
Kubernetes 中基於策略的資源分配_Kubernetes中文社群
本文是才雲科技(CaiCloud)5月6日沙龍“Kubernetes Meetup 中國 2017”IBM中國系統部軟體架構師馬達的演講實錄。PPT下載

IBM中國系統部軟體架構師馬達
大家好,很高興能參加這次活動,今天主要會講到關於策略的資源排程,做自己的產品也好,基本都是由資源排程為強項,我現在主要負責 Kubernetes 這邊,主要做 Batch Job Admission and flexible resource allocation。最近也是在跟 Google 的人去聊如何基於策略去排程。我2005年開始做技術,這個題目大概就是這個,關於這個 Kuberentes#269,如果感興趣,大家可以去上面看一看,還有這個 @k82cn,可以點進去看一下。

為什麼我們要去做這樣的事情?現在 Kubernetes,大家去部署所有的東西,感覺蠻不錯的。我們為什麼還要去聊這件事,這個最早的時候是很早的一個理念,我們當時大概分了幾個步驟,mesos 有自己的排程,最主要是資源的管理和資源的分配,然後我們上層由 Kubernetes 去管理,然後是 spark,這兩個是有專門的專案去做,現在的 spark 是 Kubernetes 的一個模式,然後我們自己去做了一個叫 session scheduler 的事情。Google 有一個人也在做,他們的想法,現在 spark 也是有一定的資源管理能力。
包括我們在做這個事情的時候也在想,這個系統是不是可以把 mesos 的功能放在 spark 裡面去做。他裡面自己搞的一個策略分配,這個圖在哪裡提供,在 Kubernetes 提供。我們有一個網站,這是我們內部的一個產品,所以這個說的比較少。當時這個想法在社群裡面跟他們聊了一下,他們比較感興趣,做了一些 PPT 聊了一下,這個專案在去年11月份開始到現在落地,大家可以去看一下。這個 PPT 也是基於以前的,加了一些內容。
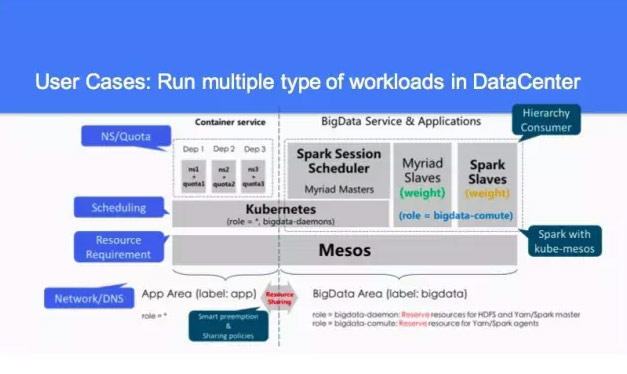
這個是主要做的幾件事情,Run multiple type of workloads in DataCenter 我們希望在資料中心裡面,好的東西是多種多樣的。然後我們也希望有其他的一些服務,對資源劃分的話,資源現在看沒有動態的劃分,我們按照組織來分機器,有一些是研發,大家在分機器的時候,應該是這個組織有多少機器,大家有相應的預算去買機器,但是每個公司對機器的使用率程度不一樣。有的部門機器蠻緊張的,有時候跟專案執行時間、跟整體的休假時間、跟產品上線的時間都是有關係的。
之前跟很多網際網路公司聊都有這樣的情況,公司想把所有的機器以資源調配的方式把它管理起來,所以有很多用這個。整個需求無論對傳統的企業,像銀行、電信,這個需求都是在這兒的。通過社群的人會有這樣的想法,我們會做這樣的事情。
當時忽略了幾個意見,現在 Kubernetes 有解決使用者的問題,第一個 Quota 就是部門上限能用多少,如果你想用的話,資源在哪兒,如果其他的 Quota,這個部門機器不要錢可以搶佔,但是 Quota 是沒有的。你這個部門能做這麼多的機器,不要超過了這個。如果不用的時候,大家可以彼此共享的。

還提到說 multiple scheduler,如果資源不夠的話,會造成很多的衝突。然後另外還提到 auto sualing,這個做完了以後,沒有一個全面的排程。這兩個是提的一個主要的功能,他有一個 rescheduling,當你整個執行一段時間之後,之前做的決定是最優的,有些機器可能最造成一些碎片,但是沒辦法,所以 Rescheduling 在過一段時間之後從全域性再看一遍,調節一個更優的。所以這個事情只有在 Rescheduling 才有存在的意義。
對於這種短作業一般跑幾分鐘就完事了,這個也是社群裡面來做的事情。然後 Work Specific,這個做的事情就是刪除,再重新來做。在整個體系下,把這兩個都考慮進去了,所以現在儘量不再去新增新的頂級的預設支援。另外就是 Controlller,就是定義什麼行為就做什麼行為,他基於原資料來做的。通過修改這些原資料的狀態來驅動其他協作,從整體架構是不太一樣的。你自己去排程修改你的原資料值就可以了。

這個大概是分了幾個步驟,我們會以一個 Batchjob Controller ,我們把資源排程和現有的功能分開,對資源排程這一塊現在有一個問題,資源排程的分配是經過完全驗證的,這個是100%沒有問題的。另外一個問題我不知道大家有沒有看過 borg 的事情,完全是基於這個來做的。
所以當時我們在做這個的時候,商量了一下還是將他們分開了,基於策略的搶佔還是做 borg 的路線。然後把之前說的基於資源排程的策略展示放在 batchjob controller 上面,至於後面是不是兩個合在一起,這個要到後面去談。現在兩邊都有不同的事情,兩種方式都是有案例做這樣的事情。很難說孰優孰劣,還是兩個都去做。
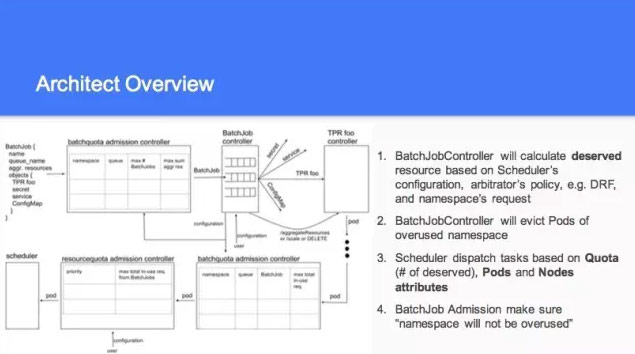
說到整個的話,根據策略去算這個 Quota 裡面應該分佈多少資源,這一塊有很多還是在討論的地方。關於 Quota 這一塊有很多的爭論,從功能上都是做一件事情,基本都支援層級的。

所以我們討論的時候,這一塊有兩個觀念,一個想建立一個概念,也叫 Quota,但是現在還沒有層級的,這個到後續再做。所以 Batchjob Controller 還得根據當前的來分配。如果我有100個資源,那剩下的80就分給另外的資源裡面進行調取。所以搶佔回來的時候,這裡面的每一個點都是有策略的。比如你先搶佔什麼的,跑的時間最長的,剛開始跑的,沒幹什麼事。這一塊大概列了一下。一個是算他的數值,第二個是20和80,平分是一人50,所以我往回搶的時候,你只能把30個搶回來。另外這一塊整個現在做的這個事情,只涉及到資源分配,這塊基本算的一個數,你這一個用多少資源,具體你放在那個裡面對你是最好的。其實這個現在只是一個初步的想法。
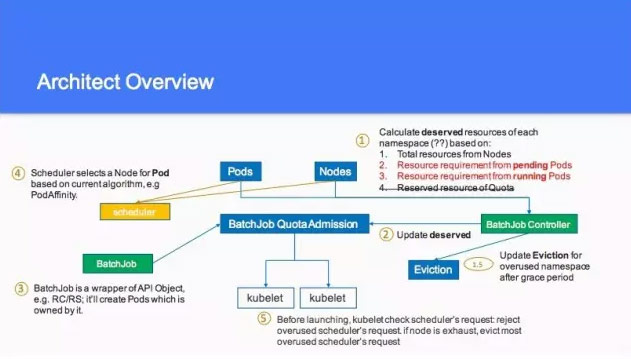
這個是剛才說的這個事情,又提到之前說的 Quota,你一定不會超過這個,另外想把 Deserved 加進去,比如有一些特定的硬體,最後大家去聊的時候,還是希望這個暫時不要考慮,只考慮這個 Deserved,這個是 Architect Overview 的一個值,如果這個 pods 到 nodes,這一塊大家要不要把這個換成另外一個。基於 reserved 大家不太想做,這個也劃掉了。所無我有的這些資訊到 Batchjob Controller 的時候都可以算出來。所以在第二個的時候,把他歸到 deserved 裡面。
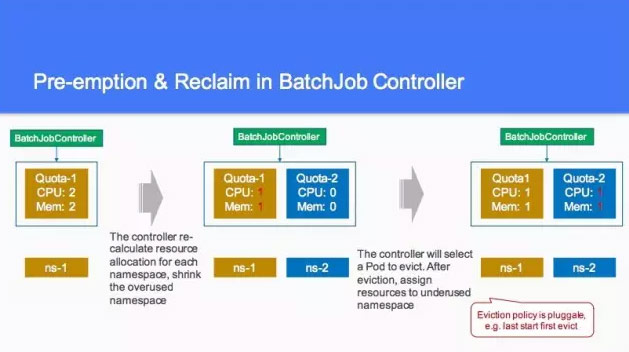
另外有1.5的值,由於作業的數量是有浮動的,所以一定會去做 eviction,就是把當前的用多的資源殺掉,然後用別的搶回來。然後第三步的時候,我們可以看到有資源可以去用,這個叫 Batchjob Controller,包含任何的東西,包含多個東西。這塊現在好像支援率也不是特別好,然後像剛才說的到第四步的時候,就是 scheduler。
這個是剛才所說的一個事情,重新算這個 Batchjob Controller 的一個值,就可以達到兩個 CPU 和 2個mem,在另外一個裡面,上了一些作業的時候,我們要重新計算這個值,然後大家平分,大家以人一個 CPU 和 mem,這個就已經有策略了。
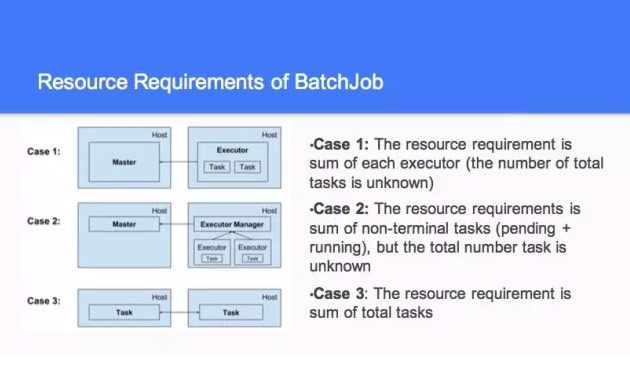
然後在做這個策略也好,我們之前做了一個資源的策略。第二種是你的這個根據當前的請求來進行調節的,然後我們有一個產品就跑一個。面對這一塊的時候,當你跑的作業不一樣的時候,我們做了第二種情況,你有了 case1,還有 case2,這裡跑比較慢,這兒結束了,這兒又開始了。
這是比較複雜的事情,你這個是動態的,你不知道到底有多少的資源,這個跟下面有關聯,有的說我拿最小的值去動態劃分,那個也不需要拿最小的值去做。這個要去算他的值到底是多少,那個值是不斷變的。
第三種的時候,它要求所有的資源都滿足了以後,才能跑起來。彼此之間有等待了,你只要殺了一個,就整個都跑不了了。說白了,你的整個的 task 和 host 之間是有關聯的。我要有兩個 CPU,我能保證自己的 mem,這塊是不同的方式和不同的結構,我們最後看資源到底一樣不一樣。另外我有個小的需求,能滿足這個最小的需求。然後是整個的到底有多少資源,這一塊還有一個事情,你像 case1 和 case2 你不知道到底什麼時候結束,但是 case3 你就知道什麼時候結束。

所以這些的資料方式和 case 都要考慮,會提供統一的來做這個事情,可以靈活做自己定製的。講了這麼多 case,但也不見得可以。這個是後面的 backlog,這個放在比較靠後。這個有需要考慮的事情,現在 backlog 只考慮你的 resource。另外 deserved 的值,主要是要做基層的時候要做,所以這些後面才會去考慮。

然後這個是 Reference,基於資源排程把他都放在一起了,這個會考慮整個空間的資源共享的一個情況,將來在1.7的版本看做什麼樣的資源共享,這個還在看。有一些細節還在討論,這裡面是一些相關的東西,第一個就是根據第一張圖,然後這個是 borg 的那個事情,下面是剛才說的 rescheduler,這個是另外的一個人在做。暫時就是這些,謝謝大家!