python3 urllib基本使用
在python中,urllib是請求url連線的標準庫,在python2中,分別有urllib和urllib,在python3中,整合成了一個,稱謂urllib
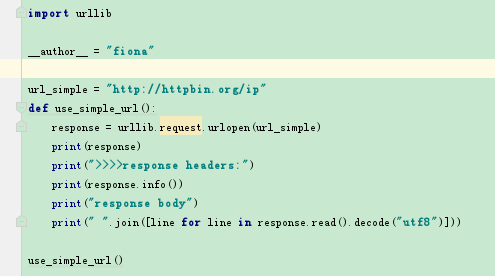
urllib.request
request主要負責構建和發起網路請求
1)GET請求(不帶引數)
response = urllib.request.urlopen(url,data=None, [timeout, ]*)
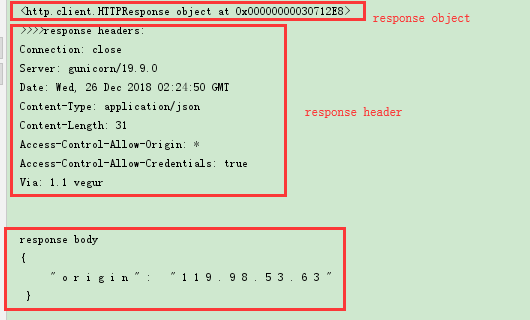
返回的response是一個http.client.HTTPResponse object
response操作:
a) response.info() 可以檢視響應物件的頭資訊,返回的是http.client.HTTPMessage object
b) getheaders() 也可以返回一個list列表頭資訊
c) response可以通過read(), readline(), readlines()讀取,但是獲得的資料是二進位制的所以還需要decode將其轉化為字串格式。
d) getCode() 檢視請求狀態碼
e) geturl() 獲得請求的url
>>>>>>>
2)GET請求(帶引數)
需要用到urllib下面的parse模組的urlencode方法
param = {"param1":"hello", "param2":"world"}
param = urllib.parse.urlencode(param) # 得到的結果為:param2=world¶m1=hello
url = "?".join([url, param]) # http://httpbin.org/ip?param1=hello¶m2=world
response = urllib.request.urlopen(url)
3)POST請求:
urllib.request.urlopen()預設是get請求,但是當data引數不為空時,則會發起post請求
傳遞的data需要是bytes格式
設定timeout引數,如果請求超出我們設定的timeout時間,會跑出timeout error 異常。
param = {"param1":"hello", "param2":"world"}
param = urllib.parse.urlencode(param).encode("utf8") # 引數必須要是bytes
response = urllib.request.urlopen(url, data=param, timeout=10)
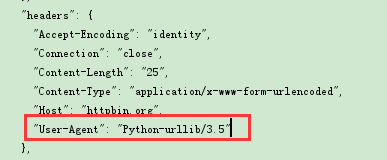
4)新增headers
通過urllib發起的請求,會有一個預設的header:Python-urllib/version,指明請求是由urllib發出的,所以遇到一些驗證user-agent的網站時,我們需要偽造我們的headers
偽造headers,需要用到urllib.request.Request物件
headers = {"user-agent:"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)


對於爬蟲來說,如果一直使用同一個ip同一個user-agent去爬一個網站的話,可能會被禁用,所以我們還可以用使用者代理池,迴圈使用不同的user-agent
原理:將各個瀏覽器的user-agent做成一個列表,然後每次爬取的時候,隨機選擇一個代理去訪問
uapool = ["谷歌代理", 'IE代理', '火狐代理',...]
curua = random.choice(uapool)
headers = {"user-agent": curua}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)
5)新增cookie
為了在請求的時候,帶上cookie資訊,需要構造一個opener
需要用到http下面的cookiejar模組
from http import cookiejar
from urllib import request
a) 建立一個cookiejar物件
cookie = cookiejar.CookieJar()
b) 使用HTTPCookieProcessor建立cookie處理器
cookies = request.HTTPCookieProcessor(cookie)
c) 以cookies處理器為引數建立opener物件
opener = request.build_opener(cookies)
d) 使用這個opener來發起請求
resp = opener.open(url)
e) 使用opener還可以將其設定成全域性的,則再使用urllib.request.urlopen發起的請求,都會帶上這個cookie
request.build_opener(opener)
request.urlopen(url)
6)IP代理
使用爬蟲來爬取資料的時候,常常需要隱藏我們真實的ip地址,這時候需要使用代理來完成
IP代理可以使用西刺(免費的,但是很多無效),大象代理(收費)等
代理池的構建可以寫固定ip地址,也可以使用url介面獲取ip地址
固定ip:
from urllib import request
import random
ippools = ["36.80.114.127:8080","122.114.122.212:9999","186.226.178.32:53281"]
def ip(ippools):
cur_ip = random.choice(ippools)
# 建立代理處理程式物件
proxy = request.ProxyHandler({"http":cur_ip})
# 構建代理
opener = request.build_opener(proxy, request.HttpHandler)
# 全域性安裝
request.install_opener(opener)
for i in range(5):
try:
ip(ippools)
cur_url = "http://www.baidu.com"
resp = request.urlopen(cur_url).read().decode("utf8")
excep Exception as e:
print(e)
使用介面構建IP代理池(這裡是以大象代理為例)
def api():
all=urllib.request.urlopen("http://tvp.daxiangdaili.com/ip/?tid=訂單號&num=獲取數量&foreign=only")
ippools = []
for item in all:
ippools.append(item.decode("utf8"))
return ippools
其他的和上面使用方式類似
7)爬取資料並儲存到本地 urllib.request.urlretrieve()
如我們經常會需要爬取一些檔案或者圖片或者音訊等,儲存到本地
urllib.request.urlretrieve(url, filename)
8)urllib的parse模組
前面第2)中,我們用到了urllib.parse.urlencode()來編碼我們的url
a)urllib.parse.quote()
這個多用於特殊字元的編碼,如我們url中需要按關鍵字進行查詢,傳遞keyword='詩經'
url是隻能包含ASCII字元的,特殊字元及中文等都需要先編碼在請求
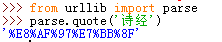
要解碼的話,使用unquote
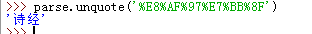
b)urllib.parse.urlencode()
這個通常用於多個引數時,幫我們將引數拼接起來並編譯,向上面我們使用的一樣

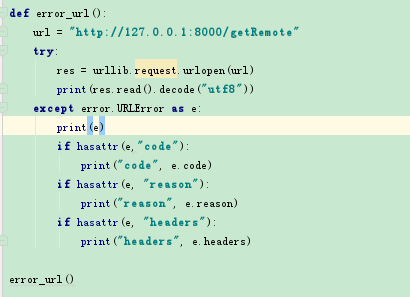
9)urllib.error
urllib中主要兩個異常,HTTPError,URLError,HTTPError是URLError的子類
HTTPError包括三個屬性:
code:請求狀態碼
reason:錯誤原因
headers:請求報頭