
Java-JVM-編譯原理
Java-JVM-編譯原理
轉載宣告:
本文大量內容系轉載自以下文章,並參考其他文件資料加入了一些內容:
- JVM系列第4講:從原始碼到機器碼,發生了什麼?
作者:陳樹義
來源:部落格園 - 深入分析Java的編譯原理
來源:Hollis
轉載僅為方便學習檢視,一切權利屬於原作者,本人只是做了整理和排版,如果帶來不便請聯絡我刪除。
摘要
我們可以通過javac命令將Java程式的原始碼編譯成Java位元組碼,即我們常說的class檔案。這是我們通常意義上理解的編譯。但是,位元組碼並不是機器語言,要想讓機器能夠執行,還需要把位元組碼翻譯成機器指令。這個過程是Java虛擬機器做的,這個過程也叫編譯。是更深層次的編譯。在編譯原理中,把原始碼翻譯成機器指令,一般要經過以下幾個重要步驟:
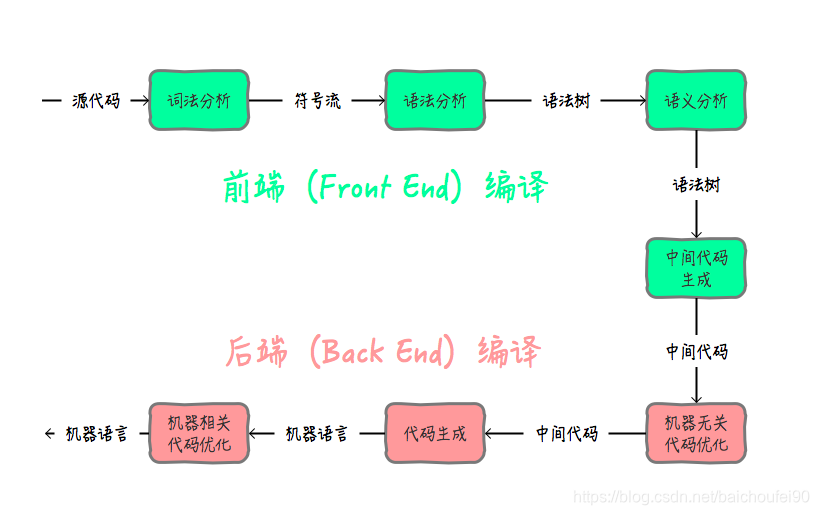
根據完成任務不同,可以將編譯器的組成部分劃分為前端(Front End)與後端(Back End):
- 前端編譯主要指與源語言有關但與目標機無關的部分,包括詞法分析、語法分析、語義分析與中間程式碼生成。將.java檔案編譯成.class的編譯過程稱之為前端編譯。
- 後端編譯主要指與目標機有關的部分,包括程式碼優化和目的碼生成等。將.class檔案翻譯成機器指令的編譯過程稱之為後端編譯。
如下圖所示,編譯器可以分為:前端編譯器、JIT 編譯器和AOT編譯器。下面我們逐個講解。

0x01 前端編譯器:原始碼到位元組碼
1.1 基本概念
對於 Java 虛擬機器來說,其實際輸入的是位元組碼檔案,而不是 Java 檔案。JDK 的安裝目錄裡有 javac
1.2 例子
通過 javac 編譯器,我們可以很方便地將 java 原始檔翻譯成位元組碼檔案。就拿我們最熟悉的 Hello World 作為例子:
public class Demo{
public static void main(String args[]){
System.out.println("Hello World!");
}
}
我們使用 javac 命令編譯上面這個類,便會生成一個 Demo.class 檔案:
javac Demo.java
我們使用純文字編輯器開啟 Demo.class 檔案,我們會發現是一連串的 16 進位制二進位制流。

1.3 javac流程
執行 javac 命令的過程,其實就是 javac 編譯器解析 Java 原始碼,並生成位元組碼檔案的過程,可以分為下面四個階段:
- 詞法、語法分析
JVM 對原始碼的字元進行一次掃描,經過詞法分析(原始碼CharStream轉為Tokens),語法分析,最終生成一個抽象的語法樹。語法樹每一個節點都代表程式碼中一個語法結構,如包、型別、運算子。

- 填充符號表
符號表由一組符號地址和符號資訊構成,在編譯不同階段都需使用。語義分析中,符號表所登記的內容用於語義檢查和生成中間程式碼。
我們知道類之間是會互相引用的,但在編譯階段,我們無法確定其具體的地址,所以我們會使用一個符號來替代。在這個階段做的就是類似的事情,即對抽象的類或介面進行符號填充。等到類載入階段,JVM 會將符號替換成具體的記憶體地址(解析階段,符號引用轉直接引用)。 - 註解處理
在這個階段會對註解進行分析,根據註解的作用將其還原成具體的指令集。
JDK1.6之前註解是在執行期起作用,JDK1.6提供了插入式註解處理器在編譯期處理註解,相當於編譯器外掛,會按需修改抽象語法樹,所以一旦修改了AST,會回到第一步重複前三步,直到註解處理不再修改AST。 - 語義分析
語義分析(包括標註檢查和資料及控制流分析、解語法糖(泛型、自動裝拆箱等)等)。主要是對結構上正確的原始碼(語法分析階段確認)進行上下文檢查,如型別檢查(比如boolean b=false;char c=2;int d=b+c就有問題了)。最終得到標註了屬性的AST。 - 位元組碼生成
javac 編譯的最後階段是位元組碼生成,JVM 便會根據上面幾個階段分析出來的結果(AST, 符號表等)轉換為位元組碼寫入磁碟,還會新增(如clinit和init(不包括已在填充符號表時已執行的預設構造方法)在這時被新增到AST中)和轉換(如將String的加轉為StringBuilder.append)少量程式碼。
我們一般稱 javac 編譯器為前端編譯器,因為其發生在整個編譯的前期。常見的前端編譯器有 Sun 的 javac,Eclipse JDT 的增量式編譯器(ECJ)。
0x02 JIT 編譯器:從位元組碼到機器碼
2.1 基本概念
2.1.1 兩種執行模式
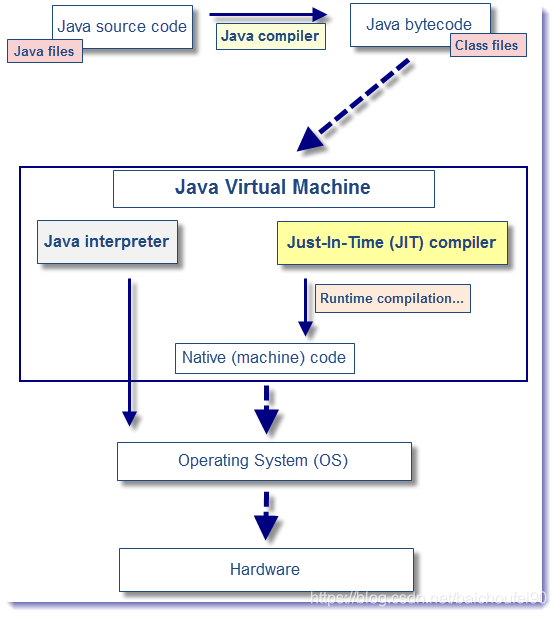
當原始碼轉化為位元組碼之後,要執行程式有兩種選擇:
- 使用 Java 直譯器來直接解釋執行位元組碼(基於棧的指令集)。
首先java原始碼編譯(javac)稱為.class檔案,JVM的類載入器載入位元組碼到方法區後,JVM內建的解析器會解釋執行,一行一行到把位元組碼轉換為機器語言再執行 - 使用 JIT 編譯器將位元組碼轉化為本地機器程式碼執行
由於大部分程式都表現出“小部分熱點程式碼消耗大部分的資源”,這裡的熱點程式碼就是高頻率呼叫的程式碼塊,類似“二八定律”,於是引入了JIT(方法級),也就是動態編譯器,利用了在執行時進行熱點程式碼編譯的技術,直接將位元組碼編譯為本地機器碼,JIT會快取編譯過的程式碼到Code Cache裡(HotSpot在啟動時,會為所有位元組碼建立在目標平臺上執行的解釋執行的機器碼,並存放在CodeCache中,在解釋執行位元組碼的過程中,就會從CodeCache中取出這些本地機器碼並執行。),且之後無需重複解釋。且在此過程中,會有大量優化策略!
這兩種方式的區別在於,前者啟動速度快但執行速度慢(指令較多、基於記憶體是瓶頸速度慢於暫存器),而後者啟動速度慢但執行速度快。因為直譯器不需要像 JIT 編譯器一樣,將所有位元組碼都轉化為機器碼,自然就省去了優化的時間。而當 JIT 編譯器完成第一次編譯後,其會將位元組碼對應的機器碼儲存下來,下次可以直接使用。而我們知道,機器碼的執行效率肯定是高於 Java 直譯器的。且在JIT編譯過程中,會有大量優化策略!
2.1.2 直譯器和編譯器配合
- 當程式需要迅速啟動和執行的時候,解析器首先發揮作用,省去編譯的時間,立即執行。隨著時間的推移,編譯器發揮作用,把越來越多的程式碼編譯成原生代碼,獲得更高的執行效率。
- 當機器記憶體限制比較大,可以用解析方式節約記憶體,反之可以用編譯提升效率。
- 解析器還可以作為編譯器的“逃生門”。當例如載入了新類後型別結構發生變化,可以採用逆優化,退回到解析狀態繼續執行。
2.1.3 混合模式
所以在實際情況中,為了執行速度以及效率,我們通常採用直譯器和JIT相結合的方式(即混合模式)進行 Java 程式碼的編譯執行。
2.2 C1與C2
2.2.1 簡介
在 HotSpot 虛擬機器內建了兩個即時編譯器,分別稱為 Client Compiler 和Server Compiler。這兩種不同的編譯器衍生出兩種不同的編譯模式,我們分別稱之為:C1 編譯模式,C2 編譯模式。
注意:現在許多人習慣上將 Client Compiler 稱為 C1 編譯器,將 Server Compiler 稱為 C2 編譯器,但在 Oracle 官方文件中將其描述為 compiler mode(編譯模式)。所以說 C1 編譯器、C2 編譯器只是我們自己的習慣性稱呼,並不是官方的說法。這點需要特別注意。

2.2.2 C1 和 C2 對比
- C1 編譯模式會將位元組碼編譯為原生代碼,進行簡單、可靠的優化,如有必要將加入效能監控的邏輯。針對啟動效能有要求的客戶端GUI程式。
- C2 編譯模式,也是將位元組碼編譯為原生代碼,但是會啟用一些編譯耗時較長的優化,甚至會根據效能監控資訊進行一些不可靠的激進優化。針對性能峰值。且在JDK1.7後,為了均衡啟動速度和執行效率,Server模式JVM採用了分層編譯為預設編譯策略,會根據編譯器編譯、優化的規模和耗時,劃分不同的編譯層次:
- 0層:程式直接解釋執行,
- 1層,即C1編譯。將位元組碼編譯為本地機器程式碼,
- 2層或2層以上:C2編譯。
在分層編譯中,C0不需要再蒐集效能監控資訊。C1(更高編譯速度)和 C2同時工作(更好的編譯質量),程式碼可能多次編譯。
2.3 熱點程式碼
2.3.1 熱點程式碼分類
前面提到的會被JIT編譯的熱點程式碼有兩類:
- 被多次呼叫的方法
JIT會以整個方法作為編譯物件,該方式是JVM中標準的JIT編譯方式。 - 被多次執行的迴圈體
JIT會以整個方法而不是迴圈體作為編譯物件
2.3.2 探測方法分類
目前主要的熱點程式碼識別方式是熱點探測(Hot Spot Detection),有以下兩種:
- 基於取樣的方式探測(Sample Based Hot Spot Detection) :週期性檢測各個執行緒的棧頂,發現某個方法經常出險在棧頂,就認為是熱點方法。
好處就是簡單;缺點就是無法精確確認一個方法的熱度。容易受執行緒阻塞或別的原因干擾熱點探測。 - 基於計數器的熱點探測(Counter Based Hot Spot Detection)。採用這種方法的虛擬機器會為每個方法(甚至是程式碼塊)建立計數器,統計方法的執行次數,某個方法超過閥值就認為是熱點方法,觸發JIT編譯。
好處是統計結果精確;缺點是這種方式需為每個方法維護一個計數器,且無法直接獲取方法間呼叫關係
2.3.3 熱點探測計數器
HotSpot使用基於計數器的熱點探測方法,為每個方法準備兩個計數器。他們都會先檢視是否存在已編譯版本,如果有就優先執行已編譯的原生代碼。否則計數器加一,然後判斷兩個計數器之和超過閾值就觸發JIT編譯,否則以解釋方式繼續執行:
-
方法計數器。記錄方法被呼叫次數。
-
回邊計數器。是記錄方法中的for或者while的執行次數的計數器。
-
關於OSR棧上替換
在回邊計數器中,編譯動作由迴圈體觸發,編譯器會以整個方法作為編譯物件,也就是說會在方法執行過程中進行編譯。那麼就會發生方法棧幀還在棧內,方法就被替換了,即所謂OSR棧上替換。
2.3.4 解釋、編譯和阻塞
在觸發編譯時,執行引擎不會等待編譯完成而是再繼續解釋執行位元組碼,直到編譯完成,將方法的呼叫入口地址直接替換為新的編譯後的程式碼地址。以後呼叫就可以都用已編譯版本。
2.4 JIT編譯優化
JIT除了具有快取的功能外,還會對程式碼做各種優化。典型的有:
逃逸分析、 公共子表示式消除、方法內聯、 陣列邊界檢查消除、鎖消除、鎖粗化等
0x03 AOT 編譯器:原始碼直接到機器碼
AOT 編譯器的基本思想是:在程式執行前將原始碼直接生成 Java 方法的原生代碼,以便在程式執行時直接使用原生代碼。
但是 Java 語言本身的動態特性帶來了額外的複雜性,影響了 Java 程式靜態編譯程式碼的質量。例如 Java 語言中的動態類載入,因為 AOT 是在程式執行前編譯的,所以無法獲知這一資訊,所以會導致一些問題的產生。類似的問題還有很多,這裡就不一一舉例了。
總的來說,AOT 編譯器從編譯質量上來看,肯定比不上 JIT 編譯器。其存在的目的在於避免 JIT 編譯器的執行時效能消耗或記憶體消耗,或者避免解釋程式的早期效能開銷。
在執行速度上來說,AOT 編譯器編譯出來的程式碼比 JIT 編譯出來的慢,但是比解釋執行的快。而編譯時間上,AOT 也是一箇中等的速度。所以說,AOT 編譯器的存在是 JVM 犧牲質量換取效能的一種策略。就如 JVM 其執行模式中選擇 Mixed 混合模式一樣,使用 C1 編譯模式只進行簡單的優化,而 C2 編譯模式則進行較為激進的優化。充分利用兩種模式的優點,從而達到最優的執行效率。
0x04 思考
- 為什麼Java不直接解釋執行原始碼?
- 使用位元組碼,可以避免每次執行時詞法、語法、語義分析之類的重複性工作。
- 位元組碼更便於虛擬機器讀取,不用在解析字串,所以執行速度比直接解析原始碼快。
- 語法是會變的,而原始碼中沒有版本資訊,而位元組碼中不但有版本資訊,還可以經由編譯過程抹平一些語言層面的變化(即語言語法雖然有變化,但位元組碼依然遵照原來的規則即可)。
- 位元組碼也可以由其他語言生成,如Groovy,Clojure,Scala。需要注意的事,既然這些語言可以編譯成位元組碼,也就可以被Java或其他JVM語言呼叫。
- 位元組碼比原始碼更加緊湊,檔案尺寸更小,方便網路傳輸。
- 有些嵌入裝置,不夠資源跑起完整的編譯器,這些裝置只需要嵌入一個小巧的JVM就行了,在額外的平臺上編譯原始碼。
0x05 直譯器FAQ
- 直譯器是一個轉換高階語言原始碼到機器編碼的程式?
錯誤。
這是編譯器乾的事。直譯器用來解釋執行非原生代碼(如Java的位元組碼) - Java直譯器的輸入是二進位制程式碼(前端編譯中由java編譯器將原始碼編譯為二進位制位元組碼)?
正確 - Java直譯器是JVM的一部分,他執行在JVM中,所以直譯器將生成由JVM執行的程式碼?
錯誤
位元組碼直譯器是JVM的一部分,但是並不執行在JVM中。而且位元組碼直譯器不產出任何東西,而是直接解釋執行位元組碼 - 直譯器用位元組碼生成中間程式碼和目標機器程式碼,並提交給JVM?
錯誤
以上工作是JVM做的事情 - JVM輪流在實現或執行JVM的OS平臺上執行該程式碼?
錯誤
JVM使用位元組碼、優化後的使用者程式碼、包含java lib和原生代碼的java內庫,以及OS呼叫來執行java應用程式。
0x06 總結
使用直譯器實現的程式語言實現裡,通常:
- 至少會在解釋執行前做完語法分析,然後通過樹直譯器來實現解釋執行;
- 兼顧易於實現、跨平臺、執行效率這幾點,會選擇使用位元組碼直譯器實現解釋執行
在 JVM 中有三個非常重要的編譯器,它們分別是:前端編譯器、JIT 編譯器、AOT 編譯器。
-
前端編譯器,最常見的就是我們的 javac 編譯器,其將 Java 原始碼編譯為 Java 位元組碼檔案。
-
JIT 即時編譯器,最常見的是 HotSpot 虛擬機器中的 Client Compiler 和 Server Compiler,其將 Java 位元組碼編譯為本地機器程式碼。
-
而 AOT 編譯器則能將原始碼直接編譯為本地機器碼。
-
這三種編譯器的編譯速度和編譯質量如下:
-
編譯速度上,解釋執行 > AOT 編譯器 > JIT 編譯器。
-
編譯質量上,JIT 編譯器 > AOT 編譯器 > 解釋執行。
-
而在 JVM 中,通過這幾種不同方式的配合,使得 JVM 的編譯質量和執行速度達到最優的狀態。
參考文件
《深入理解Java虛擬機器》
虛擬機器隨談(一):直譯器,樹遍歷直譯器,基於棧與基於暫存器,大雜燴
How exactly does the Java interpreter or any interpreter work?