
InnoDB關鍵特性之自適應hash索引
一、索引的資源消耗分析
1、索引三大特點
1、小:只在一個到多個列建立索引
2、有序:可以快速定位終點
3、有棵樹:可以定位起點,樹高一般小於等於3
2、索引的資源消耗點
1、樹的高度,順序訪問索引的資料頁,索引就是在列上建立的,資料量非常小,在記憶體中;
2、資料之間跳著訪問
1、索引往表上跳,可能需要訪問表的資料頁很多;
2、通過索引訪問表,主鍵列和索引的有序度出現嚴重的不一致時,可能就會產生大量物理讀;
資源消耗最厲害:通過索引訪問多行,需要從表中取多行資料,如果無序的話,來回跳著找,跳著訪問,物理讀會很嚴重。
二、自適應hash索引原理
1、原理過程
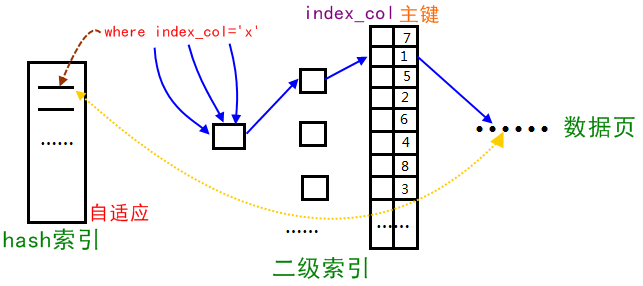
Innodb儲存引擎會監控對錶上二級索引的查詢,如果發現某二級索引被頻繁訪問,二級索引成為熱資料,建立雜湊索引可以帶來速度的提升,則:
1、自適應hash索引功能被開啟
mysql> show variables like '%ap%hash_index'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | innodb_adaptive_hash_index | ON | +----------------------------+-------+ 1 row in set (0.01 sec)
2、經常訪問的二級索引資料會自動被生成到hash索引裡面去(最近連續被訪問三次的資料),自適應雜湊索引通過緩衝池的B+樹構造而來,因此建立的速度很快。
2、特點
1、無序,沒有樹高
2、降低對二級索引樹的頻繁訪問資源
索引樹高<=4,訪問索引:訪問樹、根節點、葉子節點
3、自適應
3、缺陷
1、hash自適應索引會佔用innodb buffer pool;
2、自適應hash索引只適合搜尋等值的查詢,如select * from table where index_col='xxx',而對於其他查詢型別,如範圍查詢,是不能使用的;
3、極端情況下,自適應hash索引才有比較大的意義,可以降低邏輯讀。
三、監控與關閉
1、狀態監控
mysql> show engine innodb status\G …… Hash table size 34673, node heap has 0 buffer(s) 0.00 hash searches/s, 0.00 non-hash searches/s
1、34673:位元組為單位,佔用記憶體空間總量
2、通過hash searches、non-hash searches計算自適應hash索引帶來的收益以及付出,確定是否開啟自適應hash索引
2、限制
1、只能用於等值比較,例如=, <=>,in
2、無法用於排序
3、有衝突可能
4、MySQL自動管理,人為無法干預。
3、自適應雜湊索引的控制
由於innodb不支援hash索引,但是在某些情況下hash索引的效率很高,於是出現了adaptive hash index功能,但是通過上面的狀態監控,可以計算其收益以及付出,控制該功能開啟與否。
預設開啟,建議關掉,意義不大。可以通過 set global innodb_adaptive_hash_index=off/on 關閉和開啟該功能。
@author:http://www.cnblogs.com/geaozhang/一、索引的資源消耗分析
1、索引三大特點
1、小:只在一個到多個列建立索引
2、有序:可以快速定位終點
3、有棵樹:可以定位起點,樹高一般小於等於3
2、索引的資源消耗點
1、樹的高度,順序訪問索引的資料頁,索引就是在列上建立的,資料量非常小,在記憶體中;
2、資料之間跳著訪問
1、索引往表上跳,可能需要訪問表的資料頁很多;
2、通過索引訪問表,主鍵列和索引的有序度出現嚴重的不一致時,可能就會產生大量物理讀;
資源消耗最厲害:通過索引訪問多行,需要從表中取多行資料,如果無序的話,來回跳著找,跳著訪問,物理讀會很嚴重。
二、自適應hash索引原理
1、原理過程
Innodb儲存引擎會監控對錶上二級索引的查詢,如果發現某二級索引被頻繁訪問,二級索引成為熱資料,建立雜湊索引可以帶來速度的提升,則:
1、自適應hash索引功能被開啟
mysql> show variables like '%ap%hash_index'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | innodb_adaptive_hash_index | ON | +----------------------------+-------+ 1 row in set (0.01 sec)
2、經常訪問的二級索引資料會自動被生成到hash索引裡面去(最近連續被訪問三次的資料),自適應雜湊索引通過緩衝池的B+樹構造而來,因此建立的速度很快。
2、特點
1、無序,沒有樹高
2、降低對二級索引樹的頻繁訪問資源
索引樹高<=4,訪問索引:訪問樹、根節點、葉子節點
3、自適應
3、缺陷
1、hash自適應索引會佔用innodb buffer pool;
2、自適應hash索引只適合搜尋等值的查詢,如select * from table where index_col='xxx',而對於其他查詢型別,如範圍查詢,是不能使用的;
3、極端情況下,自適應hash索引才有比較大的意義,可以降低邏輯讀。
三、監控與關閉
1、狀態監控
mysql> show engine innodb status\G …… Hash table size 34673, node heap has 0 buffer(s) 0.00 hash searches/s, 0.00 non-hash searches/s
1、34673:位元組為單位,佔用記憶體空間總量
2、通過hash searches、non-hash searches計算自適應hash索引帶來的收益以及付出,確定是否開啟自適應hash索引
2、限制
1、只能用於等值比較,例如=, <=>,in
2、無法用於排序
3、有衝突可能
4、MySQL自動管理,人為無法干預。
3、自適應雜湊索引的控制
由於innodb不支援hash索引,但是在某些情況下hash索引的效率很高,於是出現了adaptive hash index功能,但是通過上面的狀態監控,可以計算其收益以及付出,控制該功能開啟與否。
預設開啟,建議關掉,意義不大。可以通過 set global innodb_adaptive_hash_index=off/on 關閉和開啟該功能。