
情感分析背後的樸素貝葉斯及實現基於評論語料庫的影評情感分析(附程式碼)
一.情感分析的介紹
一句話概括情感分析:判斷出一句評價/點評/影評的正/負傾向性;
情感分析是一個二分類的問題,一種是可以直接判斷正負,一種是可以判斷情感偏向正負性的一個打分;
二,詞袋模型(向量空間模型)
2.1情感分析的流程
中文分詞處理,停用詞的去除,對否定詞做處理,情感分析方法主要可以分為兩大類,基於詞典的方法和機器學習方法。
把對文字內容的處理簡化為向量空間中的向量運算,並且它以空間上的相似度表達語義的相似度;
中文分詞用於切割句子,卡方統計能夠計算類別和特徵項之間的i相關程度;
常見的分類機器學習演算法包括:樸素貝葉斯分類器,SVM支援向量機,邏輯迴歸,j決策樹等;
2.2詞袋模型
給定一個長的文字,這樣的段落雖然有順序,但是它對於主題和情感的資訊是不依賴於這個順序的;也就是說給一個文字,我們的第一步是將這樣的序列模型變為一個袋子,這樣的袋子是一堆詞,這個袋子中的詞與詞的順序已經完全打亂;
詞袋模型的實現->(向量空間模型)
例如:我非常喜歡《肖申克的救贖》->我/非常/喜歡/肖申克的救贖
先分詞,再對詞語的順序進行打亂,怎麼打亂呢?就是我們忽略哪個詞出現在哪個詞之前,我們只需要統計'我'這個詞出現的次數,那麼怎樣在計算機中表示這個詞呢,我們需要用一個1-hot的方式進行表示,所謂1-hot,指的是每一個詞,實際上是對應計算機中的一個序號,叫做index,一個詞對應於一個向量,當且僅當這個詞的index對應為1。這樣就可以將現實生活中的每一個詞語對映為計算機裡的每一個數字。通過一個加法運算對向量求和,最後得到一個文字向量,實際上就是這個文章中的詞出現次數的一個統計;
將一個詞典看作是一個高維的歐式空間,每一句話看作是這些奇向量的簡單的線性組合,比如這裡有n個詞,那麼我們的句子就是由這n個片語成的一個n維空間的向量。這個向量的維度,是和字典的大小的維度是一樣的。
詞袋模型應用:情感分析;文章主題分類;垃圾郵件過濾器;影象分類
1.忽略文章/評論中詞語的順序;
2.每個詞對應空間中一個單位向量;
3.文章/評論是詞語的加權總和;
三,基於樸素貝葉斯的情感分類器
1.貝葉斯公式介紹

假設知道事件B的結果,我們要更新事件A的結果的概率,這個概率我們將其稱之為後驗概率,為了,為了計算這個後驗概率,我們可以先計算A發生的概率以及在A發生的情況下B發生的概率;
2.樸素貝葉斯分類器
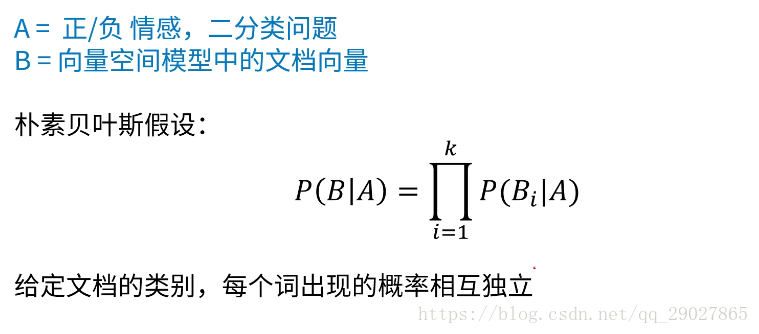
一旦給定了A的假設,也就是說我們知道了A發不發生,我們可以把B的概率分解成所有單獨的B的概率的乘積;
通過條件獨立假設,如果要來估計一篇文件正向的概率的話,我只要知道每一個詞在正向文件中出現的概率,然後把所有的概率乘起來,就可以得到。
我們真正要計算的是一個後驗概率,但我們要知道一個後驗概率是正比於先驗概率乘以似然函式。
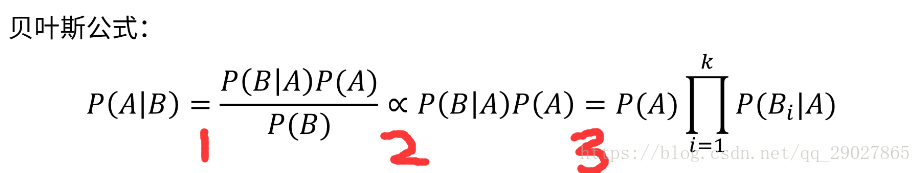
現在我們解釋下這個公式:我們首先通過貝葉斯公式得到第一步,第一個等式是我們的貝葉斯公式;第二步是因為現在我們要看A的概率,與B的概率沒有關係,故近似等於;第三步是將剛才的概率分成小概率的乘積;
這個公式和兩項有關:第一個東西是A本身的先驗概率,第二個東西是每個詞語在正負向文件中出現的概率;

注意:後兩個加起來的概率並不為1,它們並不互補;因為它們所基於的條件不同,但是P(Bi=1|A=1)+P(Bi=0|A=1)=1

演算法包括兩部分:給定一個數據集,我們先估計這三個量:P(A=1),P(B_i=1|A=1),P(B_i=1|A=0),估計這三個量是為了統計,一旦我們拿到了這三個量後,我們只需要根據之前的貝葉斯公式來進行分類即可,即將三個量乘起來。
3.基於樸素貝葉斯的情感分類

常用工具包:SnowNLP(處理中文句子),NLTK;
基於評論集的情感分析程式碼實現:
import pandas as pd
from snownlp import SnowNLP
# 資料預處理
def pre_data(name):
train = pd.read_csv(name,encoding="gbk")
# 切分資料集
train_content = train["str"]
# 將dataframe的資料集轉化為list型別
train_content = train_content.values.tolist()
return train,train_content
# 將情感打分存在列表
def mood_score(sentences):
Pos_score = []
for i in sentences:
sentence = str(i[0])
s = SnowNLP(sentence)
Pos_score.append(s.sentiments)
# 將列表轉化為Series
Pos_score_test = pd.Series(Pos_score)
return Pos_score_test
# 儲存為新的csv檔案
def save_csv(new_name,list_new,df_test,csv_name):
df_test[str(new_name)] = list_new
df_test.to_csv(str(csv_name), encoding='utf_8_sig')
if __name__ == "__main__":
train,content = pre_data("big_V.csv")
pos_score = mood_score(content)
save_csv("pos_score",pos_score,train,"new_pos.csv")歡迎拍磚~