
使用tesseract3.01字型檔訓練教程完成全國企業資訊中心簡單驗證碼的字型檔建立。
使用tesseract訓練教程完成全國企業資訊中心湖南驗證碼的字型檔建立。
準備工具
Tesseract3.01和3.02。下載名稱:tesseract-ocr-setup-3.02.02.exe
下載chi_sim.traindata字型檔(中文字型檔)
下載jTessBoxEitor用於修改box檔案 (簡單來說通過這個工具獲取字型的形狀)
Win7環境下執行,需要管理員許可權
1. 準備
利用jTessBoxEitor將jpg影象轉換成tif影象。
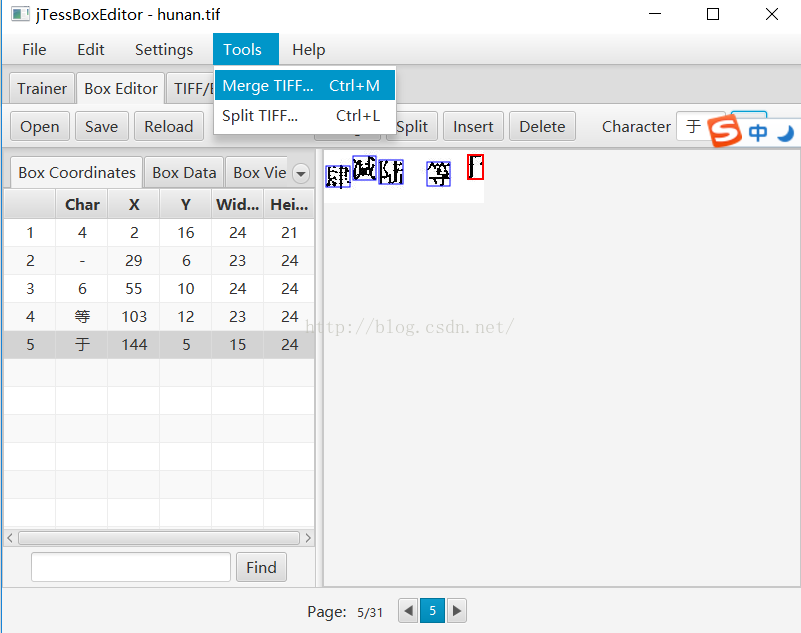
進入介面選取所有的jpg格式的驗證碼影象
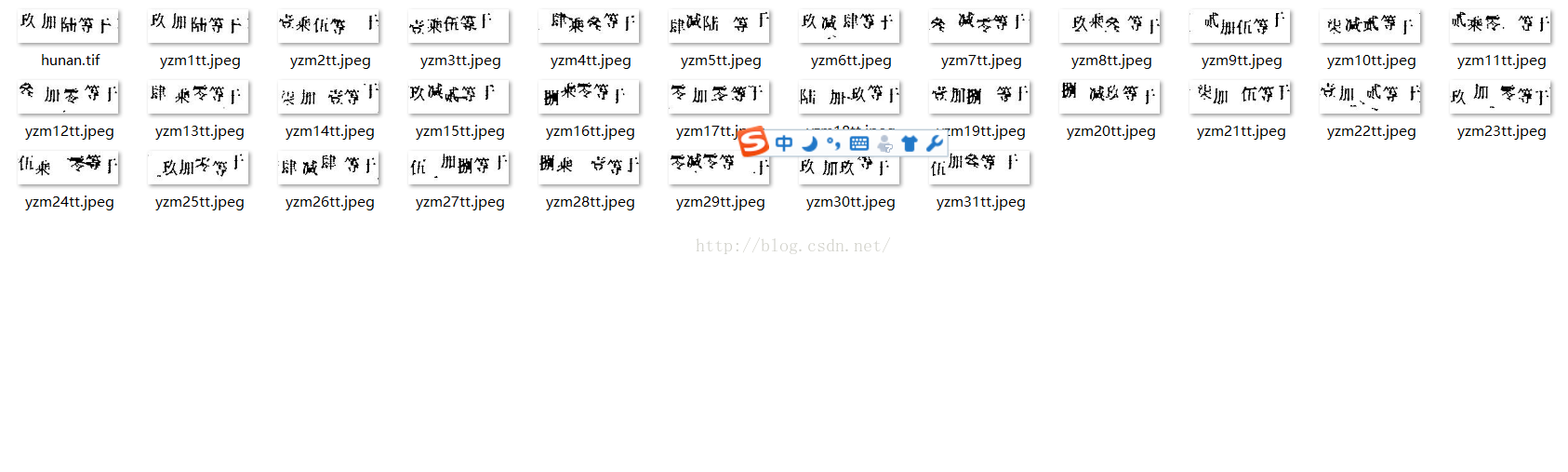
生成了名為hunan.tif綜合所有圖片的驗證碼圖片。
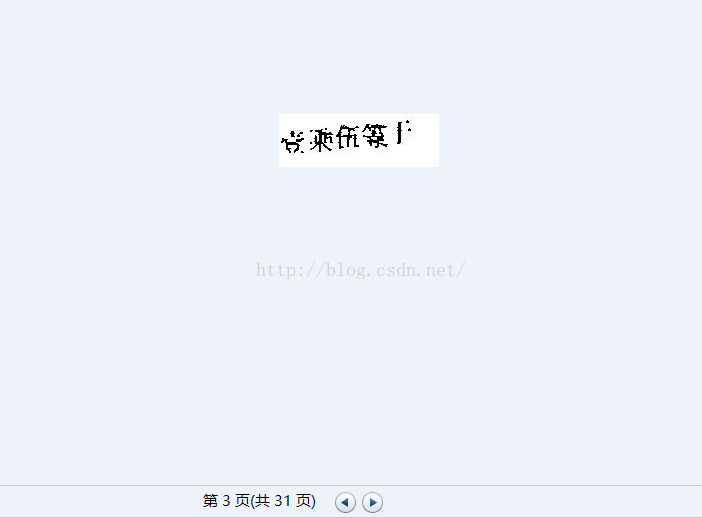
接著為了訓練字型檔。要生成.box檔案。在目錄下用cmd執行。
命令如下:tesseract hunan.tif hunan batch.nochopmakebox(我是預設字型檔改成中文簡體字型檔)如不是。請輸入tesseracthunan.tif hunan -l chi_sim batch.nochop makebox(-l chi_sim是為了呼叫chi_sim也就是中文簡體字型檔)

將圖片檔案和box檔案放在同一目錄
2用jTessBoxEditor.jar開啟tif檔案,然後根據實際情況修改box檔案
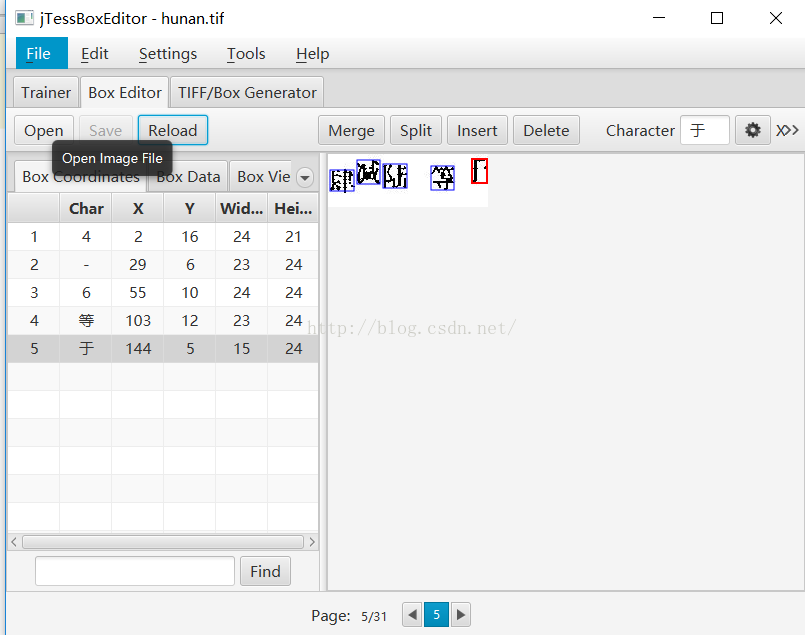
在此處為了識別方便講繁體中文或者簡體中文的漢字全部轉換為阿拉伯數字,同時將漢字元號改成符號,如加改成+。
這個識別率在樣本在一定範圍內會增加,但是如果樣本數量過多,導致字元特徵過多,會讓識別率降低。所以建議根據需求決定自己做的樣本空間的大小。
3.如何修改新增漢字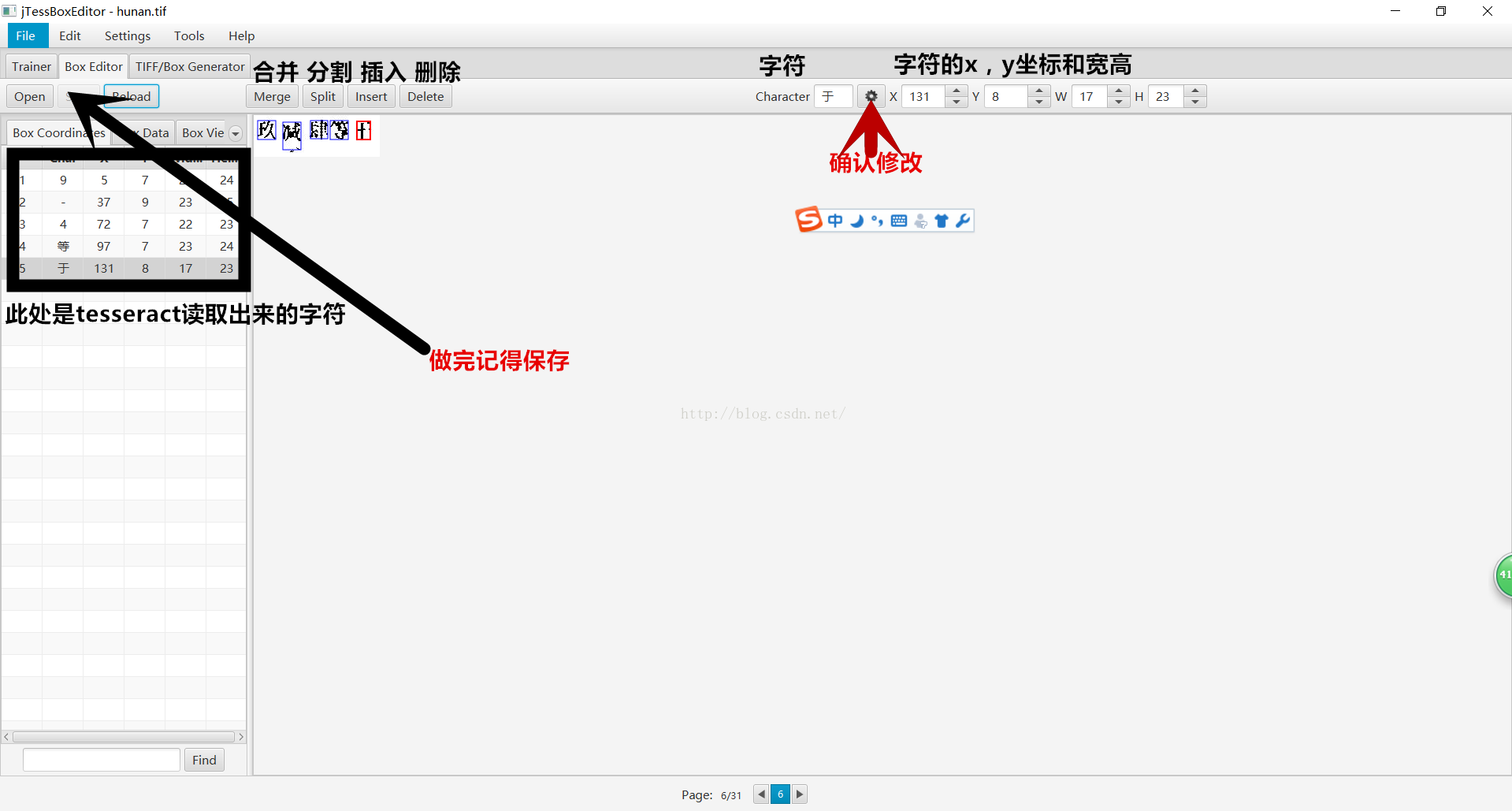
功能在圖片上已經說明,根據說明調整字型結構和提高識別率。
Eg:
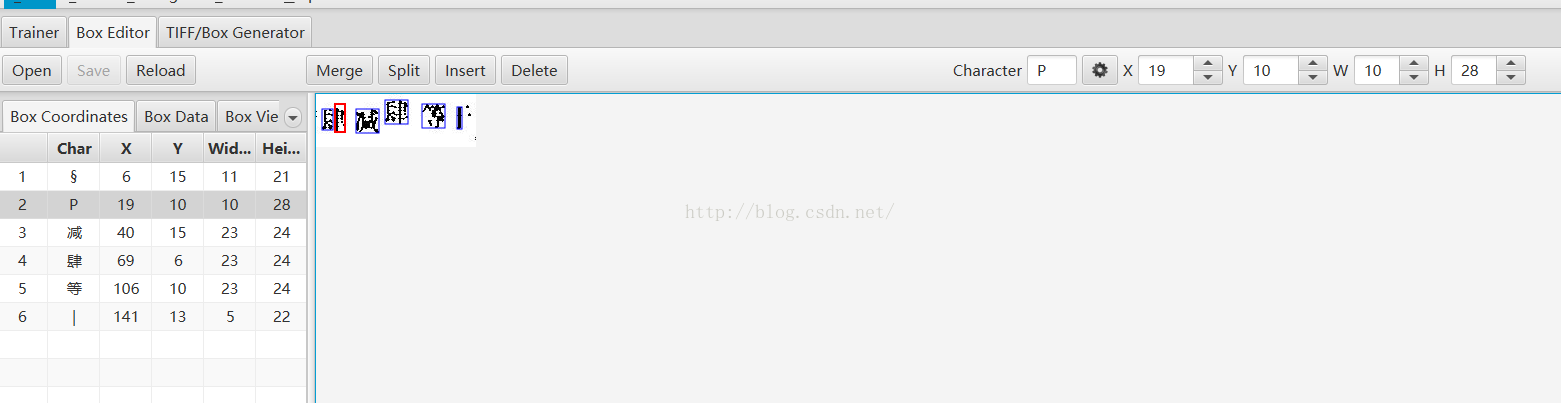
需要改成
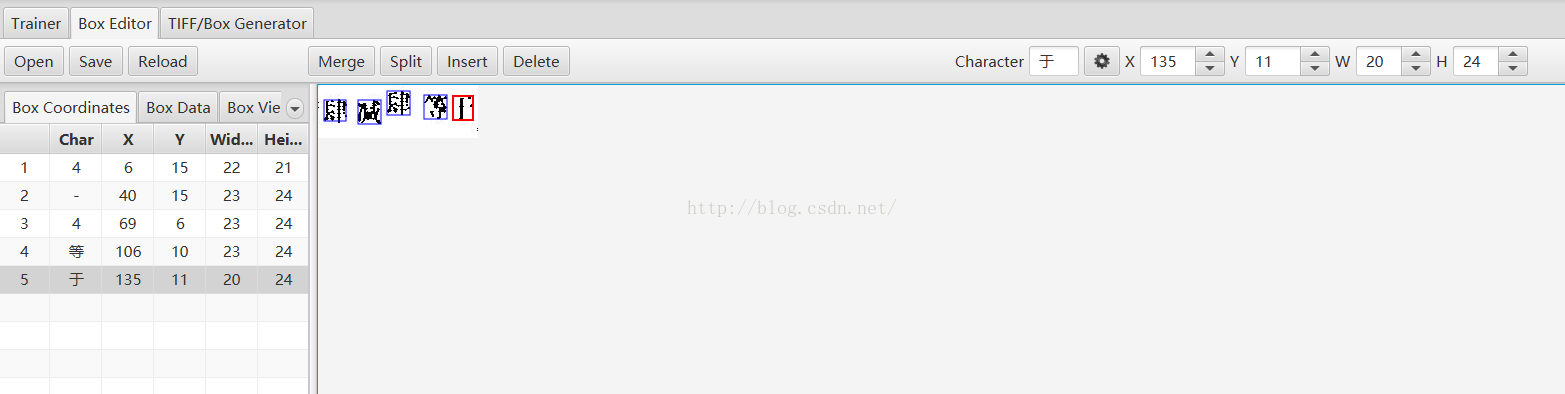
因為tesseract識別的是字元特徵。所以可以直接改成數字方便java端讀取。
4.生成.tr檔案
命令:tesseract hunan.tif hunan nobatchbox.train
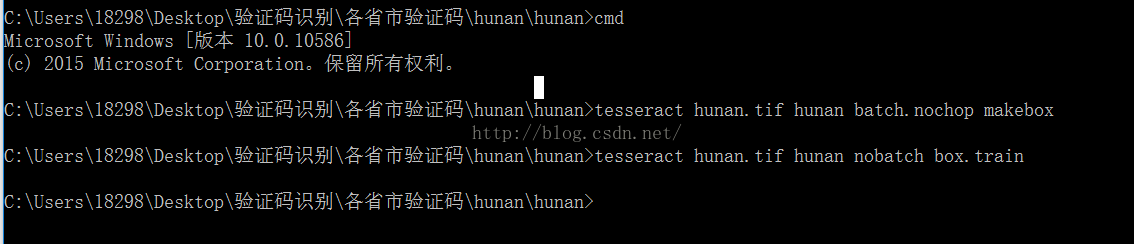
5.接著生成一個unicharset檔案
命令:unicharset_extractor hunan.box
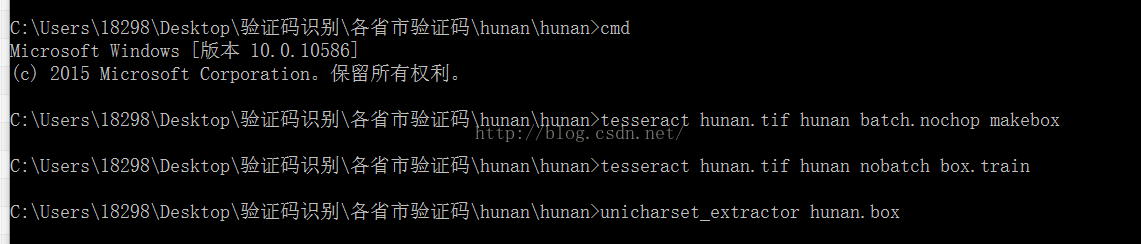
6.新建一個font_properties.txt檔案
裡面內容寫入
湖南 0 0 0 0 0表示普通預設字型
字型屬性檔案
<fontname><italic> <bold> <fixed> <serif> <fraktur>
在<字型>是一個字串命名的字型 ; <斜體>,<加粗>,<固定>,<襯線>和<哥特體>都是簡單的0或1標誌指示字型是與否的屬性。
例如湖南 1 1 0 0 0
就是表示湖南字型斜體加粗.
7.執行命令
mftraining -F font_properties.txt -Uunicharset -O unicharset hunan.tr
cntraining hunan.tr

生成
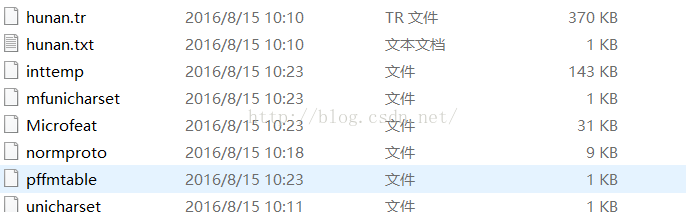
8合併檔案
a) unicharset改名為hunan. unicharset
b) inttemp改名為hunan.inttemp
c) normproto改名為hunan. normproto
d) pffmtable改名為hunan. Pffmtable
在cmd下執行combine_tessdatahunan.
生成湖南驗證碼字型檔。

9.將湖南字型檔加入Tesseract-OCR 安裝目錄下的tessdata
10.接著對新建的字型檔進行測試
將hunan.tif加入tesseract字型檔中進行測試。

輸入命令:tesseract hunan,tif hunan -l hunan

發現結果和預期一樣字型檔建立成功。
接著利用這種字型檔可大大提高對特定驗證碼的識別率。
同時給出的圖片驗證碼都是經過腐蝕演算法二值化處理的圖片。經過這樣處理對各省市的驗證碼處理率可達到80%