第十一回 Shader的動態組合
阿新 • • 發佈:2018-12-27
Shader是很奇怪的程式碼,它的長度受到限制,它的動態分支能力很弱,它的指令很昂貴,這些都使得你很難使用一個單一的Shader來處理所有的渲染要求.而各種渲染要求的種類如此之多,如果要為每一種渲染型別都寫一段專一的程式碼的話,那會是一件非常吃力的活,假設我們現在要寫一個材質系統,我們希望它能夠支援各種效果.你會發現隨著支援的效果越來越多,需要寫的Shader的數量會急劇上升,比如: *.一開始我們希望我們的材質系統能夠支援普通光照,我們為這種最簡單的效果寫一個Shader *.然後我們希望這個材質還可以支援貼圖,我們為它再寫一個Shader,現在有兩個Shader了--[支援普通光照,不支援貼圖]和[支援普通光照,支援貼圖] 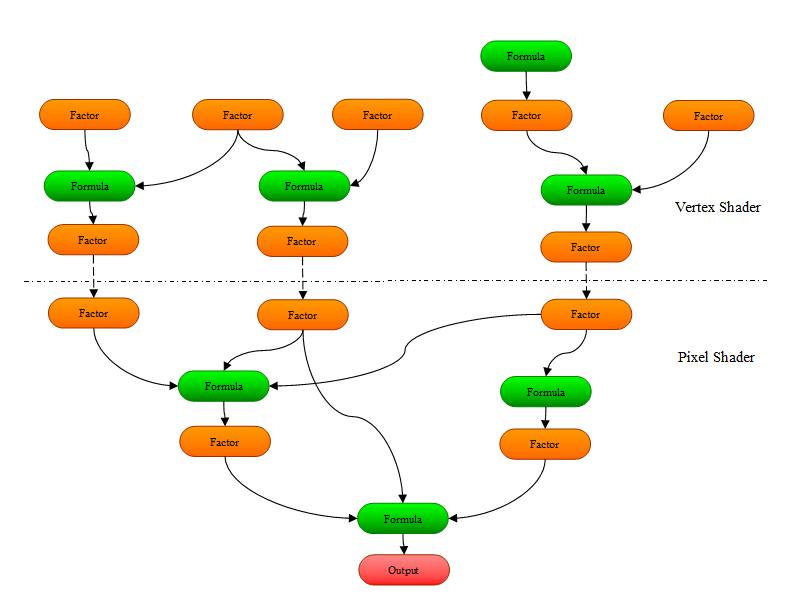
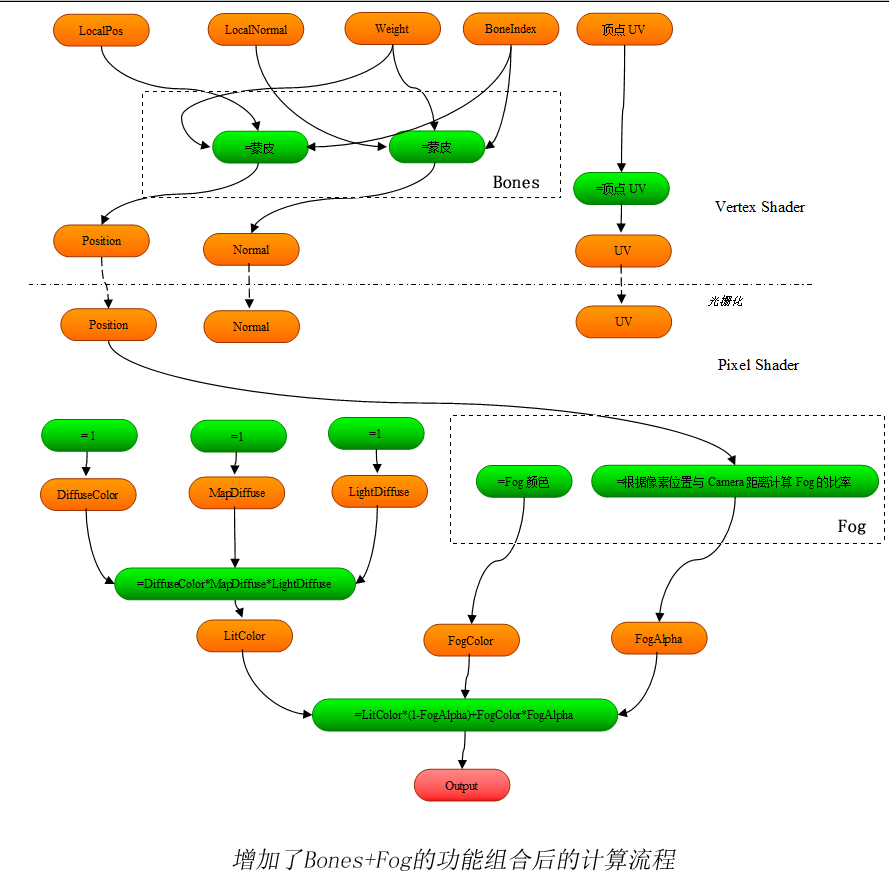
下面說說具體的實現: *.首先我們有一個Shader Library Project的概念,有點類似於vc的一個project,它由若干個檔案組成,它的Build結果是一個Shader庫.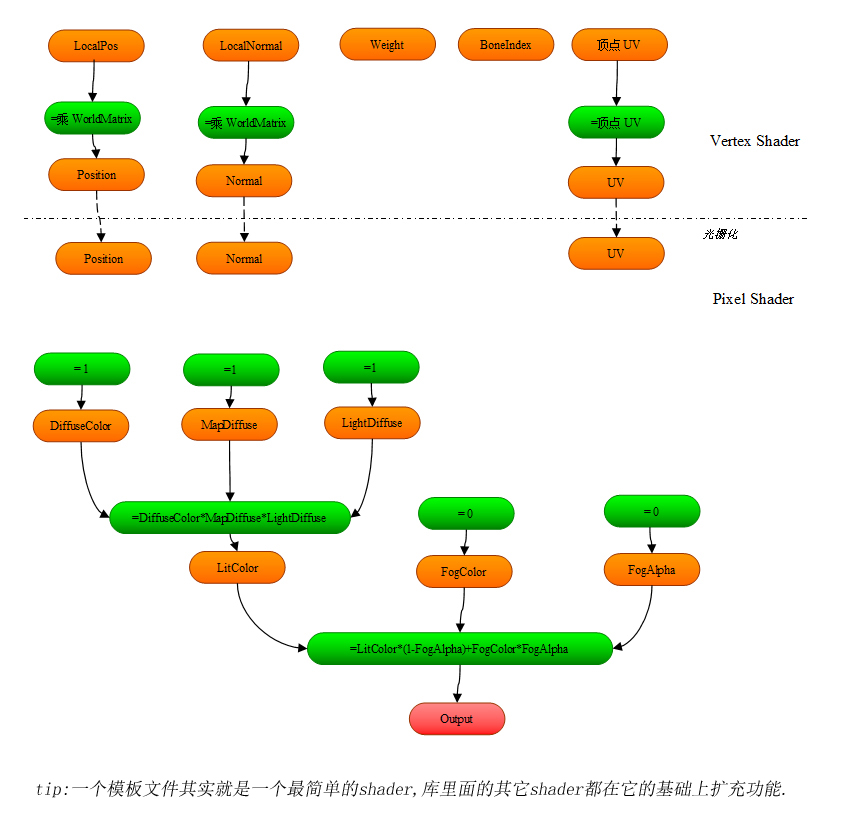 注意這張圖裡沒有包含ShaderConstant,每個Formula都可以自由的訪問所有的ShaderConstant,所以我就不把它畫出來了 *.除了模板以外,專案裡還包括若干個功能(Feature)檔案.一個Feature代表了Shader要實現的一種功能,比如上面說的支援貼圖,支援骨骼動畫等,一個Feature裡面定義了一個或多個Formula,它們都是模板檔案裡定義過的Formula的過載版本.比如:
注意這張圖裡沒有包含ShaderConstant,每個Formula都可以自由的訪問所有的ShaderConstant,所以我就不把它畫出來了 *.除了模板以外,專案裡還包括若干個功能(Feature)檔案.一個Feature代表了Shader要實現的一種功能,比如上面說的支援貼圖,支援骨骼動畫等,一個Feature裡面定義了一個或多個Formula,它們都是模板檔案裡定義過的Formula的過載版本.比如:
下面說說具體的實現: *.首先我們有一個Shader Library Project的概念,有點類似於vc的一個project,它由若干個檔案組成,它的Build結果是一個Shader庫.
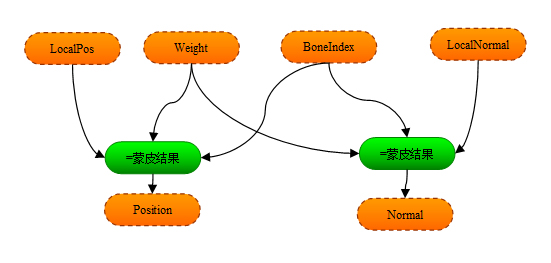
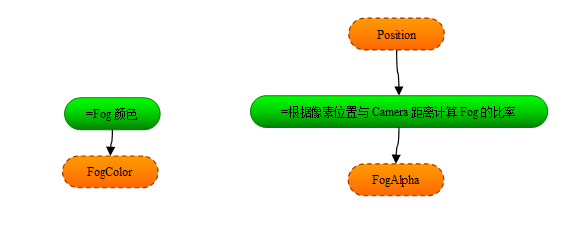
注意這張圖裡沒有包含ShaderConstant,每個Formula都可以自由的訪問所有的ShaderConstant,所以我就不把它畫出來了 *.除了模板以外,專案裡還包括若干個功能(Feature)檔案.一個Feature代表了Shader要實現的一種功能,比如上面說的支援貼圖,支援骨骼動畫等,一個Feature裡面定義了一個或多個Formula,它們都是模板檔案裡定義過的Formula的過載版本.比如:功能DirLight過載了一個formula :
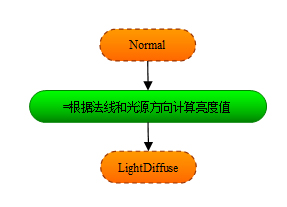
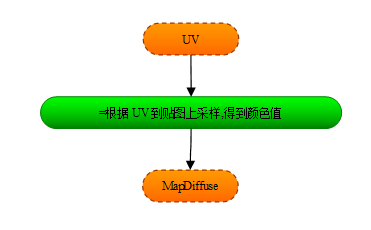
功能DiffuseMap過載了一個formula: