
SQL Server 2005 分割槽模板與例項
一、場景
這一段時間使用SQL Server 2005 對幾個系統進行表分割槽,這幾個系統都有一些特點,比如資料庫某張表持續增長,給資料庫帶來了很大的壓力。
現在假如提供一臺新的伺服器,那麼我們應該如何規劃這個資料庫呢?應該如何進行最小宕機時間的資料庫轉移呢?如果規劃資料庫呢?
二、環境準備
要搭建一個好的系統,首先要從硬體和作業系統出發,好的設定和好的規劃是高效能的前提,下面我就來說說自己的一些看法,歡迎大家提出異議;
1)對磁碟做RAID0(比如3*300G),必要時可以考慮RAID5、RAID10;
2)使用兩張千兆網絡卡,一張用於外網,一張用於內網(這也需要千兆路由器的配合);
3)
4)安裝Microsoft Windows Server 2003, Enterprise Edition SP2(x64)作業系統;
5)D盤格式化的時候使用預設分配單元大小,E盤格式為64k分配單元;
6)安裝Microsoft SQL Server 2005(x64)資料庫;
7)在我們網路上的芳鄰-本地連線-屬性-Microsoft網路的檔案和印表機共享-最大化網路應用程式資料吞吐量(勾選上);
8)執行-gpedit.msc-Windows設定-安全設定-本地策略-使用者許可權分配-記憶體中鎖定頁面-設定使用者組(比如Administrators);
9)執行-services.msc,設定啟動型別為手動,並且停止除了SQL Server (MSSQLSERVER)之外的SQL Server服務,除非你對某些服務需要啟動,比如作業、全文索引;
10)設定虛擬記憶體大小,我通常設定為4096MB-8192MB;
三、前期工作
在進行分割槽之前,我們首先要分析這個表的資料量(行數)有多少?這個表的儲存空間(物理儲存)有多少?需要確定分割槽檔案多大為合理?還需要確認我們按照表中哪個欄位進行分割槽?後期的維護是否需要對分割槽進行管理(比如交換分割槽進行資料歸檔等)?
假設我們決定以自增ID作為分割槽欄位(其實應該叫分割槽數值型別),我們就可以使用上面的行數和儲存空間來計算我們的分割槽邊界值了,因為我們確認了分割槽檔案的大小。比如我們表A記錄為:1.5億,佔用空間為:700G,如果我們可以接受的檔案大小為10G(這個要根據如果需要做交換分割槽和一些儲存空間、硬碟等資訊確認的),那麼我們的分割槽值可以這樣計算:1.5億/(700G/10G)≈200W,也就是:200W,400W,600W等等;
分割槽檔案在建立的時候就應該初始化為包含分割槽邊界值資料大小,比如上面的分割槽檔案可以設定為10G,這樣就不用重新分配空間了。也可以使用定量增長,比如2048MB。
在設定自增ID為分割槽欄位,那麼通常我們會讓ID成為聚集索引,而且設定填充因子為100%,這樣我們的資料頁就不會有空白了。
如果後期的維護需要對分割槽進行管理,比如交換分割槽進行資料歸檔,交換分割槽是需要索引對齊的,而索引對齊有兩種:索引對齊;按儲存位置對齊的表。
索引對齊:假如你想讓資料與索引分開到不同的檔案,可以使用兩個不同的分割槽方案,但是使用同一個分割槽函式,這樣就把索引分開了。(如圖1)
儲存位置對齊:建立非聚集索引的時候設定【資料空間規範】,兩個索引物件可以使用相同的分割槽架構,並且具有相同分割槽鍵的所有資料行最後將位於同一個檔案組中。這就叫儲存位置對齊。(資料和索引在同一個檔案中)(如圖2)

(圖1)
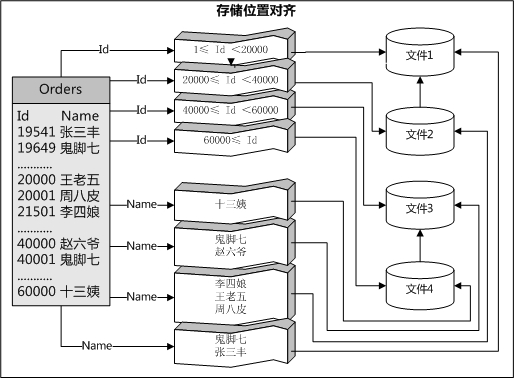
(圖2)
四、分割槽步驟
下面提供了建立分割槽的程式碼,其中包括模板還有例子(Ext),這裡最主要是注意一些命名規範,希望對大家有用:
步驟1:為MyDataBase資料庫建立2個檔案組,如果你不想用PRIMARY作為分割槽,你可以建立多一個檔案組,檔案組=分割槽值個數+1;
--1.建立檔案組 ALTER DATABASE [資料庫名] ADD FILEGROUP [FG_表名_欄位名_分割槽編號] --Ext ALTER DATABASE [MyDataBase] ADD FILEGROUP [FG_User_Id_1] ALTER DATABASE [MyDataBase] ADD FILEGROUP [FG_User_Id_2]
步驟2:為MyDataBase資料庫建立2個檔案,檔案數>=檔案組數,一個檔案不能屬於兩個不同的分組中,一個分組可以包含多個檔案,注意初始化大小(根據需求)和增長大小(百分比和位元組數);
--2.建立檔案方式一 ALTER DATABASE [資料庫名] ADD FILE (NAME = N'FG_表名_欄位名_分割槽編號_data',FILENAME = N'E:\DataBase\FG_表名_欄位名_分割槽編號_data.ndf',SIZE = 30MB, FILEGROWTH = 10% ) TO FILEGROUP [FG_表名_欄位名_分割槽編號]; --2.建立檔案方式二 ALTER DATABASE [資料庫名] ADD FILE (NAME = N'FG_表名_欄位名_分割槽編號_data',FILENAME = N'E:\DataBase\FG_表名_欄位名_分割槽編號_data.ndf',SIZE = 30720KB , FILEGROWTH = 10240KB ) TO FILEGROUP [FG_表名_欄位名_分割槽編號];
--Ext ALTER DATABASE [MyDataBase] ADD FILE (NAME = N'FG_User_Id_1_data',FILENAME = N'E:\DataBase\FG_User_Id_1_data.ndf',SIZE = 30MB, FILEGROWTH = 10% ) TO FILEGROUP [FG_User_Id_1]; ALTER DATABASE [MyDataBase] ADD FILE (NAME = N'FG_User_Id_2_data',FILENAME = N'E:\DataBase\FG_User_Id_2_data.ndf',SIZE = 30MB , FILEGROWTH = 10MB ) TO FILEGROUP [FG_User_Id_2];
步驟3:為MyDataBase資料庫建立分割槽函式,分割槽值需要根據需求而變化,前面已經做了示範了,這裡使用了右分割槽,關於邊界值的理解可以參考:;
--3.建立分割槽函式 CREATE PARTITION FUNCTION Fun_表名_欄位名(資料型別) AS RANGE RIGHT FOR VALUES(邊界值列表) --Ext CREATE PARTITION FUNCTION Fun_User_Id(INT) AS RANGE RIGHT FOR VALUES(100000000,200000000)
步驟4:為MyDataBase資料庫建立分割槽方案,因為前面只建立了2個檔案組,所以這裡使用了PRIMARY預設的檔案組來儲存邊界值之外的資料,如果你想建立多一個檔案組也可以,如下面的Ext1與Ext2;
--4.建立分割槽方案 CREATE PARTITION SCHEME Sch_表名_欄位名AS PARTITION Fun_表名_欄位名 TO(檔案組列表) --Ext1 CREATE PARTITION SCHEME Sch_User_Id AS PARTITION Fun_User_Id TO([FG_User_Id_1],[FG_User_Id_2],[FG_User_Id_3]) --Ext2 CREATE PARTITION SCHEME Sch_User_Id AS PARTITION Fun_User_Id TO([FG_User_Id_1],[FG_User_Id_2],[PRIMARY])
步驟5:為MyDataBase資料庫建立一個名為User的表,這個表有3個欄位,Id是自增標識,並在Id欄位中建立聚集索引,填充因子為100%,使用上面建立的Sch_User_Id分割槽方案,建立有不同的建立方式,如Ext1、Ext2、Ext3;
--5.建立表 --Ext1 CREATE TABLE [dbo].[User]( [Id] [int] IDENTITY(1,1) NOT NULL, [UserName] [nvarchar](256) COLLATE Chinese_PRC_CI_AS NULL, [Age] [int] NULL CONSTRAINT [DF_User_Age] DEFAULT ((0)), CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH( PAD_INDEX = ON, FILLFACTOR = 100, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id](Id) ) ON [Sch_User_Id]([Id]) --Ext2 CREATE TABLE [dbo].[User]( [Id] [int] IDENTITY(1,1) NOT NULL, [UserName] [nvarchar](256) COLLATE Chinese_PRC_CI_AS NULL, [Age] [int] NULL CONSTRAINT [DF_User_Age] DEFAULT ((0)), ) ON [Sch_User_Id]([Id]) GO CREATE CLUSTERED INDEX [IX_User_Id] ON dbo.[User] ( [Id] ) WITH( PAD_INDEX = ON, FILLFACTOR = 100, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id](Id) GO --Ext3 ALTER TABLE dbo.[User] ADD CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED ( Id ) WITH( PAD_INDEX = ON, FILLFACTOR = 100, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id](Id) GO
步驟6:為User表建立測試資料,這裡我就模擬從一個存在的OldUser表中匯入資料到分割槽User表,這裡需要注意SET IDENTITY_INSERT 表ON 這個選項;
--6.匯入資料 SET IDENTITY_INSERT 表ON INSERT INTO dbo.表 ( [Id] ,[UserName] ,[Age]) SELECT [Id] ,[UserName] ,[Age] FROM dbo.[OldUser](nolock) WHERE 條件 SET IDENTITY_INSERT 表OFF --Ext SET IDENTITY_INSERT [User] ON INSERT INTO dbo.[User] ( [Id] ,[UserName] ,[Age]) SELECT [Id] ,[UserName] ,[Age] FROM dbo.[OldUser](nolock) WHERE Id <= 1 and Id > 100000000 SET IDENTITY_INSERT [User] OFF
步驟7:當需要查詢分割槽User表記錄所處的分割槽情況時,可以使用下面的SQL;
--7.分割槽函式的記錄數 SELECT $PARTITION.分割槽函式(欄位) AS Partition_num, MIN(Id) AS Min_value,MAX(Id) AS Max_value,COUNT(1) AS Record_num FROM dbo.[User] GROUP BY $PARTITION.分割槽函式(欄位) ORDER BY $PARTITION.分割槽函式(欄位); --Ext SELECT $PARTITION.Fun_User_Id(Id) AS Partition_num, MIN(Id) AS Min_value,MAX(Id) AS Max_value,COUNT(1) AS Record_num FROM dbo.[User] GROUP BY $PARTITION.Fun_User_Id(Id) ORDER BY $PARTITION.Fun_User_Id(Id);
步驟8:其實到這裡例項應該結束了吧?在網上看到的所有關於分割槽的文章中貌似都是在這裡結束了,但是還有一點我需要指出:如果建立儲存位置對齊的索引呢?也許通過上面的圖2你已經瞭解了什麼是儲存位置對齊,如果還不清楚可以檢視:,其實很簡單,如Ext所示,但是主要是理解它的原理和作用;
--8.建立非聚集索引 CREATE NONCLUSTERED INDEX IX_表_欄位ON dbo.表 ( 欄位 ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id]([Id]) GO --Ext CREATE NONCLUSTERED INDEX IX_User_UserName ON dbo.[User] ( UserName ) WITH( PAD_INDEX = ON, FILLFACTOR = 80, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id]([Id]) GO
步驟9:還不想結束?呵呵,這個包含性索引的建立就當是買8送1吧;
--9.建立包含性索引 CREATE NONCLUSTERED INDEX [IX_User_UA_Include] ON dbo.[User] ( UserName, Age ) INCLUDE ([Id]) WITH( PAD_INDEX = ON, FILLFACTOR = 80, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id]([Id]) GO
五、注意
上面的程式碼中我們把檔案與檔案組是一 一對應起來的,如果我們想更小話檔案的話,我們可以在檔案組下面建立多個檔案,並且設定檔案的最大值(MAXSIZE),這樣就會把資料分配到不同的物理檔案上,但是有一點需要注意,那就是它是一個個的使用檔案的,當一個用完了才會使用下一個的。
日誌檔案也可以像上面的做法來做,這樣收縮日誌的時候比較方便?刪除日誌檔案比較方便?
有一點我們可能會混淆,那就是既然可以在一個檔案組裡面建立多個檔案,那麼這個跟我們按照Id的自增來分佈資料是不是等效的?這是有不同的,因為從建立分割槽方案的時候我們就發現檔案組和分割槽邊界值是對應的,所以一段分割槽值這些資料是分配到以檔案組為單位的儲存單元中,並不是檔案。
補充一下,那就是在檔案組下面建立的檔案只能按照設定的最大值(MAXSIZE)來區分資料,並不能按照值來區分,這也算一個不同點吧。
六、後記
如果這些表是寫的多,讀的少:類似記錄日誌,我們還有一些方案可以進行處理,比如SQL Server 2008的行壓縮、頁壓縮等;比如MySQL的IASM資料引擎;或者是使用MySQL的master/slave負載均衡。
七、參考文獻