套漢字編碼規範,於1980年釋出。而GBK是中國在1995年頒佈的,它向下相容了GB2312,還向上相容了ISO國際標準(ANSI),包含的字元更多了。
但是無論是GBK,還是GB2312,都只是'國標',他只包含常用中文,數字,字母,特殊符號。 8位表示1個位元組 Ascii:1個位元組表示1個字元,支援英文 unicode:4個位元組表示1個字元 utf-8: 英文:1個位元組表示1個字元 歐洲:2個位元組表示1個字元 亞洲:3個位元組表示1個字元 gbk: 英文:1個位元組表示1個字元 中文:2個位元組表示1個字元
14.位元組碼和機器碼的區別?
位元組碼:位元組碼是一種中間狀態(中間碼)的二進位制程式碼(檔案)。需要直譯器轉譯後才能成為機器碼
機器碼:電腦的CPU可直接解讀的資料,是計算機可以直接執行,並且執行速度最快的程式碼。
機器碼
機器碼 學名機器語言指令,白話文就是計算機能夠識別的一種指令.比如
我們在程式中寫hello world其實就是將我們人類能夠識別的內容轉換成計算機能夠識別的01010101
位元組碼 組成的二進位制檔案。位元組碼是一種中間碼,它比機器碼更抽象,需要直譯器轉譯後才能成為機器碼的中間程式碼。
總結:
機器碼就是交於cpu執行的一種檔案
位元組碼是一種中間狀態(中間碼)的二進位制檔案,需要轉譯後才能成為機器碼。
15.三元運算規則以及應用場景?
做簡單邏輯判斷的時候用到 c=a if a>b else b # 如果a大於1的話,c=a,否則c=b
16.列舉 Python2和Python3的區別?
print: py2:print 內容 py3:print(內容) 編碼: py2預設unicode py3預設utf-8 字串: py2: ascii:8位表示一個字元 unicode:16位表示一個字元 py3:都是unicode字串 True和False: py2:是兩個全域性變數(1和0),可以重新賦值 py3:兩個關鍵字,不能重新賦值 迭代: py2:xrange py3:range nonlocal: py3:專有的(宣告為非全域性變數) # nonlocal 適用於在區域性函式 中 的區域性函式, 把最內層的區域性 變數設定成外層區域性可用,但是還不是全域性的。 # global 定義的變數,表明其作用域在區域性以外,即區域性函式執行完之後,不銷燬 經典類,新式類: py2:經典類和新式類並存 py3:新式類預設繼承object yield: py2:yield py3:yield/yield from 檔案操作: py2:readlines() 讀取檔案的所有行,返回一個列表,包含所有行的結束符 xreadlines() 返回一個生成器,迴圈取值 py3:只有readlines() long: py3: 沒有long(長整型),統一使用int,範圍和py2中long的範圍相似 py2: int最大不能超過sys.maxint,根據不同平臺大小不同 在int型別數字後面加L定義長整型,範圍比int
17.用一行程式碼實現數值交換:
a=1 b=2 a,b=b,a print(a,b)
18.Python3和Python2中 int 和 long的區別?
py3:
沒有long(長整型),統一使用int,範圍和py2中long的範圍相似
py2:
int最大不能超過sys.maxint,根據不同平臺大小不同
在int型別數字後面加L定義長整型,範圍比int大
19. xrange和range的區別?
xrange: 產生的是生成器,通過yield每次返回一個,資料較大時,xrange比較好, range: 產生的是列表,把資料一次性返回 1) read([size])方法從檔案當前位置起讀取size個位元組,若無引數size,則表示讀取至檔案結束為止,它範圍為字串物件 2) 從字面意思可以看出,該方法每次讀出一行內容,所以,讀取時佔用記憶體小,比較適合大檔案,該方法返回一個字串物件。 3) readlines()方法讀取整個檔案所有行,儲存在一個列表(list)變數中,每行作為一個元素,但讀取大檔案會比較佔記憶體。 4)xreadlines()方法則是直接返回一個iter迭代器,在python2.3之後就不推薦這種方法了。 for line in f: 拿到每一行資料
20.檔案操作時:xreadlines和readlines的區別?
xreadlines:返回一個生成器,迴圈使用,和readlines基本一致(py2有,py3沒有)
readlines:讀取檔案的所有行,返回一個列表,包含所有行的結束符
21.列舉布林值為False的常見值?
布林型,False表示False,其他為True
整數和浮點數,0表示False,其他為True
字串和類字串型別(包括bytes和unicode),空字串表示False,其他為True
序列型別(包括tuple,list,dict,set等),空表示False,非空表示True
None永遠表示False
22.字串、列表、元組、字典每個常用的5個方法?
str:
split:分割
strip:去掉兩邊的空格
startwith:以什麼開頭
endwith:以什麼結尾
lower:大寫
upper:小寫
join:將可迭代的物件變成字串
list:
append:追加
insert:插入
reverse:反轉
index:索引
copy:淺拷貝
pop:刪除指定索引處的值,不指定索引,預設刪除最後一個
tuple:
count:檢視某個元素出現的次數
index:索引
dict:
get:根據key獲取value,獲取不到報錯
items:用於迴圈,取出所有的key和value
keys:取出所有的key
values:取出所有的value
clear:清空字典
pop:刪除指定鍵對應的值,有返回值(對應的值)。
23.lambda表示式格式以及應用場景?
格式 匿名函式:res=lambda x: i*x print(res(2)) 應用場景 filter(),map(),reduce(),sorted()函式中經常用到,它們都需要函式形參 一般定義呼叫一次 reduce() 對引數序列中元素進行積累,接收兩個引數 省去函式命名的煩惱 lambda存在意義就是對簡單函式的簡潔表示 列表生成式配合 min/max/filter/map/sorted/reduce min:(最小的) li = [-1,2,-3,4] s = min(li,key=lambda x:x) max:(最大的) li = [-1,2,-3,4] s = max(li,key=lambda x:x) print(s) filter:(過濾) li = [-1,2,-3,4,8,9,-4] s = list(filter(lambda x:x >3,li)) map:(對映) li = [1,2,3] s = list(map(lambda x,y,z:x*y*z,li,li,li)) sorted:(排序) dic = {'a1':44,'a2':33} s = sorted(dic.items(),key=lambda x:x[1]) 這樣是將按照字典的值中小的排序,返回的是一個列表中有多個元祖 s = sorted(dic.items(),key=lambda x:x[1],reverse=True) 這樣是將按照字典的值中大的排序,返回的是一個列表中有多個元祖 reduce:(歸納) python2: python2中reduce是內建方法 li = [6,2,3,4,5] s = reduce(lambda x,y:x+y,li) python3: python3中reduce方法內建到functools中 from functools import reduce li = [6,2,3,4,5] s = reduce(lambda x,y:x+y,li)
24.pass的作用?
pass一般用於站位語句,保持程式碼的完整性,不會做任何操作
當你在編寫一個程式時,執行語句部分思路還沒有完成,這時你可以用pass語句來佔位,也可以當做是一個標記,是要過後來完成的程式碼。
程式當中 ... 功能和pass功能一樣
25.*arg和**kwarg作用
他們是動態引數,一般不確定要傳入幾個引數時,可以使用他們定義引數 *args:位置引數,按照位置傳參,將傳入的引數打包成一個元祖,列印引數型別文元組 **kwargs:關鍵字引數,在位置引數之後。按照關鍵字傳參,將傳入的引數打包成一個字典 *args:(表示的就是將實參中按照位置傳值,多出來的值都給args,且以元組的方式呈現)在形參表示聚合, 在實參表示打散 **kwargs:(表示的就是實參中按照關鍵字傳值把多餘的傳值以字典的方式呈現)在形參表示聚合, 在實參表示打散
26.is和==的區別
is和===意思是一樣的 :比較的是記憶體地址 ==:比較的是數值是否相等 is 比較的是兩個例項物件是不是完全相同,它們是不是同一個物件,佔用的記憶體地址是否相同。萊布尼茨說過:“世界上沒有兩片完全相同的葉子”,這個is正是這樣的比較,比較是不是同一片葉子(即比較的id是否相同,這id類似於人的身份證標識)。 == 比較的是兩個物件的內容是否相等,即記憶體地址可以不一樣,內容一樣就可以了。這裡比較的並非是同一片葉子,可能葉子的種類或者脈絡相同就可以了。預設會呼叫物件的 __eq__()方法。 總結: == 是比較這倆個人長的是不是一樣 is 是比較這倆個人是不是一個人
27.簡述Python的深淺拷貝以及應用場景?
淺拷貝: 不管多麼複雜的資料結構,只copy物件最外層本身,該物件引用的其他物件不變 記憶體裡兩個變數的地址是一樣的,一個改變,另外一個也改變。 深拷貝: 完全複製原資料的所有資料,記憶體中生成一套完全一樣的內容,只是值一樣,記憶體地址幣一樣, 一方修改,另一方不受影響 Python採用基於值得記憶體管理模式,賦值語句的執行過程是:首先把等號右側標識的表示式計算出來,然後在記憶體中找一個位置把值存放進去,最後建立變數並指向這個記憶體地址。Python中的變數並不直接儲存值,而是儲存了值的記憶體地址或者引用 簡單地說,淺拷貝只拷貝一層(如果有巢狀),深拷貝拷貝所有層。 一層的情況: import copy # 淺拷貝 li1 = [1, 2, 3] li2 = li1.copy() li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] # 深拷貝 li1 = [1, 2, 3] li2 = copy.deepcopy(li1) li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] 多層的情況: import copy # 淺拷貝 li1 = [1, 2, 3, [4, 5], 6] li2 = li1.copy() li1[3].append(7) print(li1, li2) # [1, 2, 3, [4, 5, 7], 6] [1, 2, 3, [4, 5, 7], 6] # 深拷貝 li1 = [1, 2, 3, [4, 5], 6] li2 = copy.deepcopy(li1) li1[3].append(7) print(li1, li2) # [1, 2, 3, [4, 5, 7], 6] [1, 2, 3, [4, 5], 6] 應用場景:專案中的配置檔案。
28.Python垃圾回收機制?
#python垃圾回收機制,主要使用"引數計數"來跟蹤和回收垃圾 #在"引數計數"的基礎上,通過"標記-清除"(mark and sweep)解決容器物件可能產生的迴圈引用問題 #通過"分代回收"以空間換時間的方法提高垃圾回收效率 #"引數計數" pyobject是每個物件必有的內容,其中ob_refcnt就是作為引用計數。 當一個物件有新的引用時,他的ob_refcnt就會增加, 當引用他的物件被刪除,他的ob_refcnt就會減少, 引用計數為零時,該物件的生命就結束了 優點:簡單,實時性 缺點:維護引用計數消耗資源,迴圈引用 #"標記-清除機制" 基本思路是,先按零分配,等到沒有空閒記憶體的時候,從暫存器和程式棧上的引用出發, 遍歷以物件為節點,以引用為邊構成的圖,把所有可以訪問到的物件打上標記, 然後清掃一遍記憶體空間,把所有沒標記的物件釋放 #"分代技術" 分代回收的整體思想是: 將系統中所有記憶體塊根據其存活時間劃分為不同的集合,每個集合就成為一個"代" 垃圾收集頻率隨著"代"的存活時間的增大而較小,存活時間通常利用經過幾次垃圾回收來度量
29.Python的可變型別和不可變型別?
可變型別:列表,字典,集合,資料發生改變時,記憶體地址不變
不可變型別:數字,字串,元祖,資料發生改變時,重新開闢了一個記憶體地址,記憶體地址不變
30.求結果:
v = dict.fromkeys(['k1','k2'],[]) v[‘k1’].append(666) print(v) v[‘k1’] = 777 print(v
anser:
# Python 字典(Dictionary) fromkeys()方法 # 描述 # Python 字典 fromkeys() 函式用於建立一個新字典,以序列 seq 中元素做字典的鍵, # value 為字典所有鍵對應的初始值。 # # 語法 # fromkeys()方法語法: # dict.fromkeys(seq[, value]) # 引數 # seq -- 字典鍵值列表。 # value -- 可選引數, 設定鍵序列(seq)的值。 # 返回值 # 該方法返回一個新字典。 v=dict.fromkeys(['k1','k2'],[]) # v = {'k1':'[]','k2':'[]'} v['k1'].append(666) #將列表k1的值變為[666],剛開始,k1和k2公用一個值[] # v:{'k1':'[666]','k2':'[666]'} print(v) v['k1']=777 #將k1的值變為777,列表不變。 # v:{'k1':'777','k2':'[666]'} print(v) d = {} dict.fromkeys("ab", [123,123,12,3,21,321,31]) # fromkeys 返回的新字典. 和d沒有關係 # {'a': [123, 123, 12, 3, 21, 321, 31], 'b': [123, 123, 12, 3, 21, 321, 31]} print(d) # {}
31求結果:
def num(): return [lambda x: i * x for i in range(4)] print([m(2) for m in num()])
此函式可變形為下圖:
[6, 6, 6, 6] # 匿名函式某面試題題詳解 def mu(): # 上邊函式拆解後是這種結構 l = [] # 定義一個列表 for i in range(4): # for迴圈4次 def fun(x): # 程式碼不執行 return i * x # 程式碼不執行 l.append(fun) # 列表中新增進去了4個未執行的函式,當列表中的函式被呼叫時,才會去記憶體中找i,此時的i是for迴圈的最後一位元素。 return l # 返回此列表
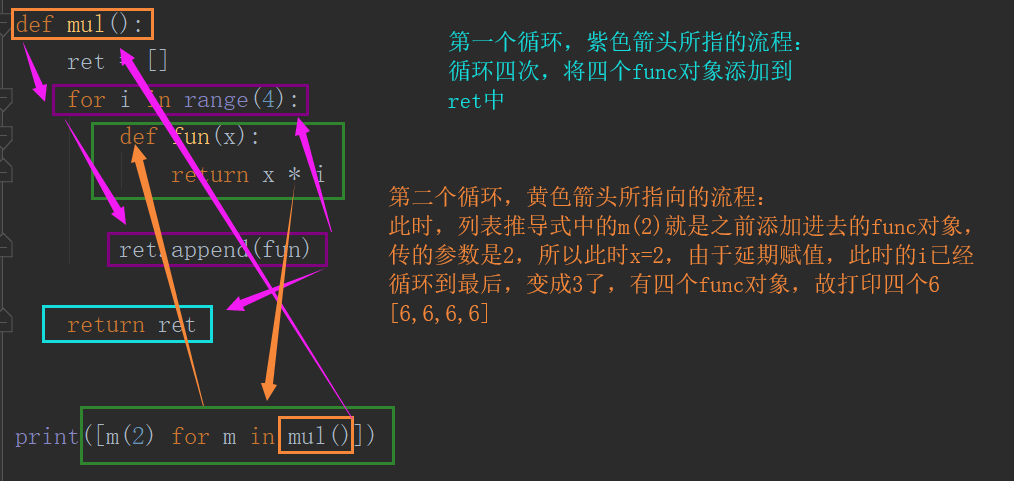
拓展
def num(): for i in range(5): yield lambda x:x*i print([m(2) for m in num()]) # [0, 2, 4, 6, 8] 生成器一次出來一個數據
def add(a, b): return a + b def test(): for i in range(6): yield i g = test() # 生成器 0,1,2,3,4,5 for n in [2, 100]: g = (add(n, j) for j in g) # 執行了兩遍 # n=2 # g = (add(n, j) for j in g) # n=100 # g = (add(n, j) for j in g) # n=15 # 將n變為15,則結果為[30, 31, 32, 33, 34, 35] print(list(g)) # [200, 201, 202, 203, 204, 205] """ 注意:生成器在不執行的時候,就是一堆程式碼 1.先將g = test()生成器放到記憶體中 2.迴圈兩遍for n in [2, 100]: 此時n=100 3.list(g)呼叫兩次 g = (add(n, j) for j in g) 注意:list(g)呼叫的是n=100的那個生成器g, n=100的那個生成器g的執行需要通過n=2的那個生成器(倒著執行) j的值是通過g = test()找到的,n的值是後者覆蓋前者 1.g呼叫兩次def add(a, b): # 順序執行 2.第一次a=n=100,b=0 3.第二次a=n=100,b=10=第一次呼叫def add(a, b):的值 """
32.列舉常見的內建函式?
float(x) # 把x轉換成浮點數 str(x) # 轉換成字串 list(x) # 轉換成列表 tuple(x) # 轉換成元組 進位制相互轉換 r= bin(10) #二進位制 r= int(10) #十進位制 r = oct(10) #八進位制 r = hex(10) #十六進位制 i= int("11",base=10)#進位制間的相互轉換base後跟 2/8/10/16 chr(x)//返回x對應的字元,如chr(65)返回‘A' ord(x)//返回字元對應的ASC碼數字編號,如ord('A')返回65 abs() #絕對值 input() # 程式互動 id() # 檢視記憶體地址 enumerate() #列舉 eval() #執行一個字串表示式 max() # 求最大 min() # 求最小 sum() # 求和 range() # 範圍 type() # 檢視資料型別 len() #獲取資料型別的長度 zip() sorted() reversed() filter()
# map:遍歷序列,為每一個序列進行操作,返回一個結果列表 l = [1, 2, 3, 4, 5, 6, 7] def pow2(x): return x * x res = map(pow2, l) print(list(res)) #[1, 4, 9, 16, 25, 36, 49] # reduce:對於序列裡面的所有內容進行累計操作 from functools import reduce def add(x, y): return x+y print(reduce(add, [1,2,3,4])) #10 # filter:對序列裡面的元素進行篩選,最終獲取符合條件的序列 l = [1, 2, 3, 4, 5] def is_odd(x): # 求奇數 return x % 2 == 1 print(list(filter(is_odd, l))) #[1, 3, 5] # zip:用於將可迭代的物件作為引數,將物件中對應的元素打包成一個個元組,然後返回由這些元組組成的列表 a = [1,2,3] b=[4,5,6] c=[4,5,6,7,8] ziped1 = zip(a,b) print('ziped1>>>',list(ziped1)) #[(1, 4), (2, 5), (3, 6)] ziped2 = zip(a,c) print('ziped2>>>',list(ziped2)) #[(1, 4), (2, 5), (3, 6)],以短的為基準
33.filter、map、reduce的作用?
filter:對於序列中的元素進行篩選,最終獲取符合條件的序列
map:遍歷序列,對序列中每個元素進行操作,最終獲取新的序列
reduce:對於序列內所有元素進行累計操作
34.一行程式碼實現9*9乘法表
print("\n".join("\t".join(["%s*%s=%s" %(x,y,x*y) for y in range(1, x+1)]) for x in range(1, 10)) ) print('\n'.join([''.join(['%s*%s=%2s' % (j,i,i*j) for j in range(1+i+1)])for i in range(1,10)]))
35.如何安裝第三方模組?以及用過哪些第三方模組?
1.在pycharm的settings中手動下載,新增第三方模組 2輸入cmd,在終端中pip install +模組名 安裝 用過的第三方模組:requests,pymysql,DBUtils - pip包管理器 pip install 模組名 - 原始碼安裝 - 下載->解壓->cd 到對應路徑 - python setup.py build - python setup.py install requests selenium urllib3 pymysql redis celery beautifulsoup4 sqlarchmy xlrd gevent
36.至少列舉8個常用模組都有那些?
re:正則
os:提供了一種方便的 作業系統函式的方法
sys:可供訪問由直譯器使用或維護的變數和直譯器記性互動的函式
random:隨機數
json:序列化
time:時間
37.re的match和search區別?
38.什麼是正則的貪婪匹配?
39.求結果: a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
40.求結果: a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
41.def func(a,b=[]) 這種寫法有什麼坑?
42.如何實現 “1,2,3” 變成 [‘1’,’2’,’3’] ?
43.如何實現[‘1’,’2’,’3’]變成[1,2,3] ?
44.比較: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的區別?
45.如何用一行程式碼生成[1,4,9,16,25,36,49,64,81,100] ?
46.一行程式碼實現刪除列表中重複的值 ?
47.如何在函式中設定一個全域性變數 ?
48.logging模組的作用?以及應用場景?
49.請用程式碼簡答實現stack 。
50.常用字串格式化哪幾種?
51.簡述 生成器、迭代器、可迭代物件 以及應用場景?
52.用Python實現一個二分查詢的函式。
53.談談你對閉包的理解?
54.os和sys模組的作用?
55.如何生成一個隨機數?
56.如何使用python刪除一個檔案?
57.談談你對面向物件的理解?
58.Python面向物件中的繼承有什麼特點?
59.面向物件深度優先和廣度優先是什麼?
60.物件中super的作用?
61.是否使用過functools中的函式?其作用是什麼?
62.列舉面向物件中帶爽下劃線的特殊方法,如:__new__、__init__
63.如何判斷是函式還是方法?
64.靜態方法和類方法區別?
65.列舉面向物件中的特殊成員以及應用場景
66.1、2、3、4、5 能組成多少個互不相同且無重複的三位數
67.什麼是反射?以及應用場景?
68.metaclass作用?以及應用場景?
69.用盡量多的方法實現單例模式。
70.裝飾器的寫法以及應用場景。
71.異常處理寫法以及如何主動跑出異常(應用場景)
72.什麼是面向物件的mro
73.isinstance作用以及應用場景?
74.寫程式碼並實現:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would have exactly one solution, and you may not use the same element twice. Example: Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1]
75.json序列化時,可以處理的資料型別有哪些?如何定製支援datetime型別?
76.json序列化時,預設遇到中文會轉換成unicode,如果想要保留中文怎麼辦?
77.什麼是斷言?應用場景?
78.有用過with statement嗎?它的好處是什麼?
79.使用程式碼實現檢視列舉目錄下的所有檔案。
80.簡述 yield和yield from關鍵字。
第二部分 網路程式設計和併發(34題)
1 簡述 OSI 七層協議。
物理層:主要基於電器特性發送高低電壓(1,0),裝置有集線器,中繼器,雙絞線等,單位bit
資料鏈路層:定義了電訊號的分組方式,裝置:交換機,網絡卡,網橋,單位:幀
網路層:主要功能是將網路地址翻譯成對應的實體地址,裝置:路由
傳輸層:建立埠之間的通訊,tcp,udp協議
會話層:建立客戶端與服務端連結
表示層:對來自應用層的命令和資料進行解釋,按照一定格式傳給會話層。如編碼,資料格式轉換,加密解密,壓縮解壓等
應用層:規定應用程式的資料格式
2.什麼是C/S和B/S架構?
C/S架構: client和 server端的服務架構 B/S架構: 隸屬於C/S架構,Broswer端(網頁端)與server端 優點:統一了所有應用的入口,方便,輕量級
3.簡述 三次握手、四次揮手的流程。
三次握手:
客戶端向服務端發起一次請求
服務端確認並且恢復客戶端
客戶端檢驗確認請求,建立連線
四次揮手:
客戶端向服務端發一次請求
服務端回覆客戶端(斷開客戶端)
服務端再次向客戶端發起請求(告訴客戶端可以斷開了)
客戶端確認請求
4.什麼是arp協議?
5.TCP和UDP的區別?
6.什麼是區域網和廣域網?
7.為何基於tcp協議的通訊比基於udp協議的通訊更可靠?
8.什麼是socket?簡述基於tcp協議的套接字通訊流程。
9.什麼是粘包? socket 中造成粘包的原因是什麼? 哪些情況會發生粘包現象?
10.多路複用的作用?
11.什麼是防火牆以及作用?
12.select、poll、epoll 模型的區別?
13.簡述 程序、執行緒、協程的區別 以及應用場景?
14.GIL鎖是什麼鬼?
15.Python中如何使用執行緒池和程序池?
16.threading.local的作用?
17.程序之間如何進行通訊?
18.什麼是併發和並行?
19.程序鎖和執行緒鎖的作用?
20.解釋什麼是非同步非阻塞?
21.路由器和交換機的區別?
22.什麼是域名解析?
23.如何修改本地hosts檔案?
24.生產者消費者模型應用場景及優勢?
25.什麼是cdn?
26.LVS是什麼及作用?
27.Nginx是什麼及作用?
28.keepalived是什麼及作用?
29.haproxy是什麼以及作用?
30.什麼是負載均衡?
31.什麼是rpc及應用場景?
32.簡述 asynio模組的作用和應用場景。
33.簡述 gevent模組的作用和應用場景。
34twisted框架的使用和應用?
資料庫和快取(46題)
1.列舉常見的關係型資料庫和非關係型都有那些?
關係型:
sqlite,db2,oracle,access,SQLserver,MYSQL
sql語句通用,需要有表結構
非關係型:
mongodb,redis,memcache
非關係型資料庫是key-value儲存的,沒有表結構
2.MySQL常見資料庫引擎及比較?
MYisam: 支援全文索引 查詢速度相對較快 支援表鎖 表鎖:select * from tb for update;(鎖:for update) InnoDB: 支援會務 支援行鎖,表鎖 表鎖:select * from tb for update; (鎖:for update) 行鎖:select id ,name from tb where id=2,for update; (鎖:for update)
3.簡述資料三大正規化?
資料庫的三大特性:
實體:表
屬性:表中的資料(欄位)
關係:表與表之間的關係
資料庫設計三大規範:
第一正規化(1NF):
資料表中的每一列(每個欄位),必須是不可拆分的最小單元
也就是確認每一列的原子性
第二正規化(2NF):
滿足第一正規化,要求表中的所有列,都必須依賴主鍵
而不能有任何一列,與主鍵沒有關係,也就是說一個表只描述一件事情
第三正規化(3NF):
必須滿足第二正規化
要求:表中每一列只與主鍵直接相關,而不是間接相關(表中每一列只能依賴於主鍵)
4.什麼是事務?MySQL如何支援事務?
5.簡述資料庫設計中一對多和多對多的應用場景?
6.如何基於資料庫實現商城商品計數器?
7.常見SQL(必備)
詳見武沛齊部落格:https://www.cnblogs.com/wupeiqi/articles/5729934.html
8.如何高效的找出redis中以"new"開頭的key?
9.簡述觸發器、函式、檢視、儲存過程?
10.MySQL索引種類
11.索引在什麼情況下遵循最左字首的規則?
12.主鍵和外來鍵的區別?
13.MySQL常見的函式?
14.列舉 建立索引但是無法命中索引的8種情況。
15.如何開啟慢日誌查詢?
16.資料庫匯入匯出命令(結構+資料)?
17.資料庫優化方案?
18.char和varchar的區別?
19.簡述MySQL的執行計劃?
20.在對name做了唯一索引前提下,簡述以下區別:
select * from tb where name = ‘Oldboy-Wupeiqi’
select * from tb where name = ‘Oldboy-Wupeiqi’ limit 1
21.1000w條資料,使用limit offset 分頁時,為什麼越往後翻越慢?如何解決?
22.什麼是索引合併?
23.什麼是覆蓋索引?
24.簡述資料庫讀寫分離?
25.簡述資料庫分庫分表?(水平、垂直)
26.redis和memcached比較?
27.redis中資料庫預設是多少個db 及作用?
28.python操作redis的模組?
29.如果redis中的某個列表中的資料量非常大,如果實現迴圈顯示每一個值?
30.redis如何實現主從複製?以及資料同步機制?
31.redis中的sentinel的作用?
32.如何實現redis叢集?
33.redis中預設有多少個雜湊槽?
34.簡述redis的有哪幾種持久化策略及比較?
35.列舉redis支援的過期策略。
36.MySQL 裡有 2000w 資料,redis 中只存 20w 的資料,如何保證 redis 中都是熱點資料?
37.寫程式碼,基於redis的列表實現 先進先出、後進先出佇列、優先順序佇列。
38.如何基於redis實現訊息佇列?
39.如何基於redis實現釋出和訂閱?以及釋出訂閱和訊息佇列的區別?
40.什麼是codis及作用?
41.什麼是twemproxy及作用?
42.寫程式碼實現redis事務操作。
43redis中的watch的命令的作用?
44.基於redis如何實現商城商品數量計數器?
45.簡述redis分散式鎖和redlock的實現機制。
46.什麼是一致性雜湊?Python中是否有相應模組?
前端,框架和其他(155題)
1.談談你對http協議的認識。
超文字傳輸協議 特點: 無狀態:請求響應之後,再次發起請求時,不認識 短連結:一次請求和一次響應就斷開連線 格式: 通過/r/n分割 請求頭和請求體之間:/r/n/r/n分割
2.談談你對websocket協議的認識。
什麼是websocket? 是給瀏覽器新建的一套協議 協議規定:建立連線後不斷開 通過"/r/n"分割,讓客戶端和服務端建立連線後不斷開,驗證+資料加密 本質: 一個建立後不斷開的socket 當連線成功後: 客戶端會自動向服務端傳送訊息 服務端接收後,會對該資料加密:base64(sha1(swk+magic_string)) 構造響應頭 傳送給客戶端 建立雙工通道,進行收發資料 框架中是如何使用websocket的? django:channel flask:gevent-websocket tornado:內建 websocket的優缺點 有點:程式碼簡單,不在重複建立連結 缺點:相容性沒有長輪詢好,如IE會不相容
3.什麼是magicstring ?
它是websocket裡面的用於加密的一個字串,全球唯一 客戶端向請求端傳送訊息時,會有一個sec-websocket-key和magic string 的隨機字串(魔法字串) 服務端收到訊息後,會把他拼接成一個新的key字串,先進行sha1演算法,後進行base64進行加密,確保資訊的安全性。
4.如何建立響應式佈局?
a.可以通過引用Bootstrap實現 b.通過看Bootstrap原始碼檔案,可知其本質就是通過css實現的 <style> /*瀏覽器視窗寬度大於768,背景色變為 green*/ @media (min-width: 768px) { .pg-header{ background-color: green; } } /*瀏覽器視窗寬度大於992,背景色變為 pink*/ @media (min-width: 992px) { .pg-header{ background-color: pink; } } </style> </head> <body> <div class="pg-header"></div> </body>
5.你曾經使用過哪些前端框架?
Jquery,Vue,Bootstrap
6.什麼是ajax請求?並使用jQuery和XMLHttpRequest物件實現一個ajax請求。
7.如何在前端實現輪訓?
8.如何在前端實現長輪訓?
9.vuex的作用?
10.vue中的路由的攔截器的作用?
11.axios的作用?
12.列舉vue的常見指令。
13.簡述jsonp及實現原理?
14.是什麼cors ?
15列舉Http請求中常見的請求方式?
16.列舉Http請求中的狀態碼?
17.列舉Http請求中常見的請求頭?
18.看圖寫結果:

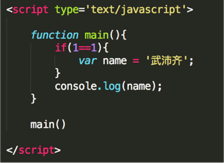
19.看圖寫結果:
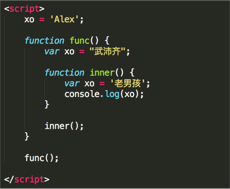
20.看圖寫結果:
21.看圖寫結果:

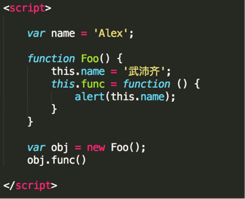
22.看圖寫結果:
23.看圖寫結果:

24.django、flask、tornado框架的比較?
25.什麼是wsgi?
26.django請求的生命週期?
27.列舉django的內建元件?
28.列舉django中介軟體的5個方法?以及django中介軟體的應用場景?
29.簡述什麼是FBV和CBV?
30.django的request物件是在什麼時候建立的?
31.如何給CBV的程式新增裝飾器?
32.列舉django,orm中所有的方法(QuerySet物件的所有方法)
33.only和defer的區別?
34.select_related和prefetch_related的區別?
35.filter和exclude的區別?
36.列舉django orm中三種能寫sql語句的方法。
37.django orm中如何設定讀寫分離?
38.F和Q的作用?
39.values和values_list的區別?
40.如何使用django orm批量建立資料?
41.django的Form和ModeForm的作用?
42.django的Form元件中,如果欄位中包含choices引數,請使用兩種方式實現資料來源實時更新。
43.django的Model中的ForeignKey欄位中的on_delete引數有什麼作用?
44.django中csrf的實現機制?
45.django如何實現websocket?
46.基於django使用ajax傳送post請求時,都可以使用哪種方法攜帶csrftoken?
47.django中如何實現orm表中新增資料時建立一條日誌記錄。
48.django快取如何設定?
49.django的快取能使用redis嗎?如果可以的話,如何配置?
50.django路由系統中name的作用?
51.django的模板中filter和simple_tag的區別?
52.django - debug - toolbar的作用?
53.django中如何實現單元測試?
54.解釋orm中db first和code first的含義?
55.django中如何根據資料庫表生成model中的類?
56.使用orm和原生sql的優缺點?
57.簡述MVC和MTV
58.django的contenttype元件的作用?
59.談談你對restfull 規範的認識?
60.介面的冪等性是什麼意思?
61.什麼是RPC?
62.Http和Https的區別?
63.為什麼要使用django rest framework框架?
64.django rest framework框架中都有那些元件?
65.django rest framework框架中的檢視都可以繼承哪些類?
66.簡述 django rest framework框架的認證流程。
67.django rest framework如何實現的使用者訪問頻率控制?
68.Flask框架的優勢?
69.Flask框架依賴元件?
70.Flask藍圖的作用?
71.列舉使用過的Flask第三方元件?
72.簡述Flask上下文管理流程?
73.Flask中的g的作用?
74.Flask中上下文管理主要涉及到了那些相關的類?並描述類主要作用?
75.為什麼要Flask把Local物件中的的值stack 維護成一個列表?
76.Flask中多app應用是怎麼完成?
77.在Flask中實現WebSocket需要什麼元件?
78.wtforms元件的作用?
79.Flask框架預設session處理機制?
80.解釋Flask框架中的Local物件和threading.local物件的區別?
81.Flask中blinke是什麼?
82.SQLAlchemy中的session和scoped_session的區別?
83.SQLAlchemy如何執行原生SQL?
84.ORM的實現原理?
85.DBUtils模組的作用?
86.以下SQLAlchemy的欄位是否正確?如果不正確請更正:
from datetime import datetime from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime Base = declarative_base() class UserInfo(Base): __tablename__ = 'userinfo' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(64), unique=True) ctime = Column(DateTime, default=datetime.now())
87.SQLAchemy中如何為表設定引擎和字元編碼?
88.SQLAchemy中如何設定聯合唯一索引?
89.簡述Tornado框架的特點。
90.簡述Tornado框架中Future物件的作用?
91.Tornado框架中如何編寫WebSocket程式?
92.Tornado中靜態檔案是如何處理的?
如: <link href="{{static_url("commons.css")}}" rel="stylesheet" />
93.Tornado操作MySQL使用的模
94.Tornado操作redis使用的模
95.簡述Tornado框架的適用
96.git常見命令作用:
97.簡述以下git中stash命令作用以及相關其他命令。
98.git中 merge和rebase命令的區別。
99.公司如何基於git做的協同開發?
100.如何基於git實現程式碼review?
101.git如何實現v1 .0 、v2.0等版本的管理?
102.什麼是gitlab?
103.github和gitlab的區別?
104.如何為github上牛逼的開源專案貢獻程式碼?
105.git中.gitignore檔案的作用?
106.什麼是敏捷開發?
107.簡述 jenkins工具的作用?
108.公司如何實現程式碼釋出?
109.簡述RabbitMQ、Kafka、ZeroMQ的區別?
110.RabbitMQ如何在消費者獲取任務後未處理完前就掛掉時,保證資料不丟失?
111.RabbitMQ如何對訊息做持久化?
112.RabbitMQ如何控制訊息被消費的順序?
113.以下RabbitMQ的exchange type分別代表什麼意思?如:fanout、direct、topic。
114.簡述celery是什麼以及應用場景?
115.簡述celery執行機制。
116.celery如何實現定時任務?
117.簡述celery多工結構目錄?
118.celery中裝飾器 @ app.task和 @ shared_task的區別?
119.簡述requests模組的作用及基本使用?
120.簡述beautifulsoup模組的作用及基本使用?
121.簡述seleninu模組的作用及基本使用?
122.scrapy框架中各元件的工作流程?
123.在scrapy框架中如何設定代理(兩種方法)?
124.scrapy框架中如何實現大檔案的下載?
125.scrapy中如何實現限速?
126.scrapy中如何實現暫定爬蟲?
127.scrapy中如何進行自定製命令?
128.scrapy中如何實現的記錄爬蟲的深度?
129.scrapy中的pipelines工作原理?
130.scrapy的pipelines如何丟棄一個item物件?
131.簡述scrapy中爬蟲中介軟體和下載中介軟體的作用?
132.scrapy - redis元件的作用?
133.scrapy - redis元件中如何實現的任務的去重?
134.scrapy - redis的排程器如何實現任務的深度優先和廣度優先?
135.簡述vitualenv及應用場景?
136.簡述pipreqs及應用場景?
137.在Python中使用過什麼程式碼檢查工具?
138.簡述saltstack、ansible、fabric、puppet工具的作用?
139.B Tree和B + Tree的區別?
140.請列舉常見排序並通過程式碼實現任意三種。
141.請列舉常見查詢並通過程式碼實現任意三種。
142.請列舉你熟悉的設計模式?
143.有沒有刷過leetcode?
144.列舉熟悉的的Li