第二章 大型網站架構模式
內容梳理
模式定義:每一個模式描述了一個在我們周圍不斷重複發生的問題及該問題解決方案的核心。這樣,你就能一次又一次的使用該方案而不必做重複的工作。
2.1 網站架構模式
解決大型網站高併發訪問、海量資料處理、高可靠執行的問題,為實現大型網站高效能、高可用、易伸縮、可擴充套件、安全等目標提出的解決方案。
2.1.1 分層
將系統在橫向維度上切分成幾個部分,每個部分負責單一職責,通過上層對下層的依賴和呼叫組成完整系統。

各層之間獨立,只要維持呼叫介面不變,各層根據具體問題獨立演化發展而不影響其他層。開發時要嚴格遵循分層架構約束,禁止跨層呼叫和逆向呼叫。分層架構師邏輯上的,大的分層內部還可以繼續分層。
2.1.2 分割
在縱向維度上對軟體進行切分。 將不同的功能和服務進行分割,包裝成高內聚低耦合的模組單元,便於開發、維護和部署,提高網站的併發處理能力和功能擴充套件能力。
不同模組在邏輯上還是物理部署上都可以是獨立的,通過遠端呼叫協作工作。
2.1.3 分散式
使用更多的計算機完成同樣的功能,解決高併發問題。隨著CPU、記憶體、儲存資源的增多,處理的併發訪問和資料量就越大。
分散式帶來的其他問題:(1)通過網路呼叫服務,影響系統性能;(2)伺服器個數增多,宕機概率增大,降低系統可用性;(3)難以保持資料一致性和分散式事務;(4)網站依賴錯綜複雜,開發管理維護困難。
常用的分散式方案:(1)分散式應用和服務:將各個模組分散式部署,提高網站效能和併發性、加快開發和釋出速度、減少資料庫連線等資源消耗,還能使不同應用複用共同的服務,便於業務功能擴充套件。
(2)分散式靜態資源:動靜分離,將JS/CSS等網站的靜態資源獨立分散式部署,採用獨立域名訪問。減輕應用伺服器負載壓力、加快瀏覽器併發載入速度、利於網站分工合作。
(3)分散式資料和儲存:單機無法處理以P為單位的海量資料。將資料進行分散式儲存,NoSQL應運而生。
(4)分散式計算:處理規模龐大的計算業務,移動計算,將計算程式分發到資料所在位置以加速計算和分散式計算。
(5)此外,還有支援伺服器配置實時更新的分散式配置、實現併發和協同的分散式鎖、支援雲端儲存的分散式檔案系統等。
2.1.4 叢集
多臺伺服器上部署相同應用程式,通過負載均衡裝置共同對外提供服務,有良好併發特性,提高系統可用性。
2.1.5 快取
將資料存放在距離計算最近的位置來加快處理速度,是改善軟降效能的第一手段。
CDN:部署在離使用者最近的網路運營商。
反向代理:部署在網站前端,請求到達網站的資料中心時,最先訪問反向代理伺服器(快取網站的靜態資源)。
本地快取:應用伺服器本地快取。
分散式快取:將資料快取在一個專門的分散式快取叢集中。
使用快取前提條件:(1)資料訪問不均衡;(2)資料在某時間段內有效
2.1.6 非同步
將一個業務操作分成多階段,每個階段通過共享資料進行協作。單伺服器內部通過多執行緒共享記憶體佇列實現非同步,分散式系統中通過分散式訊息佇列實現。
非同步架構是典型的生產者-消費者模型,非同步訊息佇列特徵:(1)提高系統可用性;(2)網站響應速度;(3)消除併發訪問高峰。
非同步方式處理業務可能會對使用者體驗和業務流程造成影響。
2.1.7 冗餘
伺服器規模較大時,發生宕機是必然事件,通過冗餘實現服務高可用。
方式:熱備份、冷備份、災備資料中心
2.1.8 自動化
減少人為干預,使釋出過程自動化可有效減少故障。包括自動化程式碼管理、自動化測試、自動化安全監測、自動化部署。
對線上生產環境進行自動化監控,包括自動化報警、自動化失效轉移、自動化失效恢復、自動化降級、自動化資源分配。
2.1.9 安全
使用密碼和手機校驗碼進行身份驗證、對網路通訊進行加密、驗證碼識別、編碼轉換、過濾、風險控制等手段。
2.2 架構模式在新浪微博中的應用
新浪微博已經發展成集社交、媒體、遊戲、電商等多位一體的生態系統。
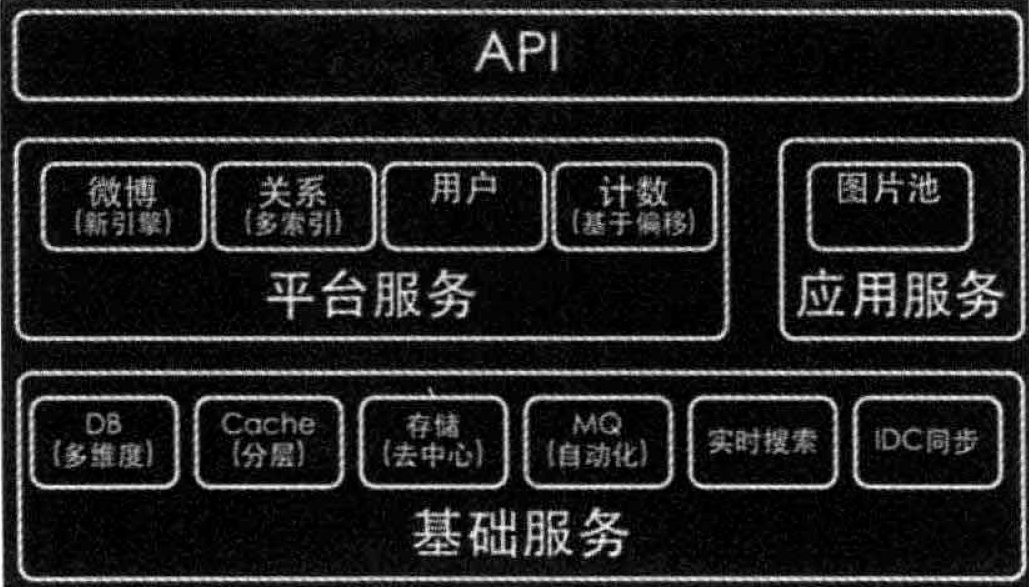
系統分為三個層次:
(1)最下層的基礎服務層:提供資料庫、快取、儲存、搜尋等基礎資料服務,是技術基礎。
(2)中間層是平臺服務和應用服務層:核心服務是微博、關係和使用者,通過依賴呼叫和共享基礎資料構成新浪微博的業務基礎。
(3)最上層是API和業務層:客戶端和第三方應用呼叫API。
新浪微博早期架構中,微博釋出使用同步推模式,使用者發表微博後系統將微博插入資料庫所有粉絲訂閱列表中,大量資料庫寫操作,降低系統性能。後來改為非同步推拉結合模式,使用者發表微博後系統將微博加入訊息佇列後立即返回,提高響應速度。訊息佇列消費者將微博推送給線上粉絲,非線上使用者登入後根據關注列表拉取微博訂閱列表。
“刷微博”使用多級快取機制,通過使用資料冗餘複製、開發自動化工具提高系統可用性。
本章結構