Numpy中資料的常用的儲存與讀取方法(附list)
Numpy中資料的常用的儲存與讀取方法
轉自:http://www.cnblogs.com/wushaogui/p/9142019.html
文章目錄:
在經常性讀取大量的數值檔案時(比如深度學習訓練資料),可以考慮現將資料儲存為Numpy格式,然後直接使用Numpy去讀取,速度相比為轉化前快很多.
下面就常用的儲存資料到二進位制檔案和儲存資料到文字檔案進行介紹:
1.儲存為二進位制檔案(.npy/.npz)
numpy.save
儲存一個數組到一個二進位制的檔案中,儲存格式是.npy
引數介紹
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
file:檔名/檔案路徑
arr:要儲存的陣列
allow_pickle:布林值,允許使用Python pickles儲存物件陣列(可選引數,預設即可)
fix_imports:為了方便Pyhton2中讀取Python3儲存的資料(可選引數,預設即可)
使用
- >>> import numpy as np
- #生成資料
- >>> x=np.arange(10)
- >>> x
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- #資料儲存
- >>> np.save('save_x',x)
- #讀取儲存的資料
- >>> np.load('save_x.npy')
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
numpy.savez
這個同樣是儲存陣列到一個二進位制的檔案中,但是厲害的是,它可以儲存多個數組到同一個檔案中,儲存格式是.npz,它其實就是多個前面np.save的儲存的npy,再通過打包(未壓縮)的方式把這些檔案歸到一個檔案上,不行你去解壓npz檔案就知道了,裡面是就是自己儲存的多個npy.
引數介紹
numpy.savez(file, *args, **kwds)
file:檔名/檔案路徑
*args:要儲存的陣列,可以寫多個,如果沒有給陣列指定Key,Numpy將預設從'arr_0','arr_1'的方式命名
kwds:(可選引數,預設即可)
使用
- >>> import numpy as np
- #生成資料
- >>> x=np.arange(10)
- >>> x
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- >>> y=np.sin(x)
- >>> y
- array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
- -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
- #資料儲存
- >>> np.save('save_xy',x,y)
- #讀取儲存的資料
- >>> npzfile=np.load('save_xy.npz')
- >>> npzfile #是一個物件,無法讀取
- <numpy.lib.npyio.NpzFile object at 0x7f63ce4c8860>
- #按照組數預設的key進行訪問
- >>> npzfile['arr_0']
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- >>> npzfile['arr_1']
- array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
- -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
更加神奇的是,你可以不適用Numpy預設給陣列的Key,而是自己給陣列有意義的Key,這樣就可以不用去猜測自己載入資料是否是自己需要的.
- #資料儲存
- >>> np.savez('newsave_xy',x=x,y=y)
- #讀取儲存的資料
- >>> npzfile=np.load('newsave_xy.npz')
- #按照儲存時設定組數key進行訪問
- >>> npzfile['x']
- array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- >>> npzfile['y']
- array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
- -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
簡直不能太爽,深度學習中,有時候你儲存了訓練集,驗證集,測試集,還包括他們的標籤,用這個方式儲存起來,要啥載入啥,檔案數量大大減少,也不會到處改檔名去.
numpy.savez_compressed
這個就是在前面numpy.savez的基礎上加了壓縮,前面我介紹時尤其註明numpy.savez是得到的檔案打包,不壓縮的.這個檔案就是對檔案進行打包時使用了壓縮,可以理解為壓縮前各npy的檔案大小不變,使用該函式比前面的numpy.savez得到的npz檔案更小.
注:函式所需引數和numpy.savez一致,用法完成一樣.
2.儲存到文字檔案
numpy.savetxt
儲存陣列到文字檔案上,可以直接開啟檢視檔案裡面的內容.
引數介紹
numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
fname:檔名/檔案路徑,如果檔案字尾是
.gz,檔案將被自動儲存為.gzip格式,np.loadtxt可以識別該格式
X:要儲存的1D或2D陣列
fmt:控制資料儲存的格式
delimiter:資料列之間的分隔符
newline:資料行之間的分隔符
header:檔案頭步寫入的字串
footer:檔案底部寫入的字串
comments:檔案頭部或者尾部字串的開頭字元,預設是'#'
encoding:使用預設引數
使用
- >>> import numpy as np
- #生成資料
- >>> x = y = z = np.ones((2,3))
- >>> x
- array([[1., 1., 1.],
- [1., 1., 1.]])
- #儲存資料
- np.savetxt('test.out', x)
- np.savetxt('test1.out', x,fmt='%1.4e')
- np.savetxt('test2.out', x, delimiter=',')
- np.savetxt('test3.out', x,newline='a')
- np.savetxt('test4.out', x,delimiter=',',newline='a')
- np.savetxt('test5.out', x,delimiter=',',header='abc')
- np.savetxt('test6.out', x,delimiter=',',footer='abc')
儲存下來的檔案都是友好的,可以直接開啟看看有什麼變化.
numpy.loadtxt
根據前面定製的儲存格式,相應的載入資料的函式也得變化.
引數介紹
numpy.loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes')
fname:檔名/檔案路徑,如果檔案字尾是
.gz或.bz2,檔案將被解壓,然後再載入
dtype:要讀取的資料型別
comments:檔案頭部或者尾部字串的開頭字元,用於識別頭部,尾部字串
delimiter:劃分讀取上來值的字串
converters:資料行之間的分隔符
.......後面不常用的就不寫了
使用
- np.loadtxt('test.out')
- np.loadtxt('test2.out', delimiter=',')
參考資料:
官方API-Routines
//***********************************************************我是分割線*********************************************************
Python list和numpy array的儲存和讀取方法
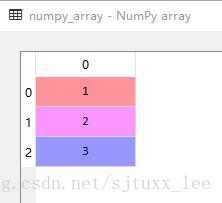
numpy array儲存為.npy
儲存:
import numpy as np
numpy_array = np.array([1,2,3])
np.save('log.npy',numpy_array )
讀取:
import numpy as np
numpy_array = np.load('log.npy')
執行結果:
list儲存為.txt
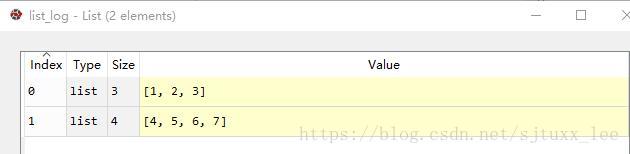
儲存:
list_log = []
list_log.append([1,2,3])
list_log.append([4,5,6,7])
file= open('log.txt', 'w')
for fp in list_log:
file.write(str(fp))
file.write('\n')
file.close()
這樣儲存的結果list_log的每一行在txt也是分行的
執行結果:

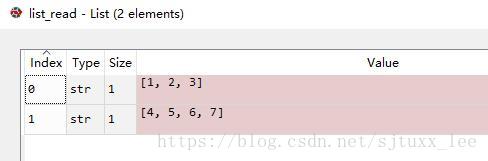
讀取:
file=open('log.txt', 'r')
list_read = file.readlines()
讀出來list_read的結果仍然是一行一行的
執行結果:
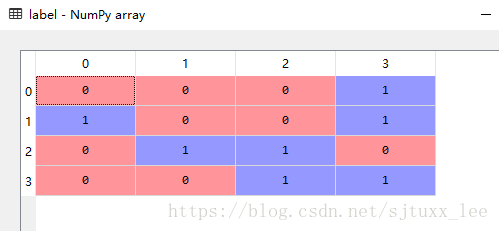
.txt檔案讀取為int
label_path = 'C:/Users/leex/Desktop/label.txt'
file = open((label_path),'r')
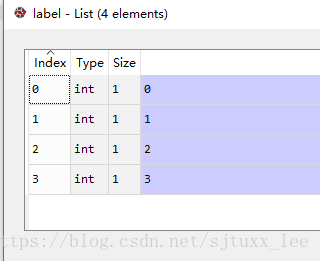
label = [int(x.strip()) for x in file]
file.close()
執行結果:
如果不加int(),則讀取的為字串格式
還有一種常見的情況是label是以one-hot編碼儲存的
可以用np.loadtxt讀取
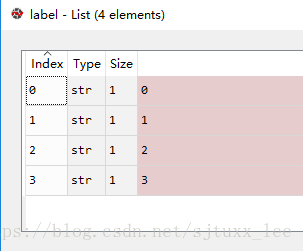

import numpy as np
label_path = 'C:/Users/leex/Desktop/label.txt'
label = np.loadtxt(label_path, dtype=np.int64)
執行結果