
No.3 ssd-caffe(2):訓練ssd-caffe模型:(以VOC資料集為例)
2.訓練ssd-caffe模型:(以VOC資料集為例)
使用caffe進行目標檢測,我們的需要標註了標籤的圖片作為訓練樣本,訓練模型。推薦使用開源的標註工具labelimg,來對我們的圖片進行標註。標註之後,會產生.xml檔案,用於標識圖片中物體的具體資訊。
這裡,我們以VOC格式的資料為示例:
VOC的資料格式,主要有三個重要的資料夾:Annotations、ImageSets和JPEGImages
Annotations: 存放.xml標註檔案
ImageSets/Main: 存放
train.txt、test.txt、trainval.txt、val.txttest.txt中儲存的是測試所用的所有樣本的名字,不過沒有後綴(下同),一般測試的樣本數量佔總資料集的50%train.txt中儲存的是訓練所用的樣本名,樣本數量通常佔trainval的50%左右val.txt中儲存的是驗證所用的樣本名,數量佔trainval的50%左右trainval.txt中儲存的是訓練驗證樣本,是上面兩個的總和,一般數量佔總資料集的50%
生成上述文字的程式碼如下:
import os
import random
trainval_percent = 0.66
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt' 由於caffe只能處理lmdb格式的資料,如果你有自己的資料想要放在caffe上進行訓練,方式如下:
- 自定義資料和VOC資料格式相同:直接使用VOC的資料集轉換的程式碼轉換為lmdb
- 自定義的資料和VOC的資料格式有出入:自己寫程式碼或者修改原始碼
src/caffe/util/io.cpp,轉換為lmdb格式
訓練步驟如下,以mydataset為例:
分別建立
examples/mydataset,data/mydataset,data/VOCdevkit/mydataset三個資料夾:data/VOCdevkit/mydataset:將剛剛生成的Annocations等幾個資料夾複製進去data/mydataset:將data/VOC0712下的create_list.sh,create_data.sh,labelmap_voc.prototxt三個檔案拷貝到該資料夾create_list.sh:根據之前生成的ImageSets/Main中的train.txt等檔案,生成具體的檔案路徑資訊等。執行該資料夾會在當前目錄生成幾個txt檔案更改
create_list.sh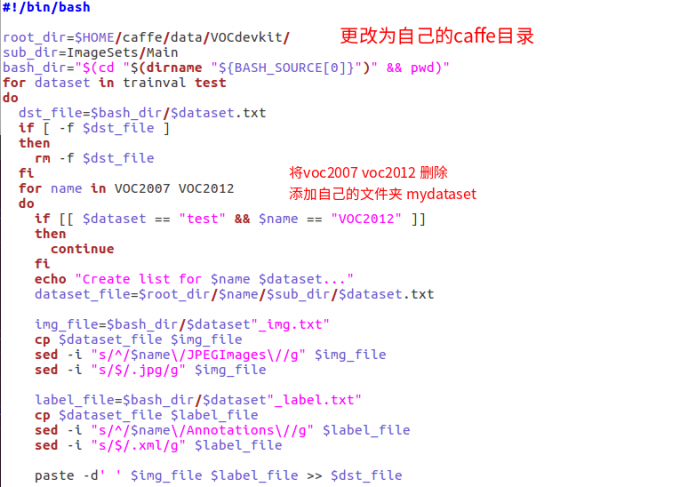
create_data.sh:生成lmdb檔案,執行該資料夾,會在examples/mydataset生成更改
create_data.sh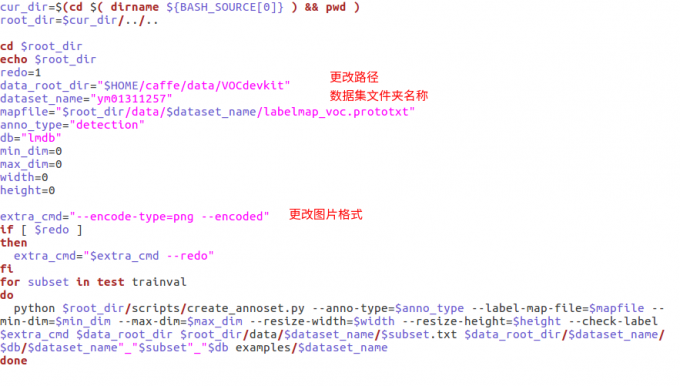
在ssd-caffe的根目錄,執行如下命令:
./data/mydataset/create_list.sh ./data/mydataset/create_data.sh即可生成上述提到的檔案。若執行兩個.sh指令碼檔案錯誤,則刪除剛剛生成的檔案,debug後重新執行
執行成功以後,在
examples/mydataset即生成lmdb檔案複製
examples/ssd/路徑下的ssd_pascal.py檔案到example/mydataset下,修改相應引數:修改所有資料夾路徑為自己的路徑
如果本機視訊記憶體太小,修改
batch_size為8修改標籤個數
num_classes為自己的種類n+1
(1即為新增的backgroud標籤,識別為背景。另外,我們的xml標籤檔案中不能出現編號為0的backgrouond標註,否則會報錯。這個問題在ssd-caffe的issue上也有提到,至今沒有解決)
- 修改
max_iter等引數,將迭代次數減小,也可以不修改使用預設
在ssd-caffe根目錄下執行
python example/mydataset/ssd_pascal.py等待模型執行結束
複製
examples/ssd/路徑下的score_ssd_pascal.py檔案到example/mydataset下,修改相應檔案路徑,即可測試模型:python example/mydataset/score_ssd_pascal.py
3. 呼叫訓練完成的模型,對單張圖片進行測試:
我們訓練完的模型應該儲存在以下路徑:
models/VGGNet/mydataset/SSD_300X300
.
├── deploy.prototxt
├── solver.prototxt #超引數
├── test.prototxt
├── train.prototxt
├── VGG_mydataset_SSD_300x300_iter_55.caffemodel
└── VGG_mydataset_SSD_300x300_iter_55.solverstate
將example/ssd路徑下的ssd_detect.py檔案複製到example/mydataset下,將輸入,輸出的檔案路徑修改為自己的路徑(其中包含網路定義,模型檔案,標籤檔案,測試圖片,輸出圖片等)
P.S. 文章不妥之處還望指正