
K8S系列】Kubernetes排程核心解密:從Google Borg說起_Kubernetes中文社群
在之前“容器生態圈腦圖大放送”文章中我們根據容器生態圈腦圖,從下至上從左至右,依次介紹了容器生態圈中8個元件,其中也提到Kubernetes ,是一個以 Google Borg 為原型的開源專案。可實現大規模、分散式、高可用的容器叢集。本篇我們重點介紹Kubernetes前世今生。
一個容器平臺的主要功能就是為容器分配執行時所需要的計算,儲存和網路資源。容器排程系統負責選擇在最合適的主機上啟動容器,並且將它們關聯起來。它必須能夠自動的處理容器故障並且能夠在更多的主機上自動啟動更多的容器來應對更多的應用訪問。
目前三大主流的容器平臺Swarm, Mesos和Kubernetes具有不同的容器排程系統。Swarm的特點是直接排程Docker容器,並且提供和標準Docker API一致的API。 Mesos針對不同的執行框架採用相對獨立的排程系統,其中Marathon框架提供了Docker容器的原生支援。Kubernetes則採用了Pod和Label這樣的概念把容器組合成一個個的互相存在依賴關係的邏輯單元。相關容器被組合成Pod後被共同部署和排程,形成服務(Service)。這個是Kubernetes和Swarm,Mesos的主要區別。相對來說,Kubernetes採用這樣的方式簡化了叢集範圍內相關容器被共同排程管理的複雜性。換一種角度來看,Kubernetes採用這種方式能夠相對容易的支援更強大,更復雜的容器排程演算法。
談到Kubernetes, 我們就不能不提到Google的Borg系統。Google的Borg系統群集管理器負責管理幾十萬個以上的jobs,來自幾千個不同的應用,跨多個叢集,每個叢集有上萬個機器。它通過管理控制、高效的任務包裝、超售、和程序級別效能隔離實現了高利用率。它支援高可用性應用程式與執行時功能,最大限度地減少故障恢復時間,減少相關故障概率的排程策略。Kubernetes的架構設計基本上是參照了Google Borg。本文結合Google釋出的相關論文和視訊,初步介紹了Google Borg的資源排程,以及它對Kubernetes容器排程系統產生的影響和未來走向。關於本文內容的具體技術細節描述請參見Google論文以及Kubernetes文件。
Borg排程介紹
本文的第一部分我們先介紹一下看看Borg. Google的Borg系統執行幾十萬個以上的任務,來自幾千個不同的應用,跨多個叢集,每個叢集(cell)有上萬個機器。它通過管理控制、高效的任務包裝、超售、和程序級別效能隔離實現了高利用率。它支援高可用性應用程式與執行時功能,最大限度地減少故障恢復時間,減少相關故障概率的排程策略。以下就是Borg的系統架構圖。其中Scheduler負責任務的排程。
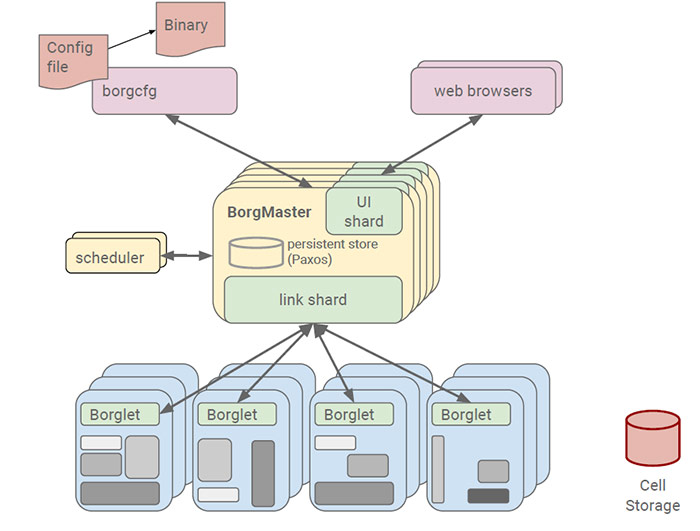
Borg排程測試
Borg對開發者隱藏了系統資源管理和故障處理細節,我們來從開發者的角度來看如何在Borg中執行一萬個Hello World的任務。開發者只需要完成以下config file並且提交給Borg.
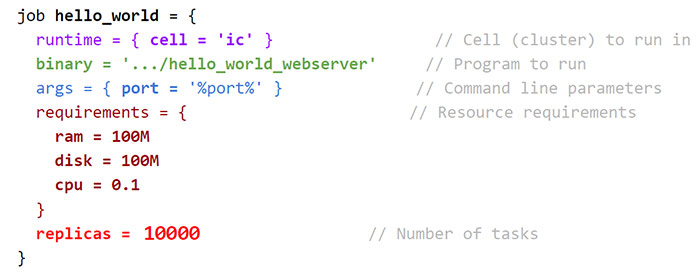
大家可以看到這樣的一個config file包含了叢集名稱,任務二進位制, 資源要求以及replica數量。Kubernetes的YAML檔案很大程度上繼承了這些配置項。
當我們提交這樣一個Hello World 任務給Borg後,排程器Scheduler會根據系統資源自動部署一萬個Hello World任務到主機上。下圖是一個部署時間表。
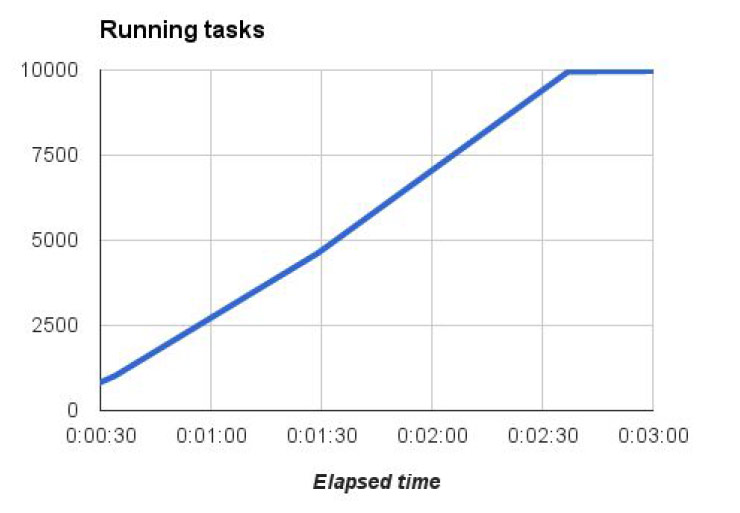
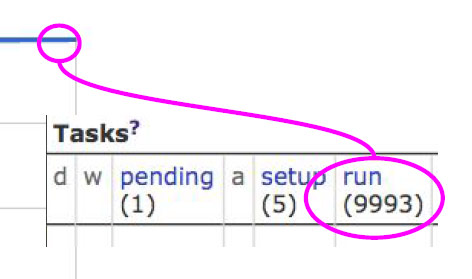
可以看到經過了3分鐘後大約一萬個任務就開始運行了。原因在於其中會有一些任務因為各種各樣的原因停止執行。下圖可以看到3分鐘後大概只有9993個任務在執行。Borg會自動進行錯誤處理並且部署新的任務。
Borg排程核心
那麼如何提升整個Borg系統的資源利用率呢?核心的解決方案就是根據主機資源合理的排程任務,提高系統效率。Borg主要從以下幾個方面著手。
在同一臺主機上跑多個任務。
- 採用最優的打包演算法,合理的把成比例的CPU、Memory資源分配給任務,避免資源阻塞造成浪費。下圖橙色標識的主機就是因為CPU或者記憶體資源佔用超過合理比例而造成另外一種資源的浪費。
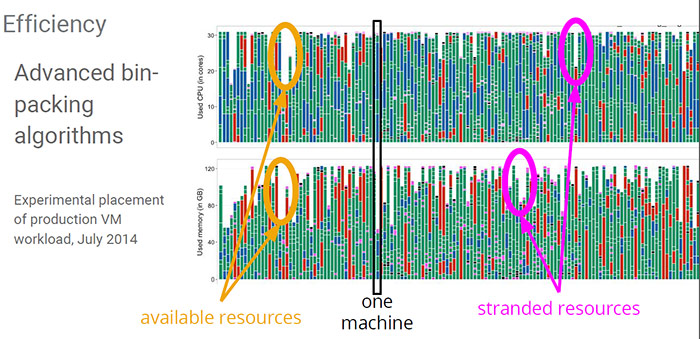
- 在系統中同時跑生成和非生產任務。Borg系統的任務分為生產型(Prod)任務,即高優先順序任務和非生產的(non-prod)任務。大多數長期服務是Prod的,大部分批處理任務是non-prod的。通常情況下,生產型任務會保留一部分資源以應付極端情況,這些資源可以被用來跑非生產型應用,當生產型任務需要更多資源的時候,非生產型任務會被排程出系統。
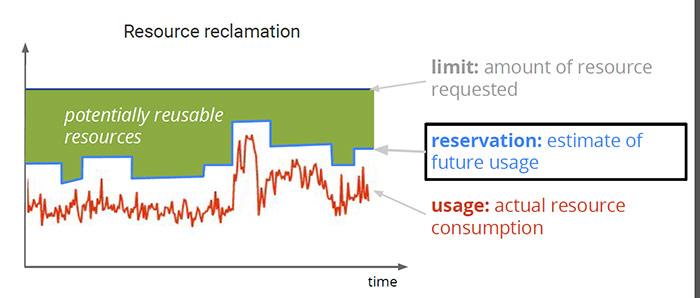
- 資源回收。從下圖可以看到,Borg會根據現有資源消耗情況評估任務對未來資源的需求作為Reservation, 把綠色部分的資源回收再利用給那些可以忍受低質量資源的工作。Borg排程器使用限制資源(limit)來計算Prod任務的可用性,這些Prod任務從來不依賴於回收的資源,也不提供超售的資源;對於non-Prod的任務則使用了目前執行任務的Reservation,新的任務也可以被排程到回收資源上去。當一臺主機因為對資源預估不足時,Borg會限制或者殺掉non-prod任務。資源預估可以採用激進或者保守的策略,Borg目前採用的介於兩者之間的中庸策略。
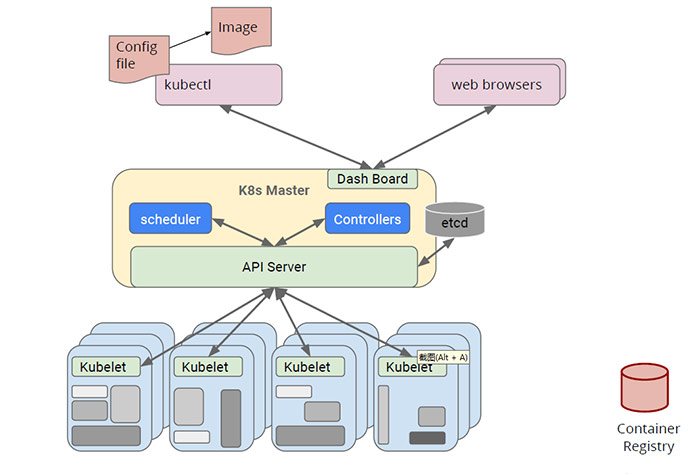
Kubernetes借鑑了Borg的整體架構思想。如下圖,其中Pod排程也是由Scheduler元件完成的。
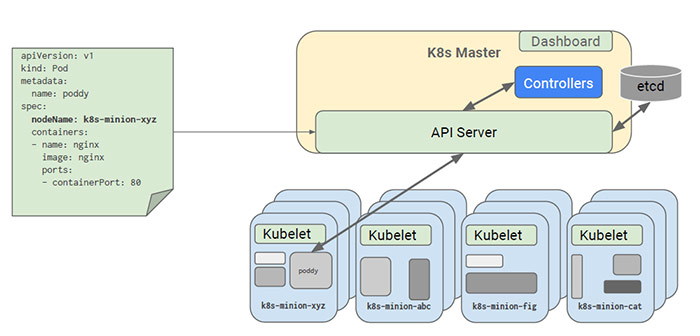
有一種情況下,Scheduler不參與Pod排程,那就是用NodeName指定部署主機。
Kubernetes資源排程
和Borg類似,Kubernetes的資源分為兩種屬性。可壓縮資源(例如CPU迴圈,Disk I/O頻寬)都是可以被限制和被回收的,對於一個Pod來說可以降低這些資源的使用量而不去殺掉Pod。不可壓縮資源(例如記憶體、硬碟空間)一般來說不殺掉Pod就沒法回收。未來Kubernetes會加入更多資源,如網路頻寬,儲存IOPS的支援。
Kubernetes排程器使用Predicates和Priorites來決定一個Pod應該執行在哪一個節點上。Predicates是強制性規則,用來形容主機匹配Pod所需要的資源,如果沒有任何主機滿足該Predicates, 則該Pod會被掛起,直到有主機能夠滿足。可用的Predicates如下:
- PodFitPorts:沒有任何埠衝突
- PodFitsResurce:有足夠的資源執行Pod
- NoDiskConflict:有足夠的空間來滿足Pod和連結的資料卷
- MatchNodeSelector:能夠匹配Pod中的選擇器查詢引數。
- HostName:能夠匹配Pod中的Host引數
如果排程器發現有多個主機滿足條件,那麼Priorities就用來判斷哪一個主機最適合執行Pod。Priorities是一個鍵值對,key表示名稱,value表示權重。可用的Priorities如下:
- LeastRequestdPriority:計算Pods需要的CPU和記憶體在當前節點可用資源的百分比,具有最小百分比的節點就是最優的。
- BalanceResourceAllocation:擁有類似記憶體和CPU使用的節點。
- ServicesSpreadingPriority:優先選擇擁有不同Pods的節點。
- EqualPriority:給所有叢集的節點同樣的優先順序,僅僅是為了做測試。
Kubernetes排程總結
為了對Pod所執行時要求的資源做出限制,Kubernetes通過配額YAML檔案來設定Resource quotas和limit,從而管理獨立Pod以及專案中所有Pod(即Namespace)的資源要求。未來Kubernetes會針對Pod資源QoS做出更多功能增強,以應對日益複雜的容器應用需求。
我們可以看到基於資源分配的任務排程是Borg和Kubernetes的核心元件。兩者的排程模組都處於整個系統的核心位置。Kubernetes的排程策略源自Borg, 但是為了更好的適應新一代的容器應用,以及各種規模的部署,Kubernetes的排程策略相應做的更加靈活,也更加容易理解和使用。