
分散式系統的架構演進
目錄
分散式系統的意義
- 升級單機處理能力的價效比越來越低:單機的處理能力主要依靠 CPU、記憶體、磁碟。通過更換硬體做垂直擴充套件的方式來提升效能,成本會越來越高。
- 單機處理能力存在瓶頸:單機處理能力存在瓶頸,CPU、記憶體都會有自己的效能瓶頸,也就是說就算你是土豪不惜成本去提升硬體,但是硬體的發展速度和效能是有限制的。
- 穩定性和可用性這兩個指標很難達到:單機系統存在可用性和穩定性的問題,這兩個指標又是我們必須要去解決的
背景案例:阿里巴巴在 2009 年發起了一項"去 IOE"運動
IOE 指的是 IBM 小型機、Oracle 資料庫、EMC 的高階儲存。2009 年“去 IOE”戰略透露,到 2013 年 5 月 17 日最後一臺 IBM小型機在支付寶下線。
為什麼要去IOE?
阿里巴巴過去一直採用的是 Oracle 資料庫,並利用小型機和高階儲存裝置提供高效能的資料處理和儲存服務。隨著業務的不斷髮展,資料量和業務量呈爆發性增長,傳統的集中式
Oracle 資料庫架構在擴充套件性方面遭遇瓶頸。
傳統的商業資料庫軟體(Oracle,DB2),多以集中式架構為主, 這些傳統資料庫軟體的最大特點就是將所有的資料都集中在 一個數據庫中,依靠大型高階裝置來提供高處理能力和擴充套件性。集中式資料庫的擴充套件性主要採用向上擴充套件(Scale up)的方式, 通過增加 CPU,記憶體,磁碟等方式提高處理能力。
分散式架構的常見概念
- 叢集
小飯店原來只有一個廚師,切菜洗菜備料炒菜全乾。後來客人多了,廚房一個廚師忙不過來,又請了個廚師,兩個廚師都能炒一樣的菜,這兩個廚師的關係是叢集
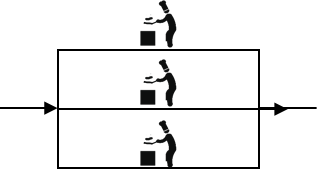
- 分散式
為了讓廚師專心炒菜,把菜做到極致,又請了個配菜師負責切菜,備菜,備料,廚師和配菜師的關係是分散式,一個配菜師也忙不過來了,又請了個配菜師,兩個配菜師關係是叢集
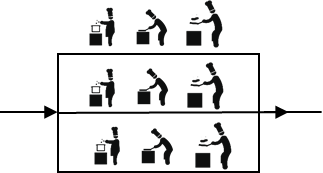
- 節點
節點是指一個可以獨立按照分散式協議完成一組邏輯的程式個體。在具體的專案中,一個節點表示的是一個作業系統上的程序。
- 副本機制
副本(replica/copy)指在分散式系統中為資料或服務提供的冗餘。
資料副本指在不同的節點上持久化同一份資料,當出現某一個節點的資料丟失時,可以從副本上讀取到資料。資料副本是分散式系統中解決資料丟失問題的唯一手段。
服務副本表示多個節點提供相同的服務,通過主從關係來實現服務的高可用方案
- 中介軟體
中介軟體位於作業系統提供的服務之外,又不屬於應用,他是位於應用和系統層之間為開發者方便的處理通訊、輸入輸出的一類軟體,能夠讓使用者關心自己應用的部分。
架構的發展過程
一個成熟的大型網站系統架構並不是一開始就設計的非常完美,也不是一開始就具備高效能、高可用、安全性等特性,而是隨著使用者量的增加、業務功能的擴充套件逐步完善演變過來的。在這個過程中,開發模式、技術架構等都會發生非常大的變化。而針對不同業務特徵的系統,會有各自的側重點。
- 比如像淘寶這類的網站,要解決的是海量商品搜尋、下單、支付等問題;
- 像騰訊,要解決的是數億級別使用者的實時訊息傳輸;
- 百度所要解決的是海量資料的搜尋。每一個種類的業務都有自己不同的系統架構。我們簡單模擬一個架構演變過程。
我們以 javaweb 為例,來搭建一個簡單的電商系統,從這個系統中來看系統的演變歷史;要注意的是,接下來的演示模型, 關注的是資料量、訪問量提升,網站結構發生的變化, 而不是具體關注業務功能點。其次,這個過程是為了讓大家更好的瞭解網站演進過程中的一些問題和應對策略。
假如我們系統具備以下功能:
使用者模組:使用者註冊和管理
商品模組:商品展示和管理
交易模組:建立交易及支付結算
- 階段一,單應用架構

網站的初期也可以認為是網際網路發展的早起,我們經常會在單機上跑我們所有的程式和軟體。把所有軟體和應用都部署在一臺機器上,這樣就完成一個簡單系統的搭建,這個時候的講究的是效率
- 階段二,應用伺服器和資料庫伺服器分離

隨著網站的上線,訪問量逐步上升,伺服器的負載慢慢提高, 在伺服器還沒有超載的時候,我們應該做好規劃,提升網站的負載能力。假如程式碼層面的優化已經沒辦法繼續提高,在不提高單臺機器的效能,增加機器是一個比較好的方式,投入產出比非常高。這個階段增加機器的主要目的是講 web 伺服器和資料庫伺服器拆分,這樣不僅提高了單機的負載能力,也提高了容災能力
- 階段三,應用伺服器叢集-應用伺服器負載告警,如何讓應用伺服器走向叢集

隨著訪問量的繼續增加,單臺應用伺服器已經無法滿足需求。在假設資料庫伺服器還沒有遇到效能問題的時候,我們可以增加應用伺服器,通過應用伺服器叢集將使用者請求分流到各個伺服器中,從而繼續提升負載能力。此時多臺應用伺服器之間沒有直接的互動,他們都是依賴資料庫各自對外提供服務
架構發展到這個階段,各種問題也會慢慢呈現
- 使用者請求由誰來轉發到具體的應用伺服器?
- 使用者如果每次訪問到的伺服器不一樣, 那麼如何維護session?
- 階段四,資料庫壓力變大,資料庫讀寫分離

架構演變到這裡,並不是終點。上面我們把應用層的效能拉上來了, 但是資料庫的負載也在慢慢增大,那麼怎麼去提高資料庫層面的負載呢?有了前面的思路以後,自然會想到增加伺服器。但是假如我們單純的把資料庫一分為二,然後對於後續資料庫的請求,分別負載到兩臺資料庫伺服器上,那麼一定會造成資料庫不統一的問題。所以我們一般先考慮讀寫分離的方式
這個架構的變化會帶來幾個問題
- 主從資料庫之間的資料同步 :可以使用 mysql 自帶的master-slave 方式實現主從複製
- 對應資料來源的選擇 : 採用第三方資料庫中介軟體,例如mycat
- 階段五,使用搜索引擎緩解讀庫的壓力

資料庫做讀庫的話,嚐嚐對模糊查詢效率不是特別好,像電商類的網站,搜尋是非常核心的功能,即便是做了讀寫分離,這個問題也不能有效解決。那麼這個時候就需要引入搜尋引擎了
使用搜索引擎能夠大大提高我們的查詢速度,但是同時也會帶來一些附加的問題,比如維護索引的構建。
- 階段六,引入快取機制緩解資料庫的壓力

隨著訪問量的持續增加,逐漸出現許多使用者訪問統一部分內容的情況,對於這些熱點資料,沒必要每次都從資料庫去讀取,我們可以使用快取技術,比如 memcache、redis 來作為我們應用層的快取; 另外在某些場景下,比如我們對使用者的某些IP 的訪問頻率做限制, 那這個放記憶體中又不合適,放資料庫又太麻煩,這個時候可以使用Nosql 的方式比如mongDB 來代替傳統的關係型資料庫
- 階段七,資料庫的水平/垂直拆分
我們的網站演進的變化過程,交易、商品、使用者的資料都還在同一個資料庫中,儘管採取了增加快取,讀寫分離的方式,但是隨著資料庫的壓力持續增加,資料庫的瓶頸仍然是個最大的問題。因此我們可以考慮對資料的垂直拆分和水平拆分
垂直拆分:把資料庫中不同業務資料拆分到不同的資料庫

水平拆分:把同一個表中的資料拆分到兩個甚至跟多的資料庫中, 水平拆分的原因是某些業務資料量已經達到了單個數據庫的瓶頸, 這時可以採取講表拆分到多個數據庫中

- 階段八,應用的拆分
隨著業務的發展,業務越來越多,應用的壓力越來越大。工程規模也越來越龐大。這個時候就可以考慮講應用拆分,按照領域模型講我們的使用者、商品、交易拆分成多個子系統
這樣拆分以後,可能會有一些相同的程式碼,比如使用者操作,在商品和交易都需要查詢,所以會導致每個系統都會有使用者查詢訪問相關操作。這些相同的操作一定是要抽象出來,否則就會是一個坑。所以通過走服務化路線的方式來解決

那麼服務拆分以後,各個服務之間如何進行遠端通訊呢?
通過RPC 技術,比較典型的有:webservice、hessian、http、RMI 等等,前期通過這些技術能夠很好的解決各個服務之間通訊問題,but, 網際網路的發展是持續的,所以架構的演變和優化還在持續。
分散式系統的馮洛伊曼模型

前面我們講過經典理論-馮.諾依曼體系,計算機硬體由運算器、控制器、儲存器、輸入裝置、輸出裝置五大部分組成。不管架構怎麼變化,計算機仍沒有跳出該體系的範疇;
- 輸入裝置
在分散式系統架構中,輸入裝置可以分兩類,第一類是互相連線的多個節點,在接收其他節點傳來的資訊作為該節點的輸入;另一種就是傳統意義上的人機互動的輸入裝置了
- 輸出裝置
輸出和輸入類似,也有兩種,一種是系統中的節點向其他節點傳輸資訊時,該節點可以看作是輸出裝置;另一種就是傳統意義上的人際互動的輸出裝置,比如使用者的終端
- 控制器
在單機中,控制器指的是 CPU 中的控制器,在分散式系統中,控制器主要的作用是協調或控制節點之間的動作和行為;比如硬體負載均衡器;LVS 軟負載;規則伺服器等
- 運算器
在分散式系統中,運算器是由多個節點來組成的。運用多個節點的計算能力來協同完成整體的計算任務
- 儲存器
在分散式系統中,我們需要把承擔儲存功能的多個節點組織在一起, 組成一個整體的儲存器;比如資料庫、redis(key-value 儲存)
分散式系統的難點
毫無疑問,分散式系統對於集中式系統而言,在實現上會更加複雜。分散式系統將會是更難理解、設計、構建 和管理的,同時意味著應用程式的根源問題更難發現。
- 三態
在集中式架構中,我們呼叫一個介面返回的結果只有兩種, 成功或者失敗,但是在分散式領域中,會出現“超時”這個狀態。
- 分散式事務
這是一個老生常談的問題,我們都知道事務就是一些列操作的原子性保證,在單機的情況下,我們能夠依靠本機的資料庫連線和元件輕易做到事務的控制,但是分散式情況下,業務原子性操作很可能是跨服務的,這樣就導致了分散式事務,例如 A 和B 操作分別是不同服務下的同一個事務操作內的操作,A 呼叫B,A 如果可以清楚的知道 B 是否成功提交從而控制自身的提交還是回滾操作,但是在分散式系統中呼叫會出現一個新狀態就是超時,就是 A 無法知道B 是成功還是失敗,這個時候 A 是提交本地事務還是回滾呢?
1.如果強行保證事務一致性,可以採取分散式鎖,但是那樣會增加系統複雜度而且會增大系統的開銷,而且事務跨越的服務越多, 消耗的資源越大,效能越低
2,最好的解決方案就是避免分散式事務:事物操作在一個service中處理。
3,還有一種解決方案就是重試機制,但是重試如果不是查詢介面,必然涉及到資料庫的變更,如果第一次呼叫成功但是沒返回成功結果,那呼叫方第二次呼叫對呼叫方來說依然是重試,但是 對於被呼叫方來說是重複呼叫,例如 A 向B 轉賬,A-100,B + 100,這樣會導致 A 扣了 100,而 B 增加 200。這樣的結果不是我們期望的,因此需在要寫入的介面做冪等設計。多次呼叫 和單次呼叫是一樣的效果。通常可以設定一個唯一鍵,在寫入 的時候查詢是否已經存在,避免重複寫入。但是冪等設計的一 個前提就是服務是高可用,否則無論怎麼重試都不能呼叫返回 一個明確的結果呼叫方會一直等待,雖然可以限制重試的次數, 但是這已經進入了異常狀態了,甚至到了極端情況還是需要人肉補償處理。其實根據 CAP 和 BASE 理論,不可能在高可用分散式情況下做到一致性,一般都是最終一致性保證。
- 負載均衡
每個服務單獨部署,為了達到高可用,每個服務至少是兩臺機器,因為網際網路公司一般使用可靠性不是特別高的普通機器, 長期執行宕機概率很高,所以兩臺機器能夠大大降低服務不可用的可能性,這正大型專案會採用十幾臺甚至上百臺來部署一個服務,這不僅是保證服務的高可用,更是提升服務的 QPS, 但是這樣又帶來一個問題,一個請求過來到底路由到哪臺機器? 路由演算法很多,有DNS 路由,如果 session 在本機,還會根據使用者 id 或則 cookie 等資訊路由到固定的機器,當然現在應用伺服器為了擴充套件的方便都會設計為無狀態的,session 會儲存到專有的 session 伺服器,所以不會涉及到拿不到 session 問題。那路由規則是隨機獲取麼?這是一個方法,但是據我所知, 實際情況肯定比這個複雜,在一定範圍內隨機,但是在大的範圍也會分為很多個域,例如如果為了保證異地多活的多機房, 跨機房呼叫的開銷太大,肯定會優先選擇同機房的服務,這個要參考具體的機器分佈來考慮。
- 一致性
資料被分散或者複製到不同的機器上,如何保證各臺主機之間的資料的一致性將成為一個難點。
- 故障的獨立性
分散式系統由多個節點組成,整個分散式系統完全出問題的概率是存在的,但是在實踐中出現更多的是某個節點出問題,其他節點都沒問題。這種情況下我們實現分散式系統時需要考慮得更加全面些