
K近鄰演算法理解及實現(python)
阿新 • • 發佈:2018-12-26
KNN的工作原理:給定一個已知標籤類別的訓練資料集,輸入沒有標籤的新資料後,在訓練資料集中找到與新資料最鄰
近的k個例項,如果這k個例項的多數屬於某個類別,那麼新資料就屬於這個類別。可以簡單理解為:由那些離X最
近的k個點來投票決定X歸為哪一類。
在二維平面下: 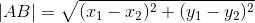
在N維空間下,也就是N個特徵值來決定新輸入資料的分類:
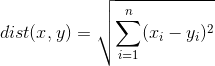
其演算法步驟如下:
(1) 計算已知類別資料集中的點與當前點之間的距離;
(2) 按照距離遞增次序排序;
(3) 選取與當前點距離最小的k個點;
(4) 確定前k個點所在類別的出現頻率;
(5) 返回前k個點出現頻率最高的類別作為當前點的預測類別。
#!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pa rowdata={'電影名稱':['無問西東','後來的我們','前任3','紅海行動','唐人街探案','戰狼2'], '打鬥鏡頭':[1,5,12,108,112,115], '接吻鏡頭':[101,89,97,5,9,8], '電影型別':['愛情片','愛情片','愛情片','動作片','動作片','動作片']} movie_data=pa.DataFrame(rowdata) def movie_classify(judge_data,movie_data,k): result=[] dist = list((((movie_data.iloc[:6, 1:3] - new_data) ** 2).sum(1)) ** 0.5) dist_l = pa.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])}) dr = dist_l.sort_values(by='dist')[:k] re = dr.loc[:, 'labels'].value_counts() result.append(re.index[0]) return result str1=input('請輸入該部電影中的打鬥鏡頭次數:') str2=input('請輸入該部電影中的接吻鏡頭次數:') new_data=[int(str1),int(str2)] predicetion=movie_classify(new_data,movie_data,4) print('這是一部:',predicetion)