
圖解分散式系統架構演進之路
介紹
分散式和叢集的概念經常被搞混,現在一句話讓你明白兩者的區別。
分散式:一個業務拆分成多個子業務,部署在不同的伺服器上
叢集:同一個業務,部署在多個伺服器上
例如:電商系統可以拆分成商品,訂單,使用者等子系統。這就是分散式,而為了應對併發,同時部署好幾個使用者系統,這就是叢集
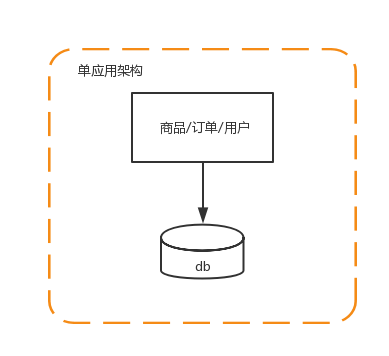
1 單應用架構
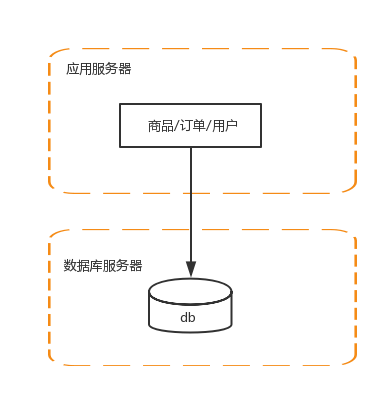
2 應用伺服器和資料庫伺服器分離
單機負載越來越來,所以要將應用伺服器和資料庫伺服器分離
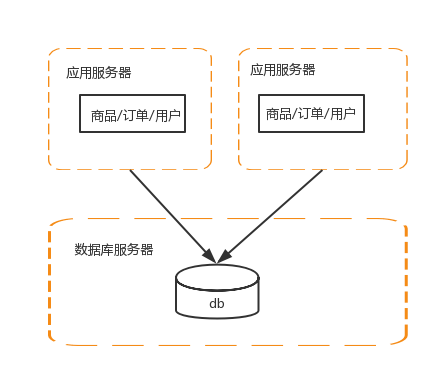
3 應用伺服器做叢集
每個系統的處理能力是有限的,為了提高併發訪問量,需要對應用伺服器做叢集
這時會涉及到兩個問題:
- 負載均衡
- session共享
負載均衡就是將請求均衡地分配到多個系統上,常見的技術有如下幾種
DNS
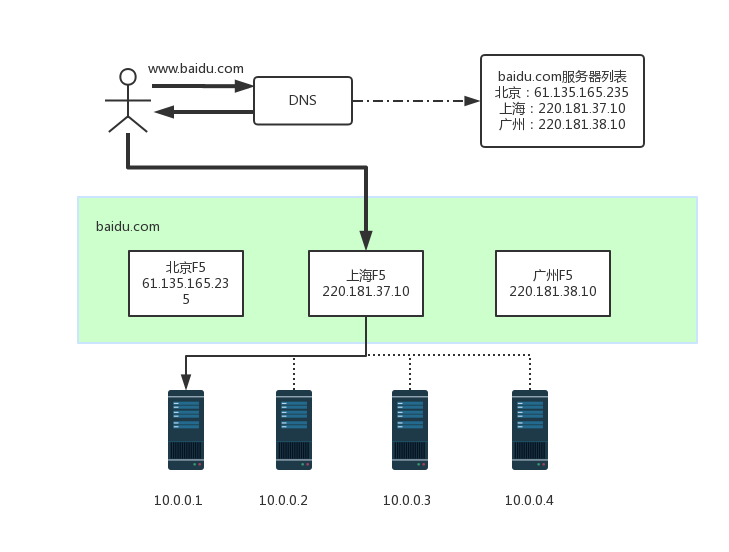
DNS是最簡單也是最常見的負載均衡方式,一般用來實現地理級別的均衡。例如,北方的用於訪問北京的機房,南方的使用者訪問廣州的機房。一般不會使用DNS來做機器級別的負載均衡,因為太耗費IP資源了。例如,百度搜索可能要10000臺以上的機器,不可能將這麼多機器全部配置公網IP,然後用DNS來做負載均衡。
Nginx&LVS&F5
DNS是用於實現地理級別的負載均衡,而Nginx&LVS&F5用於同一地點內機器級別的負載均衡。其中Nginx是軟體的7層負載均衡,LVS是核心的4層負載均衡,F5是硬體做4層負載均衡,效能從低到高位Nginx<LVS<F5
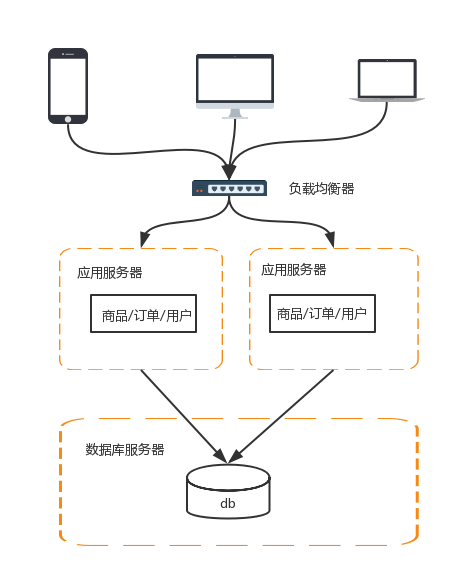
下圖形象的展示了一個實際請求過程中,地理級別的負載均衡和機器級別的負載均衡是如何分工和結合的,其中粗線是地理幾倍的負載均衡,細線是機器級別的負載均衡,實線代表最終的路由路徑
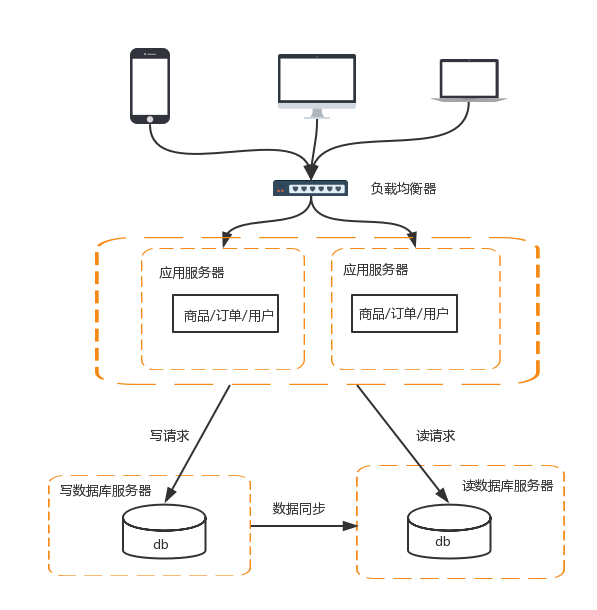
session共享就是使用者在A伺服器登入,結果檢視購物車時,請求傳送到了B伺服器,因此使用者的session存在A伺服器上,所以當請求傳送到B伺服器上時,會認為使用者沒有登入
簡單說一下session和cookie的互動過程,有想深入瞭解的看推薦閱讀,假設使用者在A伺服器登入,tomcat會在HttpServletReponse中新增一個cookie,key為JSESSIONID,當用戶第二次訪問的時候會帶上這個cookie,而tomcat會根據這個JSESSIONID找到HttpSession,怎麼找到呢?因為tomcat中有這樣一個ConcurrentHashMap,key為JSESSIONID value為 Session物件,以後會詳細講這塊,要想真正理解清楚,內容也挺多的。
所以當應用伺服器只有一個時,登入一般都是寫成如下:
@RequestMapping(value = "login", method = RequestMethod.POST)
// ServerResponse是小編封裝的一個返回物件
public ServerResponse<User> login(String username, String passwrod, HttpSession session) {
ServerResponse<User> response = userService.login(username, passwrod);
// 登入成功,將使用者資訊放到session中
if (response.isSuccess()) {
session.setAttribute(Const.CURRENT_USER, response.getData());
}
return response;
}
檢視購物車時,寫成如下
@RequestMapping(value = "list", method = RequestMethod.GET)
public ServerResponse<CartVo> list(HttpSession session) {
User user = (User)session.getAttribute(Const.CURRENT_USER);
if (user == null) {
// session中沒有有使用者資訊,需要登入
return ServerResponse.errorCodeMsg(ResponseCode.NEED_LOGIN.getCode(), ResponseCode.NEED_LOGIN.getDesc());
}
return cartService.list(user.getId());
}
目前解決session跨域共享問題有如下幾種方式
- session sticky
將請求都落到同一個伺服器上,如Nginx的url hash - session replication
session複製,每臺伺服器都儲存一份相同的session - session 集中儲存
儲存在db、 儲存在快取伺服器 (redis) - cookie (主流)
將資訊存在加密後的cookie中
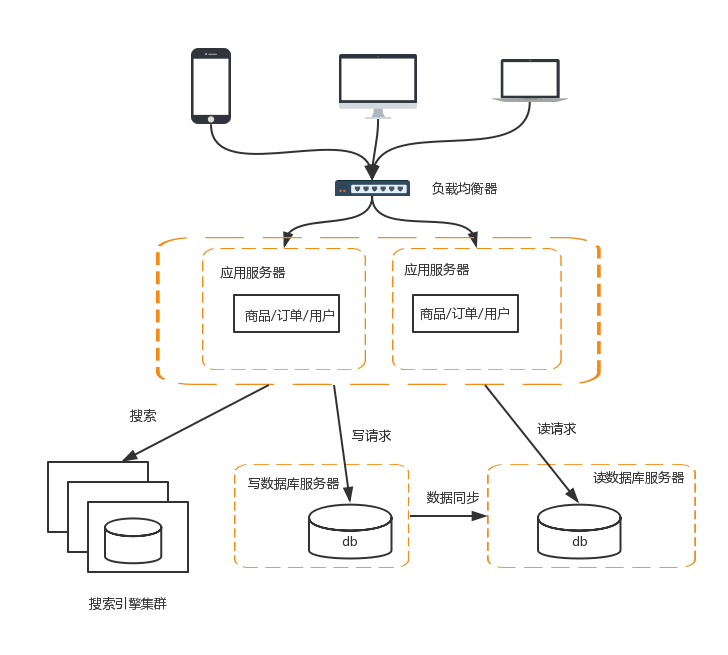
4 資料庫高效能操作
搭建資料庫主從叢集,實現資料庫讀寫分離,改善資料庫負載壓力
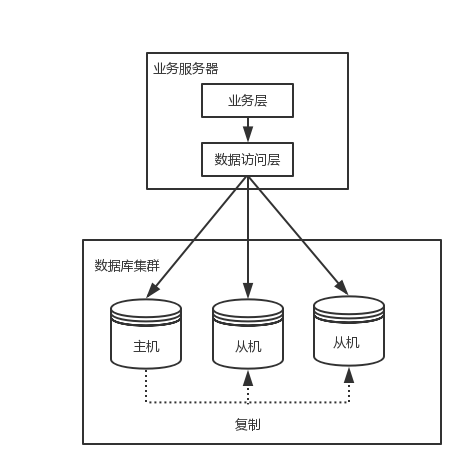
資料庫讀寫分離的基本實現如下:
- 資料庫伺服器搭建主從叢集,一主已從,一主多從都可以
- 資料庫主機負責讀寫操作,從機只負責讀操作
- 資料庫主機通過複製將資料同步到從機,每臺數據庫伺服器都儲存了所有的業務資料
- 業務伺服器將寫操作分給資料庫主機,將讀操作分給資料庫從機
實現方式
讀寫分離需要將讀/寫操作區分開來,然後訪問不同的資料庫伺服器;分庫分表需要根據不同的資料訪問不同的資料庫伺服器,兩者本質上都是一種分配機制,即將不同的SQL語句傳送到不同的資料庫伺服器。
讀寫分離,包括後面要提到的分庫分表的實現方式有兩種:
- 程式程式碼封裝
- 中介軟體封裝
程式程式碼封裝指在程式碼中抽象一個數據訪問層來實現讀寫分離,分庫分表
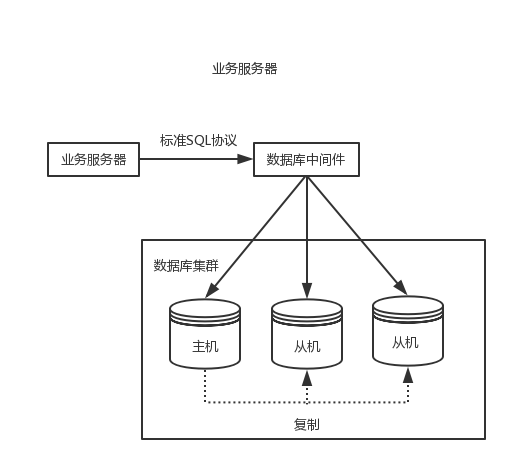
中介軟體封裝指的是獨立一套系統出來,實現讀寫分離和分庫分表操作,如我們熟悉的MySQL Router和Mycat等
5 引入搜尋引擎來查詢
傳統的關係型資料庫通過索引來達到快速查詢的目的,但是在全文搜尋的業務場景下,索引也無能為力,主要體現在如下幾點:
- 全文搜尋的條件可以隨意排列組合,如果通過索引來滿足,則索引的數量會非常多
- 全文搜尋的模糊匹配方式,索引無法滿足,只能用like查詢,而like查詢是整表掃描,效率非常低
6 增加快取
為了應對流量持續增加,必須增加快取
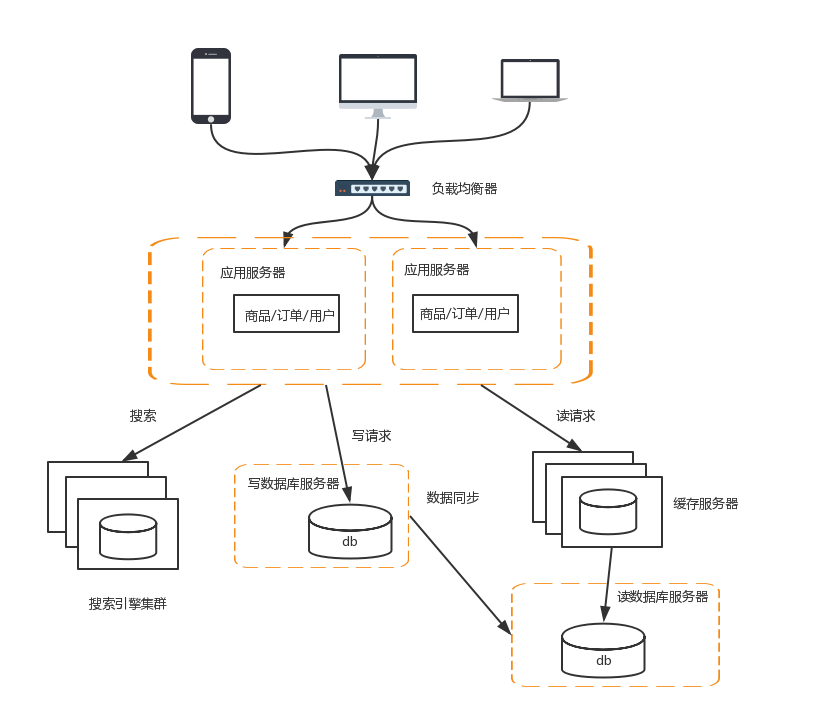
常見的方式有如下幾種:
Redis與Memcached
以我們常見的Mybatis為例,很容易和Redis與Memcached整合起來,快取已經查詢過的SQL,因為Mybatis知道自己不擅長快取,所以提供了介面讓這些快取工具進行整合
CDN
CDN是為了解決使用者網路訪問時的“最後一公里”效應,本質上是一種“以空間換空間”的加速策略,即建內容快取在離使用者最近的地方,使用者訪問的是快取的內容,而不是站點實時的內容。
7 分庫分表
讀寫分離分散了資料庫讀寫操作的壓力,但沒有分散儲存壓力,當資料量達到千萬甚至上億條的時候,單臺伺服器的儲存能力會成為系統的瓶頸。常見的分散儲存的方法有分庫和分表兩大類
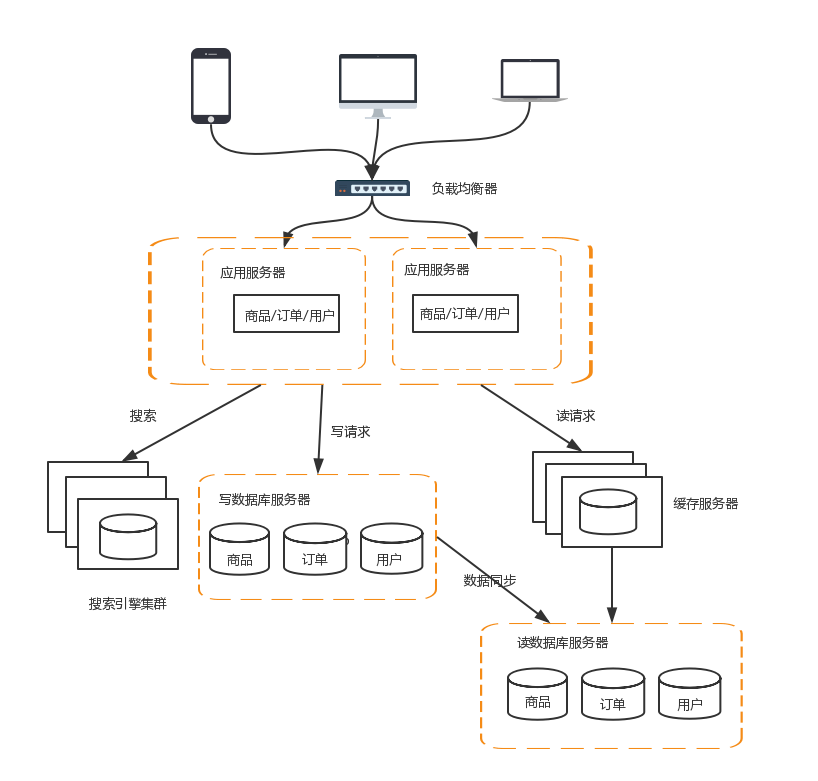
業務分庫
業務分庫指的是按照業務模組將資料分散到不同的資料庫伺服器。例如,一個簡單的電商網站,包括商品,訂單,使用者三個業務模組,我們可以將商品資料,訂單資料,使用者資料,分開放到3臺不同的資料庫伺服器上,而不是將所有資料都放在一臺資料庫伺服器上
當然業務分庫也會帶來新的問題:
- join操作問題:業務分庫後,原本在同一個資料庫中的表分散到不同資料庫中,導致無法使用SQL的join查詢
- 事務問題:原本在同一個資料庫中不同的表可以在同一個事務中修改,業務分庫後,表分散到不同資料庫中,無法通過事務統一修改
- 成本問題:業務分庫同時也帶來了成本的代價,本來1臺伺服器搞定的事情,現在要3臺,如果考慮備份,那就是2臺變成6臺
分表
表單資料拆分有兩種方式,垂直分表和水平分表
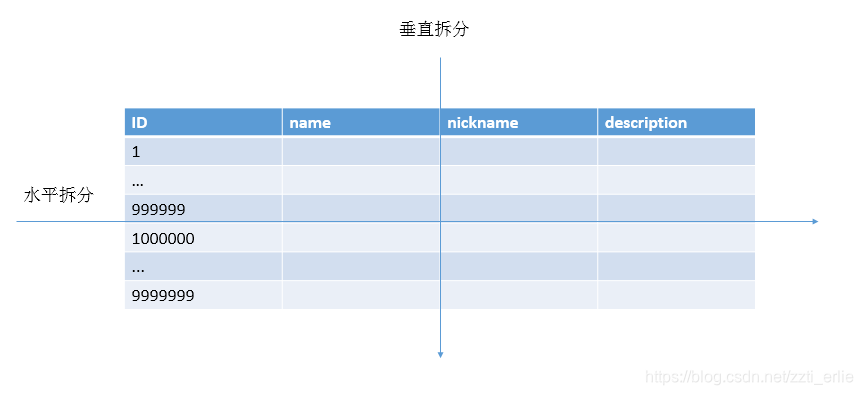
垂直分表:垂直分表適合將表中某些不常用且佔了大量空間的列拆分出去。如上圖的nickname和description欄位不常用,就可以將這個欄位獨立到另外一張表中,這樣在查詢name時,就能帶來一定的效能提升
水平分表:水平分表適合錶行數特別大的表,如果單錶行數超過5000萬就必須進行分表,這個數字可以作為參考,但並不是絕對標準,關鍵還是要看錶的訪問效能
水平分表後,某條資料具體屬於哪個切分後的子表,需要增加路由演算法進行計算,常見的路由演算法有
範圍路由:選取有序的資料列(例如,整型,時間戳等)作為路由條件,不同分段分散到不同的資料庫表中。以最常見的使用者ID為例,路由演算法可以按照1000000的範圍大小進行分段,1-999999放到資料庫1的表中,1000000-1999999放到資料庫2的表中,以此類推
Hash路由:選取某個列(或者某幾個列組合也可以)的值進行Hash運算,然後根據Hash結果分散到不同的資料庫表中。同樣以使用者Id為例,假如我們一開始就規劃了10個數據庫表,路由演算法可以簡單地用user_id%10的值來表示資料所屬的資料庫表編號,ID為985的使用者放到編號為5的子表中,ID為10086的使用者放到編號為6的子表中。
配置路由:配置路由就是路由表,用一張獨立的表來記錄路由資訊,同樣以使用者ID為例,我們新增一張user_router表,這個表包含user_id和table_id兩列,根據user_id就可以查詢對應的table_id
8 應用拆分/微服務
隨著業務的發展,業務越來越多,應用的壓力越來越大。工程規模也越來越龐大。這個時候就可以考慮將應用拆分,按照領域模型將我們的商品,訂單,使用者分拆成子系統。
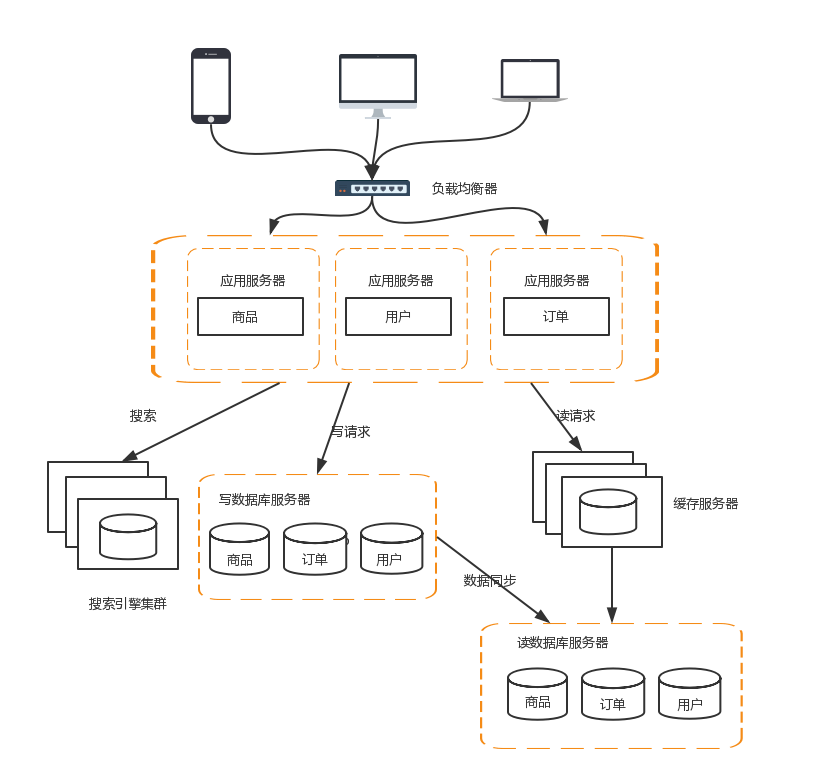
這樣拆分以後,可能會有一些相同的程式碼,比如訂單模組有對使用者資料的查詢,使用者模組中肯定也有對使用者資料的查詢。這些相同的程式碼和模組一定要抽象出來。這樣有利於維護和管理。這時可以將模組變為一個個服務,模組之間互相呼叫來獲取資料,系統就變成一個微服務了。
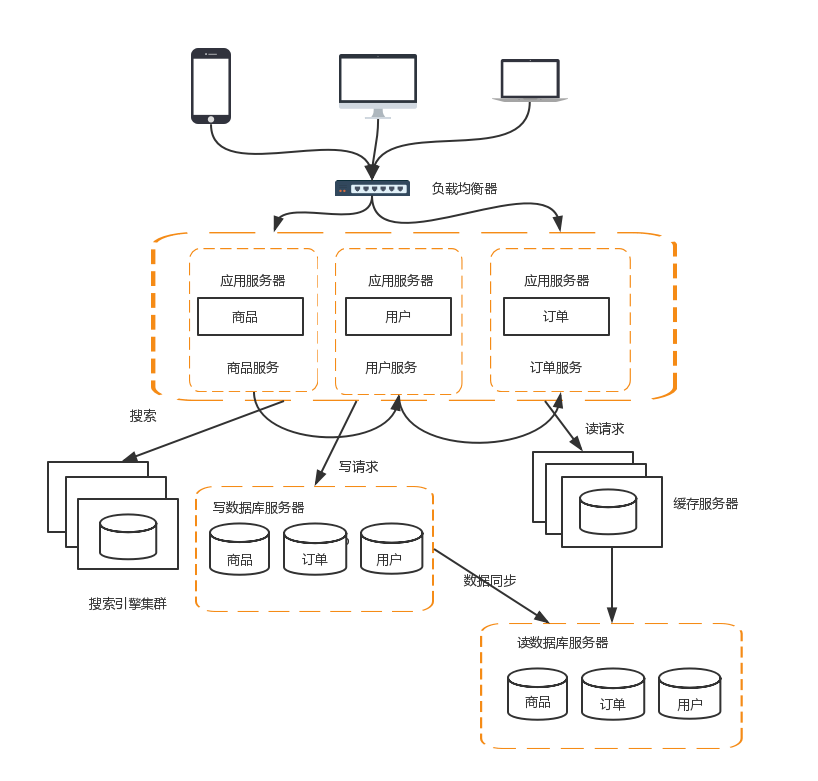
服務拆分以後,服務之間的通訊可以通過RPC技術,比較典型的有:Webservice、Hessian、HTTP、RMI等。如當前的Dubbo和Spring Cloud都是目前比較流行的微服務框架,2者之間還是有很多區別的,以後分享。
參考部落格
[1]https://www.cnblogs.com/dump/p/8125539.html
[2]https://blog.csdn.net/zty1317313805/article/details/80433643
[3]https://www.zhihu.com/question/20004877
[4]https://www.cnblogs.com/chenpi/p/5434537.html