
【121】Tensorflow合成特徵和擷取離群值
開發環境
python 版本用的是2
資料來源
沒有積分的讀者請給我留言,我給你單獨發。
全部程式碼
所有的程式碼都在下面,你可以把這些程式碼複製貼上到一個編輯器裡,然後執行程式碼。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 從CSV檔案中讀取資料,返回DataFrame型別的資料集合。
def zc_func_read_csv():
zc_var_dataframe = pd.read_csv("http://yoursite.com/california_housing_train.csv" 程式執行結果是:
合成特徵
california_housing_train.csv 檔案的資料中包含了不同地區的房價中位數(median_house_value)、房間總數(total_rooms)和人口(population)等資訊。我們來探究一下哪些因素影響了房價中位數,我們猜測這個可能和人口密度相關。為了衡量人口密度,我們人均房間數(rooms_per_person)來表示。
人均房間數 = 房間總數 / 人口
反應到程式碼上,就是給 DataFrame 新增一個新的列“rooms_per_person” 。在上文中的主函式 zc_func_main 中,程式碼如下:
zc_var_dataframe["rooms_per_person"] = zc_var_dataframe["total_rooms"] / zc_var_dataframe["population"]我們用兩個特徵:房價總數(total_rooms)和人口(population),合成了一個新的特徵:人均房間數(rooms_per_person)
離群值
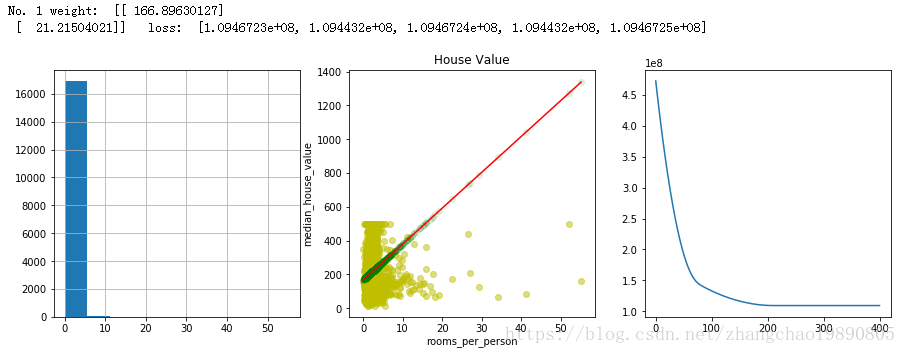
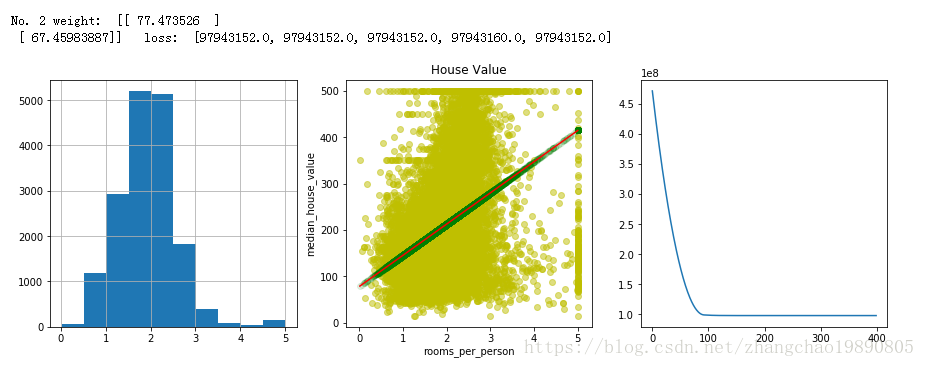
結果中,第一段No.1開頭的文字和第一行圖表是在沒有處理離群值的情況下,進行訓練後給出的結果。同理,第二段文字和第二行圖表是擷取離群值後,再進行訓練得到的結果。
離群值很可能對我們的訓練造成負面影響,讓我們的預測值不夠準確。在上面的程式碼中,我們通過程式碼:
ax = fig.add_subplot(2, 3, 1)
ax = zc_var_dataframe["rooms_per_person"].hist()繪製了原始資料的直方圖(結果圖中第一行第一個圖表),我們可以看到只有少數幾個值大於5,可以看作是離群值。
那麼,我們該如何處理離群值呢?
對於離群值有多種處理方法,我們最容易想到的一種方法是直接剔除離群值以及與之相關的其它資料。這就好比在散點圖中直接讓這個離群的點消失,當然隨著點的消失,不管是圖表中的橫軸還是縱軸上的資料,都會跟著消失。這固然是一種解決方法,但讓我們思考一下這麼做有什麼問題?實際中我們蒐集資料會是多維度的。當我們因為某條資料在某個維度上是離群值就將其刪除,會讓我們丟失這條資料在其它維度上的資訊。我們例子中的模型可以看作是探究兩個維度的關係:人均房間數(rooms_per_person)和房價中位數(median_house_value)。現實中資料往往超過兩個維度,剔除離群值會造成更多的資訊丟失。
本文中使用了擷取離群值的方法來處理離群值。我將人均房間數(rooms_per_person)大於5的資料統統賦值成5 。這樣即讓資料更加集中,又保留了每條資料在房價中位數(median_house_value)這一維度的資訊。
上面的程式碼中我們先定義 DataFrame.apply 函式的回撥函式:
def zc_func_apply_callback(zc_param_value):
zc_var_result = 5
if (zc_param_value < zc_var_result):
zc_var_result = zc_param_value
return zc_var_result然後對人均房間數(rooms_per_person)擷取離群值:
# 擷取離群值。直方圖顯示,大多數值都小於 5。我們將 rooms_per_person 的值擷取為 5,然後繪製直方圖以再次檢查結果。
zc_var_dataframe["rooms_per_person"] = zc_var_dataframe["rooms_per_person"].apply(zc_func_apply_callback)對比擷取離群值之前和之後的訓練結果,可以看到L2損失更小,擬合度更高。對比散點圖也能看出擬合度有了改善。