
【演算法】 多特徵融合粒子濾波
多特徵融合粒子濾波
我們從標題開始 《多特徵融合粒子濾波》 這裡包含了 多特徵、融合和粒子濾波
1.多特徵
常用的視覺特徵有以下五種:
1.1顏色特徵
顏色特徵是跟蹤演算法中最為常用的視覺特徵,對目標的角度旋轉、尺寸改變和區域性遮擋等干擾情況均具有很好的穩定性。
1.2邊緣特徵
邊緣特徵主要描述了目標的大致輪廓和內部突變情況,且受外部環境光照的影響較小,可以在一定程度上彌補顏色直方圖無法表達目標空間資訊的不足。
1.3紋理特徵
紋理特徵重點關注影象中目標區域內部的組織結構及排列規律,表徵了顏色和邊緣特徵所不能描述的屬性資訊。紋理特徵通常由一組辨別特徵描述子表示,描述子在區域性區域進行定義,具有關於比例縮放、角度旋轉和光照變化的不變性。將這類描述子即紋理特徵運用到某種目標跟蹤框架中,可以得到相應的跟蹤演算法。
1.4光流特徵
光流特徵也是跟蹤領域使用較多的視覺特徵,光流資訊的獲取需要求解影象中所有畫素的速度和方向,所以特徵提取的時間代價相對較大,往往無法滿足目標跟蹤對實時性的要求。
1.5小波特徵
小波表達的優勢是可以在不同的尺度下、從不同的方向來表徵目標畫素的內在規律,非常適用於需要對由粗到精的差分運動進行分析和估計的場合。
2.融合
2.1基於特徵選擇的融合方法
其基本思想是選取當前時刻下最可靠的若干個特徵來跟蹤目標,一旦某些特徵在跟蹤期間失效,則立即選取另外的特徵完成接下來的目標跟蹤,以確保跟蹤過程的可靠性。這類方法的難點在於,如何設計好的特徵選擇標準和特徵切換策略。
2.2基於多特徵資訊加權的融合方法
但融合權值多設計為一組固定值,即每次都採用相同的權值對各種特徵進行加權。顯然,這類方法沒有考慮同一特徵在不同情形下的分辨能力,當某個特徵資訊發生較大變化而其權值保持不變時,融合後的觀測模型將很難符合實際情況,極易產生跟蹤漂移甚至目標丟失等錯誤。
2.3特徵資訊自適應融合
這類演算法主要依據候選區域與目標區域的相似性度量結果,來實現特徵融合權值的動態調整。然而,對於多個視覺特徵中的某種特徵,如果不能有效地區分候選區域與背景區域的相似性程度,那麼該特徵用於目標跟蹤時將受背景干擾而難以準確地突出目標屬性。因此,特徵融合權值的分配還應考慮特徵對目標和背景的判別能力,使其傾向判別性較高的特徵以增加跟蹤演算法魯棒性。
以上來源於:(代東林.基於多特徵融合與粒子濾波的目標跟蹤[D].重慶:重慶大學.碩士論文.2014.04 )
3.粒子濾波(重點)
度娘如是說:
濾波: 濾波是將訊號中特定波段頻率濾除的操作,是抑制和防止干擾的一項重要措施。是根據觀察某一隨機過程的結果,對另一與之有關的隨機過程進行估計的概率理論與方法
粒子濾波: 通過尋找一組在狀態空間中傳播的隨機樣本來近似的表示概率密度函式,用樣本均值代替積分運算,進而獲得系統狀態的最小方差估計的過程,這些樣本被形象的稱為“粒子”,故而叫粒子濾波。
濾波是啥? 牛人是這樣說的:
一位專業課的教授給我們上課的時候,曾談到:filtering is weighting(濾波即加權)。濾波的作用就是給不同的訊號分量不同的權重。最簡單的loss passfilter, 就是直接把低頻的訊號給0權重,而給高頻部分1權重。對於更復雜的濾波,比如維納濾波, 則要根據訊號的統計知識來設計權重。從統計訊號處理的角度,降噪,可以看成濾波的一種。降噪的目的在於突出訊號本身而抑制噪聲影響。從這個角度,降噪就是給訊號一個高的權重而給噪聲一個低的權重。維納濾波就是一個典型的降噪濾波器。
作者:王航臣 連結:https://www.zhihu.com/question/34809533/answer/61345742 來源:知乎
其實卡爾曼、粒子是叫估計器estimator。估計estimate當前值叫濾波filtering,估計過去叫平滑smoothing,估計未來叫預測prediction。不過為了方便,往往就叫濾波器了。至於高通,低通,則是濾波幾個相互正交的分類:低通,高通開環,閉環(有無iterate)線性,非線性時變,定常動態系統,靜態系統最小方差與否等等比如steady-state時卡爾曼濾波是低通濾波,等等。卡爾曼濾波,包括KF(線性),EKF(非線性),UKF(非線性),SRUKF(非線性)等,要求後驗是高斯。PF則不僅可以處理非線性,還可以處理非高斯。其實還有噪聲是否白噪聲的問題,不過有色噪聲可以近似成白噪聲經過一個濾波器的話,就好處理。還有噪聲是否零均值的問題,這個問題看似簡單,其實很多很重要,比如如何處理感測器數值的漂移,乃至如何確定確定性的干擾。
作者:高斯白乎 連結:https://www.zhihu.com/question/34809533/answer/60577240 來源:知乎
明確一下插值、濾波、預測這三者的區別或許能解答題主的疑惑插值,就是用過去的資料來擬合過去的資料,比如牛頓插值,拉格朗日插值濾波,是用當前和過去的資料來求取當前的資料預測,是指用當前和過去的資料來求取未來的資料至於題主提到的卡爾曼濾波演算法,是一種遞推預測濾波演算法,演算法中即涉及到濾波,也涉及到對下一時刻資料的預測所以單純從濾波功能來看,無論低通高通帶通帶阻,還是卡爾曼、粒子等濾波演算法,目的都是一致,即是為了更好的求取當前的資料
作者:雄帥 連結:https://www.zhihu.com/question/34809533/answer/100244205 來源:知乎
Kalman filter 基於線性遞推公式來濾波。
Particle filter 基於馬爾可夫蒙特卡洛方法通過抽樣來濾波【知乎】
3.1多次提到的卡爾曼濾波( Kalman)是個啥?
狀態方程 + 觀測方程
有人是這麼說的:
用一句最簡單的話來說,卡爾曼濾波是來幫助我們做測量的,大家一定不明白測量幹嘛搞那麼複雜?測量長度拿個尺子比一下,測量溫度拿溫度表測一下不就完了嘛。的確如此,如果你要測量的東西很容易測準確,沒有什麼隨機干擾,那真的不需要勞駕卡爾曼先生。但在有的時候,我們的測量因為隨機干擾,無法準確得到,卡爾曼先生就給我們想了個辦法,讓我們在干擾為高斯分佈的情況下,得到的測量均方誤差最小,也就是測量值擾動最小,看起來最平滑。
還是舉例子最容易明白。我最近養了只小兔子,忍不住拿小兔子做個例子嘻嘻。
每天給兔子拔草,看她香甜地吃啊吃地,就忍不住關心一下她的體重增長情況。那麼我們就以小兔子的體重作為研究物件吧。假定我每週做一次觀察,我有兩個辦法可以知道兔子的體重,一個是拿體重計來稱:或許你有辦法一下子就稱準兔子的體重(獸醫通常都有這辦法),但現在為了體現卡爾曼先生理論的魅力,我們假定你的稱實在很糟糕,誤差很大,或者兔子太調皮,不能老實呆著,彈簧秤因為小兔子的晃動會產生很大誤差。儘管有誤差,那也是一個不可失去的渠道來得到兔子的體重。還有一個途徑是根據書本上的資料,和兔子的年齡,我可以估計一下我的小兔子應該會多重,我們把用稱稱出來的叫觀察量,用資料估計出來的叫估計值,無論是觀察值還是估計值顯然都是有誤差的,假定誤差是高斯分佈。現在問題就來了,按照書本上說我的兔子該3公斤重,稱出來卻只有2.5公斤,我究竟該信哪個呢?如果稱足夠準,兔子足夠乖,卡爾曼先生就沒有用武之地了呵呵,再強調一下是我們的現狀是兔兔不夠乖,稱還很爛呵呵。在這樣惡劣的情景下,卡爾曼先生告訴我們一個辦法,仍然可以估計出八九不離十的兔兔體重,這個辦法其實也很直白,就是加權平均,把稱稱出來的結果也就是觀測值和按照書本經驗估算出來的結果也就是估計值分別加一個權值,再做平均。當然這兩個權值加起來是等於一的。也就是說如果你有0.7分相信稱出來的體重,那麼就只有0.3分相信書上的估計。說到這裡大家一定更著急了,究竟該有幾分相信書上的,有幾分相信我自己稱的呢?都怪我的稱不爭氣,沒法讓我百分一百信賴它,還要根據書上的資料來做調整。好在卡爾曼先生也體會到了我們的苦惱,告訴我們一個辦法來決定這個權值,這個辦法其實也很直白,就是根據以往的表現來做決定,這其實聽起來挺公平的,你以前表現好,我就相信你多一點,權值也就給的高一點,以前表現不好,我就相信你少一點,權值自然給的低一點。那麼什麼是表現好表現不好呢,表現好意思就是測量結果穩定,方差很小,表現不好就是估計值或觀測值不穩定,方差很大。想象你用稱稱你的哦兔子,第一次1公斤第二次10公斤,第三次5公斤,你會相信你的稱嗎,但是如果第一次3公斤第二次3.2公斤,第三次2.8公斤,自然我就相信它多一點,給它一個大的權值了。
有了這個權值,下面的事情就很好辦了。很顯然卡爾曼先生是利用多次觀察和估計來達到目的的,我們也只能一步一步地調整我們的觀察和估計值,來漸漸達到準確的測量,所以整個演算法是遞迴的,需要多次重複調整的。調整的過程也很簡單,就是把實測值(稱出來的體重)和估計值(書上得來的體重)比較一下,如果估計值比測量值小,那就把估計值加上他們之間的偏差作為新的估計值,當然前面要加個係數,就是我們前面說的加權係數,這個地方我要寫個公式,因為很簡單就能說明白
比如我們的觀查值是Z,估計值是X, 那麼新的估計值就應該是 Xnew = X+K(Z-X),從這個公式可以看到,如果X估計小了,那麼新的估計值會加上一個量K(Z-X), 如果估計值大了,大過Z了,那麼新的估計值就會減去一個量K(Z-X),這就保證新的估計值一定比現在的準確,一次一次遞迴下去就會越來越準卻了,當然這裡面很有作用的也是這個K,也就是我們前面說的權值,書上都把他叫卡爾曼增益。。。(Xnew = X+K(Z-X) = X(1-K)+KZ ,也就是說估計值X的權值是1-k,而觀察值Z的權值是k,究竟k 取多大,全看估計值和觀察值以前的表現,也就是他們的方差情況了)
http://blog.csdn.net/karen99/article/details/7771743
3.2蒙特卡洛(Monte Carlo)又是啥?
蒙特卡洛方法也稱統計模擬方法,是二十世紀四十年代中期由於科學技術的發展和電子計算機的發明,而被提出的一種以概率統計理論為指導的一類非常重要的數值計算方法。是指使用隨機數(或更常見的偽隨機數)來解決很多計算問題的方法。與它對應的是確定性演算法。【百度】如果用一句話總結蒙特卡洛的用處,那麼就是:複雜概率的簡單求解辦法。
3.3粒子濾波物體跟蹤過程
(形象的解釋粒子濾波過程)
一直都覺得粒子濾波是個挺牛的東西,每次試圖看文獻都被複雜的數學符號搞得看不下去。一個偶然的機會發現了Rob Hess(http://web.engr.oregonstate.edu/~hess/)實現的這個粒子濾波。從程式碼入手,一下子就明白了粒子濾波的原理。根據維基百科上對粒子濾波的介紹(http://en.wikipedia.org/wiki/Particle_filter),粒子濾波其實有很多變種,Rob Hess實現的這種應該是最基本的一種,Sampling Importance Resampling (SIR),根據重要性重取樣。下面是我對粒子濾波實現物體跟蹤的演算法原理的粗淺理解:
(1) 初始化階段-提取跟蹤目標特徵
該階段要人工指定跟蹤目標,程式計算跟蹤目標的特徵,比如可以採用目標的顏色特徵。具體到Rob Hess的程式碼,開始時需要人工用滑鼠拖動出一個跟蹤區域,然後程式自動計算該區域色調(Hue)空間的直方圖,即為目標的特徵。直方圖可以用一個向量來表示,所以目標特徵就是一個N*1的向量V。
(2) 搜尋階段-放狗
好,我們已經掌握了目標的特徵,下面放出很多條狗,去搜索目標物件,這裡的狗就是粒子particle。狗有很多種放法。比如,a)均勻的放:即在整個影象平面均勻的撒粒子(uniform distribution);b)在上一幀得到的目標附近按照高斯分佈來放,可以理解成,靠近目標的地方多放,遠離目標的地方少放。Rob Hess的程式碼用的是後一種方法。狗放出去後,每條狗怎麼搜尋目標呢?就是按照初始化階段得到的目標特徵(色調直方圖,向量V)。每條狗計算它所處的位置處影象的顏色特徵,得到一個色調直方圖,向量Vi,計算該直方圖與目標直方圖的相似性。相似性有多種度量,最簡單的一種是計算sum(abs(Vi-V)).每條狗算出相似度後再做一次歸一化,使得所有的狗得到的相似度加起來等於1.
(3) 決策階段
我們放出去的一條條聰明的狗向我們發回報告,“一號狗處影象與目標的相似度是0.3”,“二號狗處影象與目標的相似度是0.02”,“三號狗處影象與目標的相似度是0.0003”,“N號狗處影象與目標的相似度是0.013”…那麼目標究竟最可能在哪裡呢?我們做次加權平均吧。設N號狗的影象畫素座標是(Xn,Yn),它報告的相似度是Wn,於是目標最可能的畫素座標X = sum(XnWn),Y = sum(YnWn).
(4) 重取樣階段Resampling
既然我們是在做目標跟蹤,一般說來,目標是跑來跑去亂動的。在新的一幀影象裡,目標可能在哪裡呢?還是讓我們放狗搜尋吧。但現在應該怎樣放狗呢?讓我們重溫下狗狗們的報告吧。“一號狗處影象與目標的相似度是0.3”,“二號狗處影象與目標的相似度是0.02”,“三號狗處影象與目標的相似度是0.0003”,“N號狗處影象與目標的相似度是0.013”…綜合所有狗的報告,一號狗處的相似度最高,三號狗處的相似度最低,於是我們要重新分佈警力,正所謂好鋼用在刀刃上,我們在相似度最高的狗那裡放更多條狗,在相似度最低的狗那裡少放狗,甚至把原來那條狗也撤回來。這就是Sampling Importance Resampling,根據重要性重取樣(更具重要性重新放狗)。
(2)->(3)->(4)->(2)如是反覆迴圈,即完成了目標的動態跟蹤。
根據我的粗淺理解,粒子濾波的核心思想是隨機取樣+重要性重取樣。既然我不知道目標在哪裡,那我就隨機的撒粒子吧。撒完粒子後,根據特徵相似度計算每個粒子的重要性,然後在重要的地方多撒粒子,不重要的地方少撒粒子。所以說粒子濾波較之蒙特卡洛濾波,計算量較小。這個思想和RANSAC演算法真是不謀而合。RANSAC的思想也是(比如用在最簡單的直線擬合上),既然我不知道直線方程是什麼,那我就隨機的取兩個點先算個直線出來,然後再看有多少點符合我的這條直線。哪條直線能獲得最多的點的支援,哪條直線就是目標直線。想法非常簡單,但效果很好。
http://www.cnblogs.com/yangyangcv/archive/2010/05/23/1742263.html
3.4概率統計中的一些知識
(1) 貝葉斯定理
貝葉斯定理是關於隨機事件A和B的條件概率(或邊緣概率)的一則定理。
其中P(A|B)是在B發生的情況下A發生的可能性。
貝葉斯公式:給定一組所關心事件的先驗概率,如果你收到新的資訊,那麼更新你對於事件發生概率的法則為:

某城市發生了一起汽車撞人逃跑事件,該城市只有兩種顏色的車,藍色15%,綠色85%,事發時有一個人在現場看見了,他指證是藍車。但是根據專家在現場分析,當時那種條件能看正確的可能性是80%。那麼,肇事的車是藍車的概率到底是多少?

作者:熊貓 連結:https://www.zhihu.com/question/51448623/answer/140173977 來源:知乎
貝葉斯公式

全概率公式
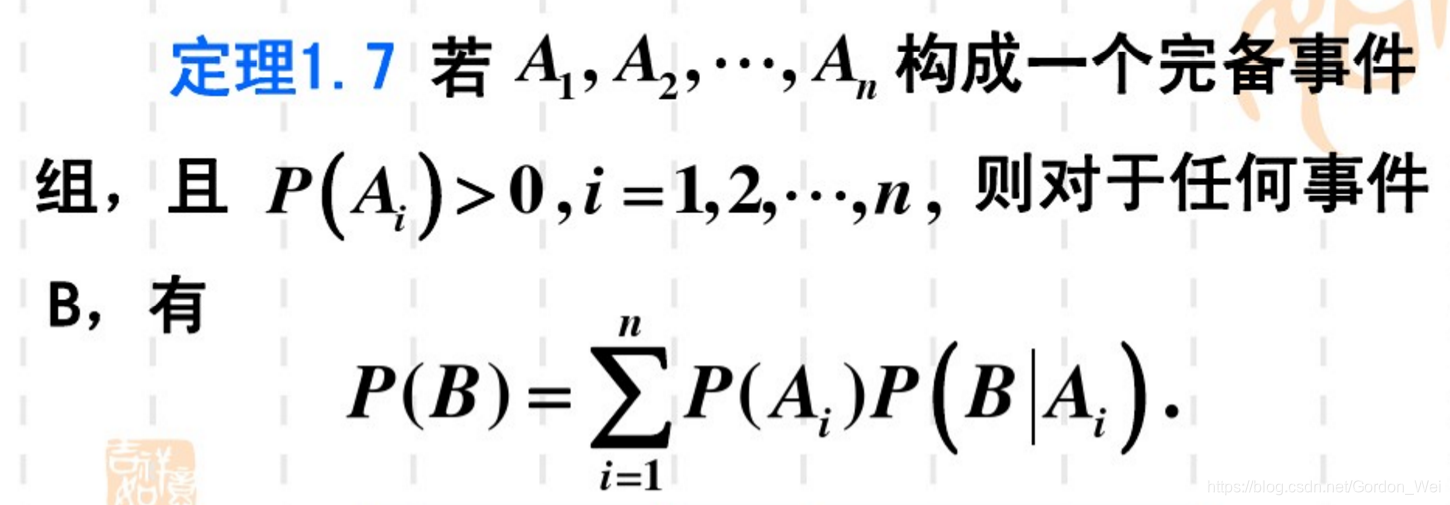
(2) 先驗概率與後驗概率
通常稱各“原因”的概率(Ai)為先驗概率,“結果”B發生的條件下各“原因Ai”的概率P(Ai|B)為後驗概率,前者往往是根據以往經驗確定的一種主觀概率,而後者是在結果B發生之後對原因Ai的重新認識。
可以說,貝葉斯公式解決的是追根溯源問題。
也可以說,貝葉斯公式是利用先驗概率去求後驗概率。
https://wenku.baidu.com/view/316eb9df50e2524de5187e70.html
(3) 似然函式與最大似然估計(maximum likelihood)
下面給出似然函式跟最大似然估計的定義。
我們假設f是一個概率密度函式,那麼x→f(x|θ) 是一個條件概率密度函式(θ是固定的)
反過來θ→f(x|θ)叫做似然函式(x是固定的)一般似然函式寫成L(θ|x)=f(x|θ) θ是因變數。
而最大似然估計就是求在θ的定義域中,當似然函式取得最大值時θ的大小。意思就是,當後驗概率最大時θ的大小。也就是說要求最有可能的原因。由於對數函式不會改變大小關係,有時候會將似然函式求一下對數,方便計算。
http://blog.csdn.net/yewei11/article/details/50537648
(4) 最大後驗概率(maximum a posteriori, MAP)
1、P(h)來代表還沒有訓練資料前,假設h擁有的初始概率。P(h)常被稱為h的先驗概率(prior probability),它反映了我們所擁有的關於h是一正確假設的機會的背景知識。如果沒有這一先驗知識,那麼可以簡單地將每一候選假設賦予相同的先驗概率。
2、P(D)代表將要觀察的訓練資料D的先驗概率(換言之,在沒有確定某一假設成立時,D的概率)。
3、P(D|h)代表假設h成立的情形下觀察到資料D的概率。更一般地,我們使用P(x|y)代表給定y時x的概率。
在機器學習中,我們感興趣的是P(h|D),即給定訓練資料D時h成立的概率。
P(h|D)被稱為h的後驗概率(posteriorprobability),因為它反映了在看到訓練資料D後h成立的置信度。
應注意,後驗概率P(h|D)反映了訓練資料D的影響;相反,先驗概率P(h)是獨立於D的。
貝葉斯法則是貝葉斯學習方法的基礎,因為它提供了從先驗概率P(h)以及P(D)和P(D|h)計算後驗概率P(h|D)的方法。
貝葉斯公式
直觀可看出,P(h|D )隨著P(h)和P(D|h)的增長而增長。同時也可看出P(h|D)隨P(D)的增加而減少,這是很合理的,因為如果D獨立於h被觀察到的可能性越大,那麼D對h的支援度越小。
http://blog.csdn.net/u011067360/article/details/22879807
Bhattacharyya係數(相似性度量)
對於特徵匹配,通常使用二次距離、歐氏距離以及Kullback-Leible 等距離函式來度量特徵之間的相似程度,但在視覺特徵直方圖中,更為普遍的是利用巴特查理亞(Bhattacharyya)係數。該係數作為一種針對散度量的測量手段,在幾何上代表了兩個向量夾角的餘弦取值。對於特徵直方圖的分佈相似性而言,它和貝葉斯間的估計誤差最小即近乎為最優。另一方面,Bhattacharyya係數的取值均在[0,l]範圍內變化,有利於直觀方便地反映特徵匹配的完美程度,所以本文選用它來完成特徵的相似性度量。兩個連續分佈q(u)與 p(u)的Bhattacharyya係數定義為:
代東林.基於多特徵融合與粒子濾波的目標跟蹤[D].重慶:重慶大學.碩士論文.2014.04