
docker 對前後端分離專案的部署和運維
1.首先要有虛擬機器(vmware 這是一個虛擬機器安裝軟體,然後下載cenos作業系統,centos是linux社群辦的一個流行的作業系統,還有Redhat 商業版的,安全還提供一些額外的服務,但是要收費,還有對虛擬機器的硬體和軟體進行配置,在VMware這個圖形化的工具裡面就可以進行配置)或者是購買阿里的ecs伺服器,下載cenos公共映象(有免費的為啥不用這個呢)。
2.連線遠端伺服器和對遠端伺服器的管理用xhell(功能強大)或者是putty(小巧),因為要設計到一些檔案傳輸到遠端,所以這裡推薦flashftp 或者是xftp(xhell推薦使用,xftp整合到xhell)
3.後臺java專案的部署https://www.renren.io/ renren-fast
下載後臺java 的原始碼,然後下載eclips編輯器,因為這個專案是用springboot來開發的,springboot用了mevan,所以要下載meavn (一個java專案的管理工具,在匯入meavn專案的時候回下載jarl類,也方便釋出)然後映象修改成阿里的映象(修改方法自行百度,其實只是在cnof加幾行程式碼就行了),然後在編輯器裡面配置好maven,然後匯入已經存在的maven專案
下載navicat ,在安裝的時候如果報錯10038 ,那是因為mysql沒有啟動,navicat 只是一個mysql的圖形化管理頁面,前提還是得有mysql,所以還得下載mysql。
4.前臺專案的部署
5.linux 目錄和命令的學習 我的其他的文章
6.防火牆管理, centos 自帶firewalld 防火牆,命令如下

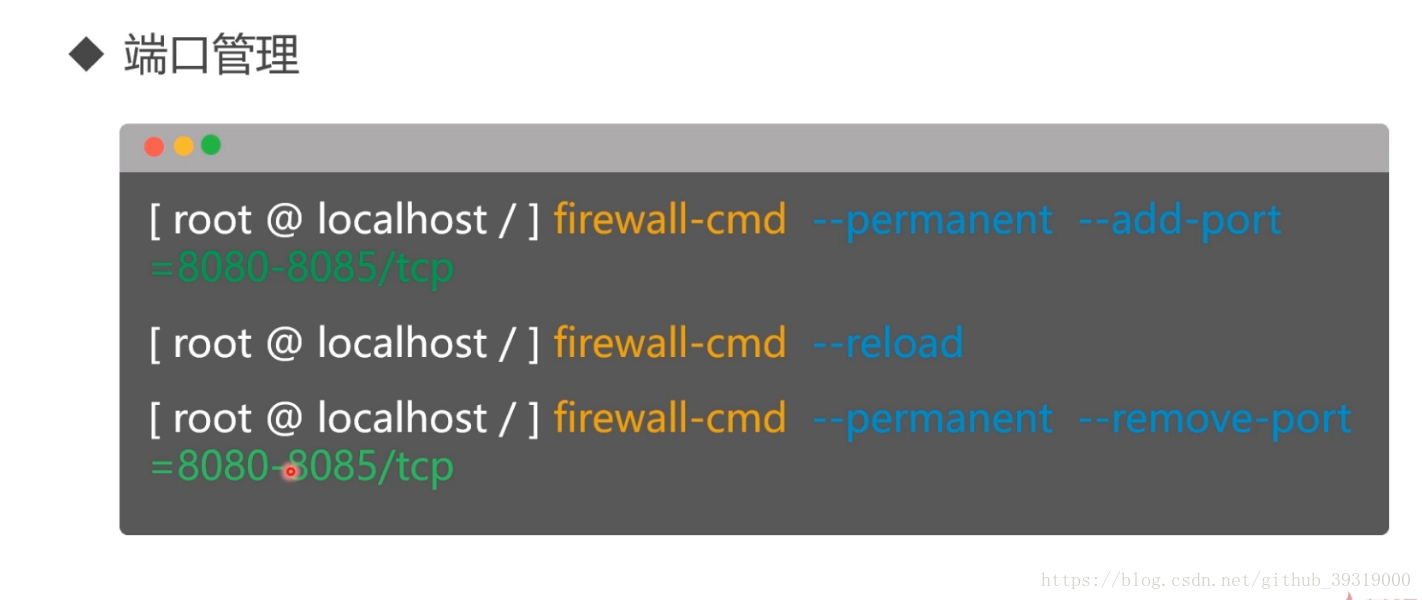
檢視防火牆開啟的埠號是 firewall-cmd --permanent --list-ports
檢視有哪些服務通過防火牆連線了網際網路 firewall-cmd --permanent --list-services
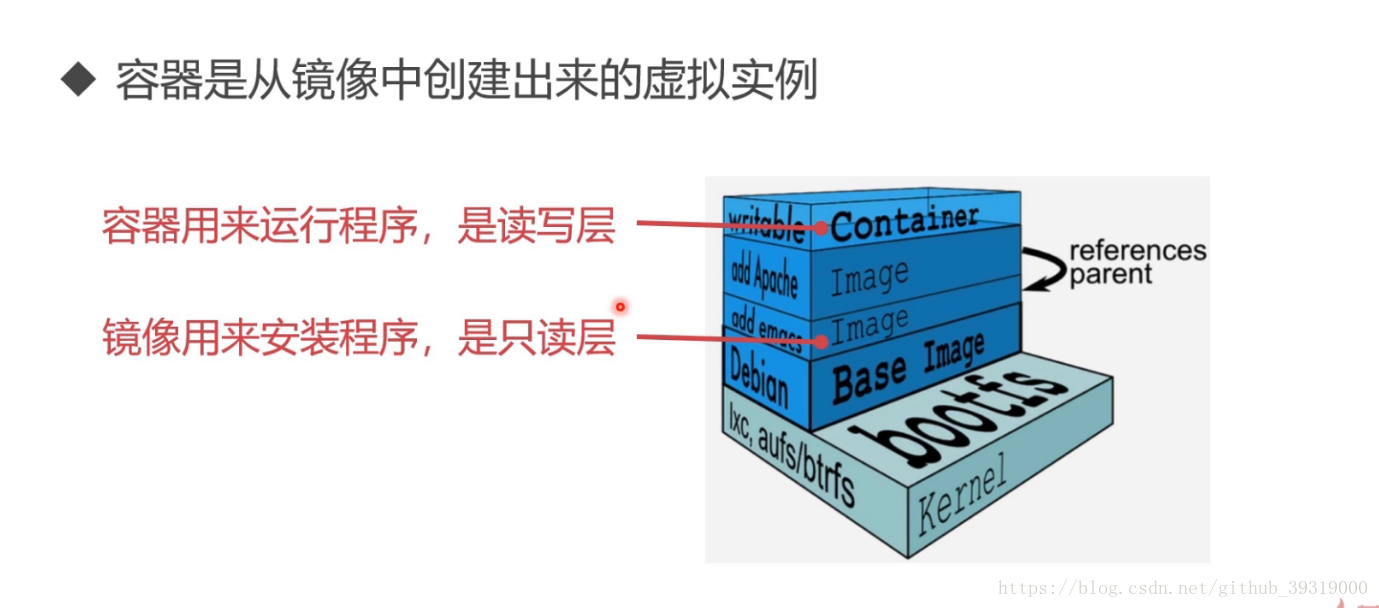
7. docker 學習 映象是可讀不可寫的,實際存在的,容器是虛擬的,可讀可寫的
這裡有片騰訊課堂的文章講的比較詳細 https://ke.qq.com/course/303636
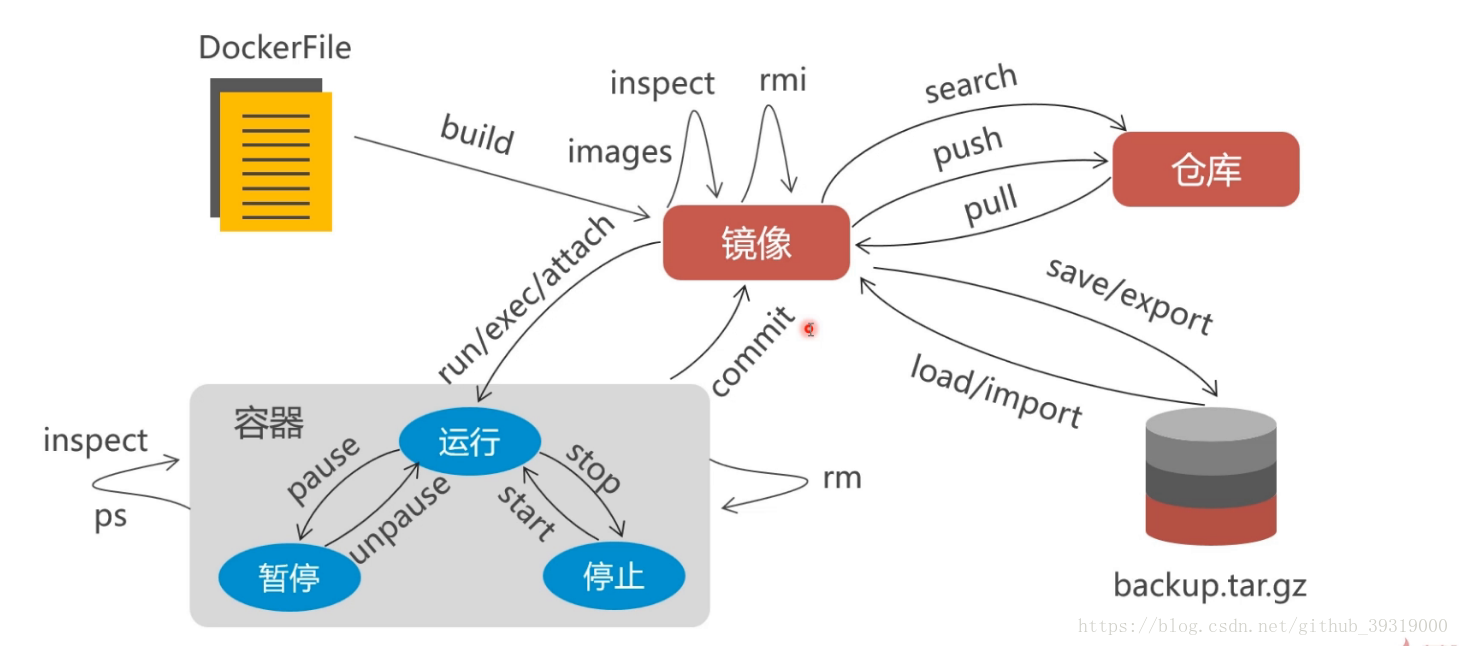



7. mysql 叢集方案介紹,建議使用pxc,因為弱一致性會有問題,比如說a節點資料庫顯示我購買成功,b 節點資料庫顯示沒有成功,這就麻煩了,pxc 方案是在全部節點都寫入成功之後才會告訴你成功,是可讀可寫雙向同步的,但是replication是單向的,不同節點的資料庫之間都會開放埠進行通訊,如果從防火牆的這個埠關閉,pxc就不會同步成功,也不會返給你成功了。
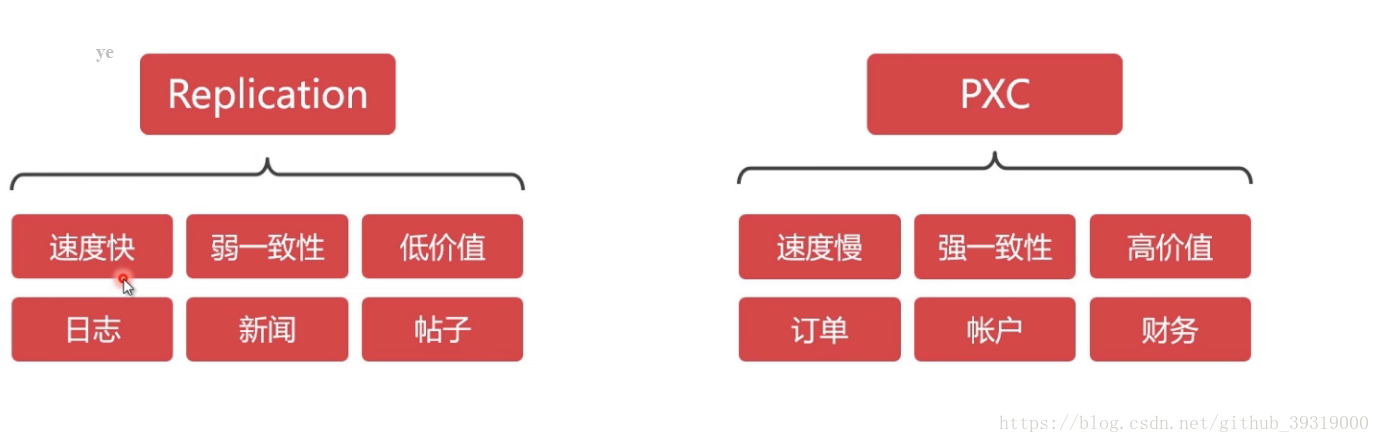
8.建立mysql叢集
1.因為我們採用的是pxc方案,所以要在docker的官方倉庫下載pxc方案的映象
2.由上面我們知道各節點之間在通訊的時候時候內部埠的,首先我們要建立內部網段,並且分配具體的ip。
3.建立資料卷,容器中的資料不要放在容器中而是放在宿主機上,這樣當容器出現問題的時候,可以刪除容器,重新建立。
(資料卷 如果用的是pxc技術的話,建立資料卷的時候不能單純的使用資料夾的對映,否則會閃退,必須得用volume技術)
3.執行pxc映象,(執行完後產生的是資料庫的例項,用資料庫連線宿主機的ip的分配的埠號就可以進行連線)輸入各種引數產生資料庫節點 還有之前建立了網段現在分配一個給這個節點進行通訊,然後登陸資料庫進行連線。到此完成mysql叢集。

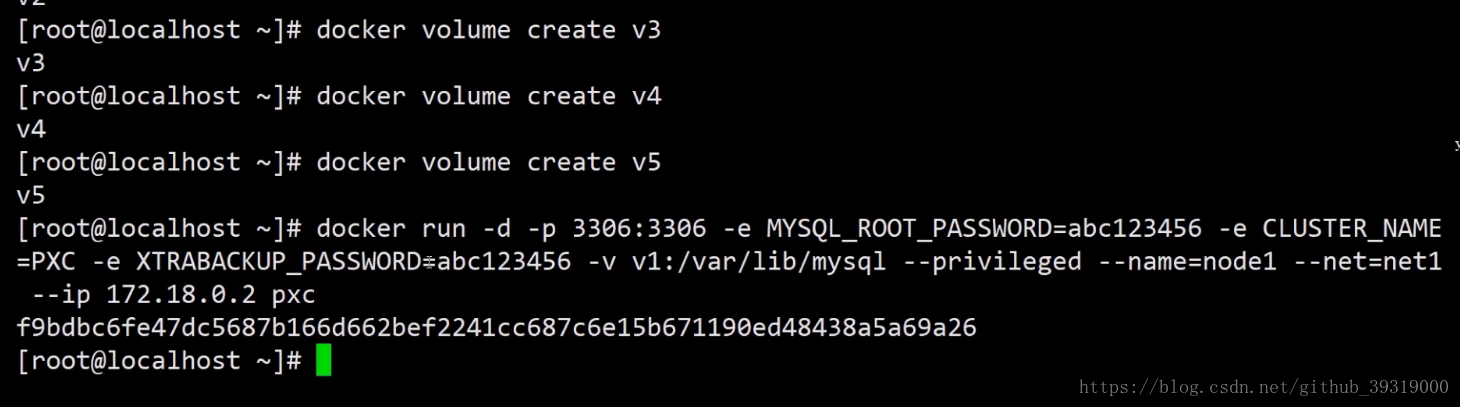
9.mysql 資料庫的負載均衡(相當於請求轉發器)
負載均衡首先是資料庫的叢集,加入5個叢集,每次請求都是第一個的話,有可能第一個資料庫就掛掉了,所以更優的方案是對不同的節點都進行請求,這就需要有中介軟體進行轉發,比較好的中介軟體有nginx,haproxy等,因nginx 支援外掛,但是剛剛支援了tcp/ip 協議,haproxy 是一個老牌的中間轉發件。如果要用haproxy的話,可以從官方下載映象,然後呢對映象進行配置(自己寫好配置檔案,因為這個映象是沒有配置檔案的,配置好之後再執行映象的時候進行資料夾的對映,配置檔案開放3306(資料庫請求,然後根據check心跳檢測訪問不同的資料庫,8888 對資料庫叢集進行監控))。配置檔案裡面設定使用者(使用者在資料庫進行心跳檢測,判斷哪個資料庫節點是空閒的,然後對空閒的進行訪問),還有各種演算法(比如輪訓),最大連線數,時間等,還有對叢集的監控。配置檔案寫好以後執行這個映象,映象執行成功後進入容器啟動配置檔案 。其實haprocy返回的也是一個數據庫例項(但是並不儲存任何的資料,只是轉發請求),這個例項用來check其他節點。最好生成至少兩個這樣的例項。當一個掛掉的時候,另外 一個可以頂上(這就是雙機熱備見10)。
10.雙機熱備
雙機就是兩個請求處理程式,比如兩個haproxy,當一個掛掉的時候,另外 一個可以頂上。熱備我理解就是keepalive。在haproxy 容器中安裝keepalive。
關鍵就是虛擬ip,定義一個虛擬ip,然後比如兩個haproxy分別安裝keepalive映象,因為haproxy是ubuntu系統的,所以安裝用apt-get,keepalive是作用是搶佔虛擬ip,搶到的就是主伺服器,沒有搶到的就是備用伺服器,然後兩個keepalive進行心跳檢測(就是建立一個使用者到對方那裡試探,看是否還活著,mysql的叢集之間也是心跳檢測),如果 掛掉搶佔ip。所以在啟動keepalive 之前首先要編輯好他的配置檔案,怎麼搶佔,權重是什麼,虛擬ip是什麼,建立的使用者交什麼。配置完啟動完以後可以ping一下看是否正確.
然後將虛擬ip對映到區域網的ip
11.熱備份資料
1.冷備份 匯出資料庫進行備份,但是資料庫需要停機,影響業務
2.熱備份
全量備份:整個都備份 增量備份:對變化的資料進行備份 。
方案:lvm 和xtrabackup lvm 需要對資料庫進行加鎖(鎖表),只能讀取資料不能寫入資料。
具體方法:利用mysql叢集的技術,暫停刪除一個節點映象,新建一個節點進行備份(先要創造一個數據卷用來對映容器中備份的資料),然後下載xtrabackup 進行備份。
備份資料進行恢復

12.docker swarm技術(之前的docker叢集都是在 一個虛擬主機上的,但是如果這個主機掛掉了over了,docker技術就是多個虛擬主機形成一個叢集)
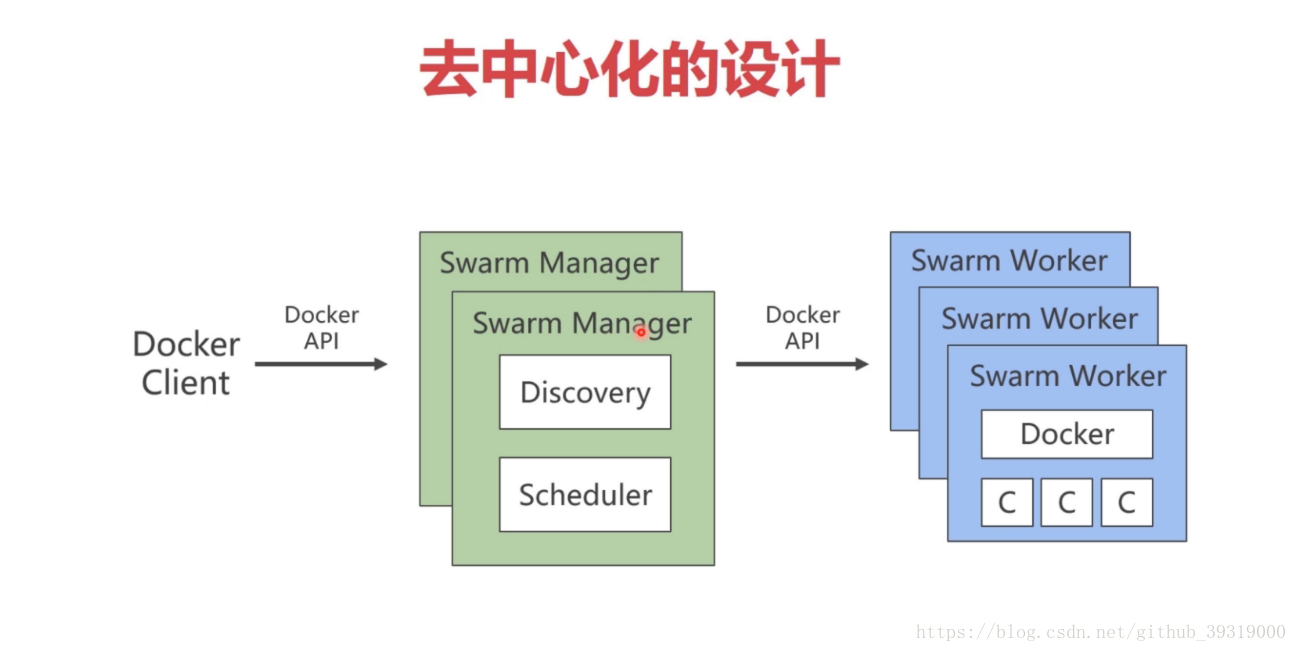
13.雲端部署
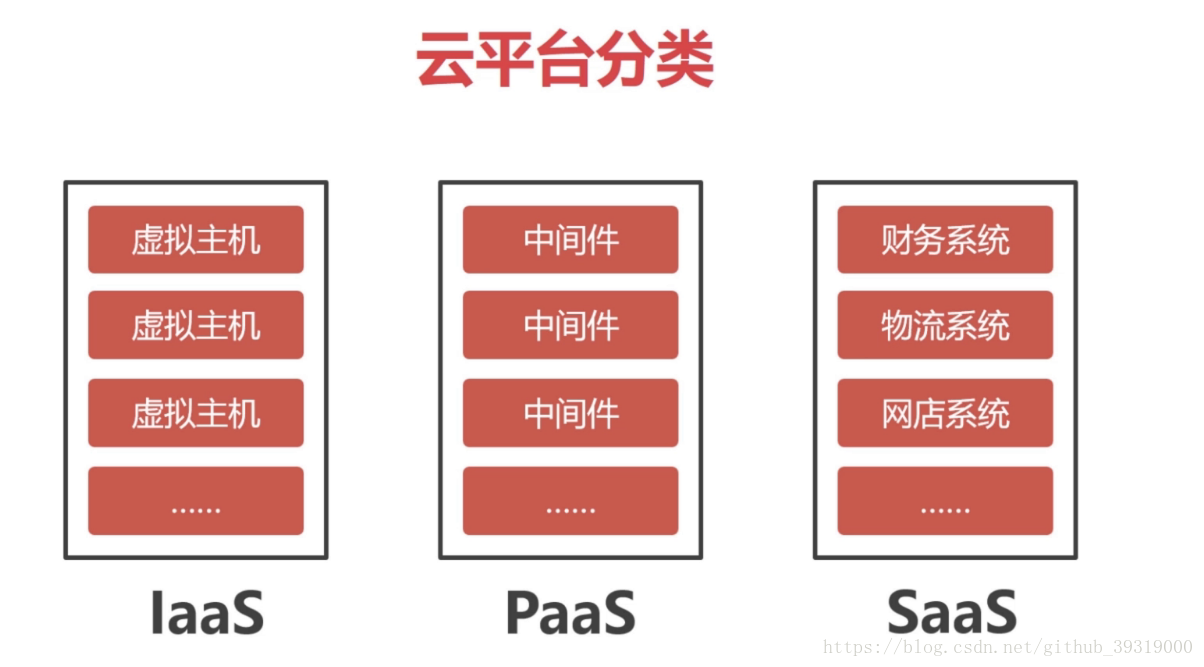
百度雲傾向谷歌的方案做的是paas 雲和saas雲,比如百度的bae(baidu application engine)就是paas 。bcc(Baidu Cloud Compute)我理解就是laas
騰訊的優勢是社交,可以在中介軟體挖掘很多的社交資料,paas
阿里傾向於亞馬孫的的方案,平成的交易量和雙11相比有很大的閒置資源,所以將閒置資源出租,laas雲
在雲平臺搭建資料庫叢集的幾種方式:
1.購買一個配置較高的雲主機,在雲主機內搭建docker pxc 資料庫叢集。
2.購買幾個配置較低的雲主機,用docker swarm技術元件集權
3.第三種就是將以上兩種結合起來,如果一個雲主機掛掉還有其他的雲主機。