
基於list_head實現的通用核心Hash表
● 儲存在glib_htable裡的物件由外部而不是內部負責建立,這個物件必須直接或間接地組合了list_head成員(間接組合,包含下文中的glib_hentry即可),這裡引用UML中的術語組合,意在強調不是聚合關係。
● 刪除操作的語義是從Hash表移去物件的連結,但釋放物件是可選的。
● 桶的個數由外部指定而不是內部維護。
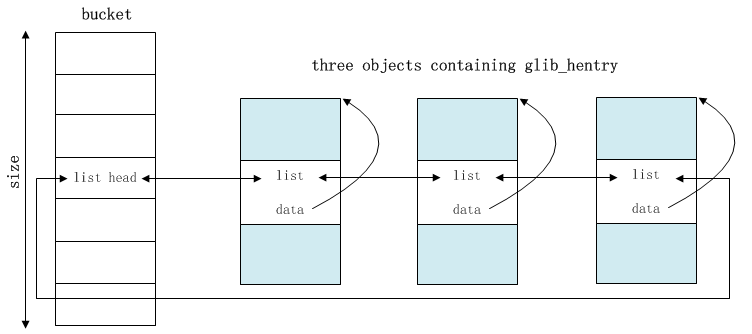
綜上可見glib_htable是使用物件已存在的內嵌成員list_head來連結到Hash表中的,比一般的通用Hash表,每個表項節省了1個指標的空間,如下圖所示。
結構定義 1
 struct glib_hentry {
struct glib_hentry {

2
 struct list_head list;
struct list_head list;3
void*data;4
 };
};5

6
typedef unsigned int (*glib_htable_hashfun_t)(constvoid*,unsigned int);7
typedef int (*glib_htable_cmpfun_t)(constvoid*, constvoid*);8
typedef void (*glib_htable_cbfun_t)(struct glib_hentry*);9
typedef void (*10
11
struct glib_htable {12
struct list_head *bucket;13
unsigned int size;14
unsigned int vmalloced;15
16
rwlock_t lock;17
18
glib_htable_hashfun_t hashfun;19
glib_htable_cmpfun_t cmpfun;20
glib_htable_cbfun_t cbfun;21
glib_htable_freefun_t freefun;}; 1)glib_hentry抽象了儲存物件的內嵌成員,表示Hash項,也可表示整個物件,這時內嵌成員就是物件本身了,成員data表示物件關聯的任意資料,用於計算hash值,當關聯資料大小<=sizeof(void*)時,可直接強制轉換為data儲存,而不必為資料地址。2)glib_htable抽象了Hash表,size表示桶個數,考慮到size可能很多,需要佔用大塊記憶體,所以在分配連續物理頁失敗的情況下,再使用vmalloc嘗試分配不連續的物理頁,所以引入了vmalloced表示分配方式,非零表示用vmalloc,零則用__get_free_pages;hashfun和cmpfun是實現Hash表的兩個缺一不可的關鍵函式,cbfun用於查詢成功時的回撥處理,如列印、增加引用計數等,freefun用於釋放物件,提供這個回撥介面是為了方便從Hash表移除物件後可以釋放物件,而不必由外部釋放,增加了靈活性。
主要介面
以下所有操作中的第1引數ht表示glib_htable物件。
● 初始化
int glib_htable_init(struct glib_htable *ht, unsigned int size, glib_htable_hashfun_t hashfun, glib_htable_cmpfun_t cmpfun); size表示Hash表桶的個數,hashfun為Hash函式,cmpfun為比較函式;成功時返回0,ht成員cbfun和freefun設定為空,失敗返回ENOMEM。由於可能使用vmalloc分配記憶體,因此不能用於中斷上下文。● 增加
void glib_htable_add(struct glib_htable *ht, struct glib_hentry *he, int num); 在一次同步內新增多個物件,he為指向物件Hash項的指標,num為個數。● 查詢
struct glib_hentry* glib_htable_get(struct glib_htable *ht, constvoid*data);struct glib_hentry* glib_htable_rget(struct glib_htable *ht, constvoid*data);struct glib_hentry* glib_htable_cget(struct glib_htable *ht, constvoid*data, int(*cmp)(conststruct glib_hentry*, void*), void*arg);struct glib_hentry* glib_htable_crget(struct glib_htable *ht, constvoid*data, int(*cmp)(conststruct glib_hentry*, void*), void*arg);struct glib_hentry* glib_htable_cget_byidx(struct glib_htable *ht, unsigned int*bucket, int(*cmp)(conststruct glib_hentry*, void*), void*arg);struct glib_hentry* glib_htable_crget_byidx(struct glib_htable *ht, unsigned int*bucket, int(*cmp)(conststruct glib_hentry*, void*), void*arg); 從上到下依次為正向查詢、反向查詢、正向條件查詢、反向條件查詢、按桶定位的正向條件查詢、按桶定位的反向條件查詢,data為物件關聯資料,cmp為自定義的比較函式,arg為cmp所帶的自定義引數,bucket為桶索引,若查詢成功,則bucket更新為物件所在的桶索引。以上所有操作,當失敗時返回NULL。● 刪除
void glib_htable_del(struct glib_htable *ht, struct glib_hentry *he, int num);void glib_htable_del_bydata(struct glib_htable *ht, constvoid**data, int num); 第1個按物件Hash項刪除,第2個按物件關聯資料刪除,num表示個數,若ht成員freefun非空,則釋放物件。● 清空
void glib_htable_clear(struct glib_htable *ht); 在一次同步內刪除所有的物件,若ht成員freefun非空,則釋放物件。● 銷燬
void glib_htable_free(struct glib_htable *ht); 僅釋放所有桶佔用的記憶體,應在glib_htable_clear後呼叫。由於可能使用vfree釋放記憶體,因此不能用於中斷上下文。介面實現
其它介面實現比較簡單,略過講解。對於查詢介面,如果增加一個引數來指示遍歷方向,那麼雖然介面總數減半,但在使用特別是在一個迴圈內呼叫時,每次都進行不必要的方向判斷而降低了效能,所以對於正向和反向遍歷,每個都給出一個介面,正如c庫中的strchr與strrchr、c++容器中的iterator與reverse_iterator,這樣一來更清晰明確。在實現上除了遍歷方向不同外,其它程式碼都相同,因此為避免手工編碼冗餘,使用了3組巨集來生成。
輔助函式巨集生成 1
#define DEFINE_GLIB_HTABLE_GET_HELP(name) \ 2staticstruct glib_hentry*__glib_htable_##name(struct glib_htable *ht, unsigned int hash, constvoid*data) \3
{\4
struct glib_hentry *he; \5
\6
 glib_htable_list_##name(he,&ht->bucket[hash],list){ \
glib_htable_list_##name(he,&ht->bucket[hash],list){ \ glib_htable_list_##name(he,
glib_htable_list_##name(he,7
if(ht->cmpfun(he->data,data)){ \8
if(ht->cbfun) \9
ht->cbfun(he); \10
return he; \11
 } \
} \12
} \13
\14
return NULL; \15
}1617
DEFINE_GLIB_HTABLE_GET_HELP(get)18
DEFINE_GLIB_HTABLE_GET_HELP(rget)19
20
#define DEFINE_GLIB_HTABLE_COND_GET_HELP(name) \21staticstruct glib_hentry*__glib_htable_c##name(struct glib_htable *ht, unsigned int hash, int(*cmp)(conststruct glib_hentry*, void*), void*arg) \22
{ \23
struct glib_hentry *he; \24
\25
glib_htable_list_##name(he,&ht->bucket[hash],list){ \26
if(cmp(he, arg)){ \27
if(ht->cbfun) \28
ht->cbfun(he); \29
return he; \30
} \31
} \32
\33
return NULL; \34
}3536
DEFINE_GLIB_HTABLE_COND_GET_HELP(get)37
DEFINE_GLIB_HTABLE_COND_GET_HELP(rget) 生成巨集為DEFINE_GLIB_HTABLE_GET_HELP和DEFINE_GLIB_HTABLE_COND_GET_HELP,展開後就有了__glib_htable_get(rget)和__glib_htable_cget(crget) 4個不加鎖的函式,用於實現對應的加鎖介面。glib_htable_list_get和glib_htable_list_rget分別是巨集list_for_each_entry和list_for_each_entry_reverse的別名。普通查詢巨集生成 1
#define DEFINE_GLIB_HTABLE_GET(name) \ 2struct glib_hentry*glib_htable_##name(struct glib_htable *ht, constvoid*data) \3
{ \4
struct glib_hentry *he; \5
unsigned int h = ht->hashfun(data,ht->size); \6
\7
read_lock_bh(&ht->lock); \8
he = __glib_htable_##name(ht, h, data); \9
read_unlock_bh(&ht->lock); \10
\11
return he; \12
}1314
DEFINE_GLIB_HTABLE_GET(get)15
DEFINE_GLIB_HTABLE_GET(rget) 呼叫輔助函式__glib_htable_get(rget)實現,生成巨集為DEFINE_GLIB_HTABLE_GET,展開後就有了glib_htable_get(rget)介面。條件查詢巨集生成 1
#define DEFINE_GLIB_HTABLE_COND_GET(name) \ 2struct glib_hentry*glib_htable_c##name(struct glib_htable *ht, constvoid*data, int(*cmp)(conststruct glib_hentry*, void*), void*arg) \3
{ \4
struct glib_hentry *he; \5
unsigned int h = ht->hashfun(data,ht->size); \6
\7
read_lock_bh(&ht->lock); \8
he = __glib_htable_c##name(ht, h, cmp, arg); \9
read_unlock_bh(&ht->lock); \10
\11
return he; \12
}1314
DEFINE_GLIB_HTABLE_COND_GET(get)15
DEFINE_GLIB_HTABLE_COND_GET(rget)16
17
#define DEFINE_GLIB_HTABLE_COND_GET_BYIDX(name) \18struct glib_hentry*glib_htable_c##name##_byidx(struct glib_htable *ht, unsigned int*bucket, int(*cmp)(conststruct glib_hentry*, void*), void*arg) \19
{ \20
unsigned int h; \21
struct glib_hentry *he = NULL; \22
\23
read_lock_bh(&ht->
相關推薦
基於list_head實現的通用核心Hash表
由於linux核心中的struct list_head已經定義了指向前驅的prev指標和指向後繼的next指標,並且提供了相關的連結串列操作方法,因此為方便複用,本文在它的基礎上封裝實現了一種使用開鏈法解決衝突的通用核心Hash表glib_htable,提供了初始化、增加、查詢、刪除、清空和
linux核心 hash表的基本使用
栗子如下: #include <stdio.h> #include <stdlib.h> #include <string.h> #include "hlist.h" typedef struct list_test{ struct hlist_no
linux c實現通用hash表
通用雜湊散列表C語言實現 此部落格只有程式碼,hash表概念等,請自行學習。此次hash中使用連結串列為本人所寫。後續改寫此hash表,使用核心連結串列,詳情請檢視下一個部落格。 程式碼塊 common.h: #pragma once #ifnd
基於JQuery實現表單元素值的回寫
spl sel || etc oos min javascrip odi tar form.jsp: <%@ page language="java" import="java.util.*" pageEncoding="GB2312"%> <!DO
redis sort 實現list與hash的連接 查出sql表的一行
integer 一個 有用 查找 mar join fan 實現 eve SORT 使用外部 key 進行排序 可以使用外部 key 的數據作為權重,代替默認的直接對比鍵值的方式來進行排序。 假設現在有用戶數據如下: uiduser_name_{ui
Hash表分析以及Java實現
這篇部落格主要探討Hash表中的一些原理/概念,及根據這些原理/概念,自己設計一個用來存放/查詢資料的Hash表,並且與JDK中的HashMap類進行比較。 我們分一下七個步驟來進行。 一。 Hash表概念 二 . &n
[日常練習] 2. 基於函式輸出9*9乘法表、交換兩數、判斷閏年、清空/初始化陣列、判斷素數的C語言實現
在C語言學習中,我們知道它是面向過程進行程式設計的,強調的是功能行為,其主要框架為:資料結構+演算法。在此也可以理解成:資料+函式。其實,函式在C語言學習中無時無刻不在使用,最為簡單的#include<stdio.h>,這便是我們程式的開頭,也是我們所呼叫的第一個函式,稱為:庫函式。
php 實現hash表
php的陣列實際上就是hash_table,無論是 數字索引陣列array(1, 2, 3) 還是關聯陣列array(1 => 2, 2=> 4)等等。 PHP中雜湊表結構 假定向PHP陣列中插入三個元素分別為Bucket1,Bucket2,Bucket3,其中Buc
Dubbo原理解析-Dubbo核心實現之基於SPI思想Dubbo核心實現(轉)
SPI介面定義 定義了@SPI註解 public @interface SPI { String value() default ""; //指定預設的擴充套件點 } 只有在介面打了@SPI註解的介面類才會去查詢擴充套件點實現 會依次從這幾個檔案中讀取擴
基於Nginx實現10萬+併發,你應該做的Linux核心優化
由於預設的Linux核心引數考慮的是最通用場景,這明顯不符合用於支援高併發訪問的Web伺服器的定義,所以需要修改Linux核心引數,是的Nginx可以擁有更高的效能; 在優化核心時,可以做的事情很多,不過,我們通常會根據業務特點來進行調整,當Nginx作為靜態web內容
例項:基於4412-實現新增自己的系統呼叫函式(學習《Linux核心設計與實現》 記錄)
學習筆記: 在學習《linux核心設計與實現》過程中,瞭解到: 在Linux中,系統呼叫是使用者空間訪問核心的唯一手段(除異常和陷入之外)。 系統呼叫主要有三個作用: ①:為使用者空間提供一個硬體的抽象介面。 ②:系統呼叫保證了系統的穩定和安全。 ③:為了實現多工和虛擬記憶體(應用程
[CareerCup] 8.10 Implement a Hash Table 實現一個雜湊表
8.10 Design and implement a hash table which uses chaining (linked lists) to handle collisions. 這道題讓我們實現一個簡單的雜湊表,我們採用了最簡單的那種取餘映射的方式來實現,我們使用Cell來儲存一對對的
一個基於POI的通用excel匯入匯出工具類的簡單實現及使用方法
前言: 最近PM來了一個需求,簡單來說就是在錄入資料時一條一條插入到系統顯得非常麻煩,讓我實現一個直接通過excel匯入的方法一次性錄入所有資料。網上關於excel匯入匯出的例子很多,但大多相互借鑑。經過思考,認為一百個客戶在錄入excel的時候,就會有一百個格式版本,所以在實現這個功能之前,所以要統一exc
基於memcached for java 實現通用分散式快取和叢集分散式快取
前提:基於memcached client for java 的基礎進行的二次封裝,實現快取儲存的兩種模式:通用分散式快取和叢集分散式快取。以下是對於memcached client for Java 二次封裝的UML圖。 對於memcached的客戶端初始化在Ca
PHP實現一個hash表(拉鍊法解決hash衝突)程式碼例項
<?php header('Content-type:text/html;charset=utf-8'); class HashTable{ private $buckets; private $size = 10; public function __const
基於jQuery實現表單提交驗證
html表單程式碼: 複製程式碼程式碼如下: <form method="post" action=""> <div class="
在SSM下基於POI實現Excel表的匯入/匯出
對於批量資料的操作,在專案中引進Excel的匯入和匯出功能是個不錯的選擇。對於Excel表的結構,簡單理解可以把它分成三部分(Sheet,Cell,Row),這三部分可以理解為excel表中的頁,列,行。因此,我們想要獲取到某一個單元的內容,可以通過獲取該單元所在的頁數、對應
基於spark實現表的join操作
1. 自連線 假設存在如下檔案: [root@bluejoe0 ~]# cat categories.csv 1,生活用品,0 2,數碼用品,1 3,手機,2 4,華為Mate7,3 每一行的格式為:類別ID,類別名稱,父類ID 現在欲輸出每個類別
linux核心資料結構---hash表
連結串列雖然是最常見的資料結構,但實際使用中,由於連結串列的檢索能力較差,更多的是作為佇列和棧結構使用,如果需要查詢,比如通過pid查詢程序,通過描述符查詢inode,就需要用到檢索更快的資料結構——Hash表。 先來看Hash節點的定義: struct hlist_h
glib庫 hash表實現分析
Hash Table的原理 雜湊表的目的簡單來說是為了實現儲存多個key=>value關係(注意,此處是單項推導,不支援反向查詢),一個比較簡單的模型實現是用一個數組來儲存這些關係,但是在插入資料時,並不在index最小的陣列位置插入,而是直接通過函式算