
hadoop 序列化原始碼淺析 (轉)
1.Writable介面
Hadoop 並沒有使用 JAVA 的序列化,而是引入了自己實的序列化系統, package org.apache.hadoop.io 這個包中定義了大量的可序列化物件,這些物件都實現了 Writable 介面, Writable 介面是序列化物件的一個通用介面.我們來看下Writable 介面的定義。
public interface Writable{
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
} Writable
2.WriteCompareable介面
WriteCompareable介面是Wirtable介面的二次封裝,提供了compareTo(T o)方法,用於序列化物件的比較的比較。因為mapreduce中間有個基於key的排序階段。
public interface WritableComparable<T> extends Writable, Comparable<T> {
}下面是io包簡單的類圖關係。
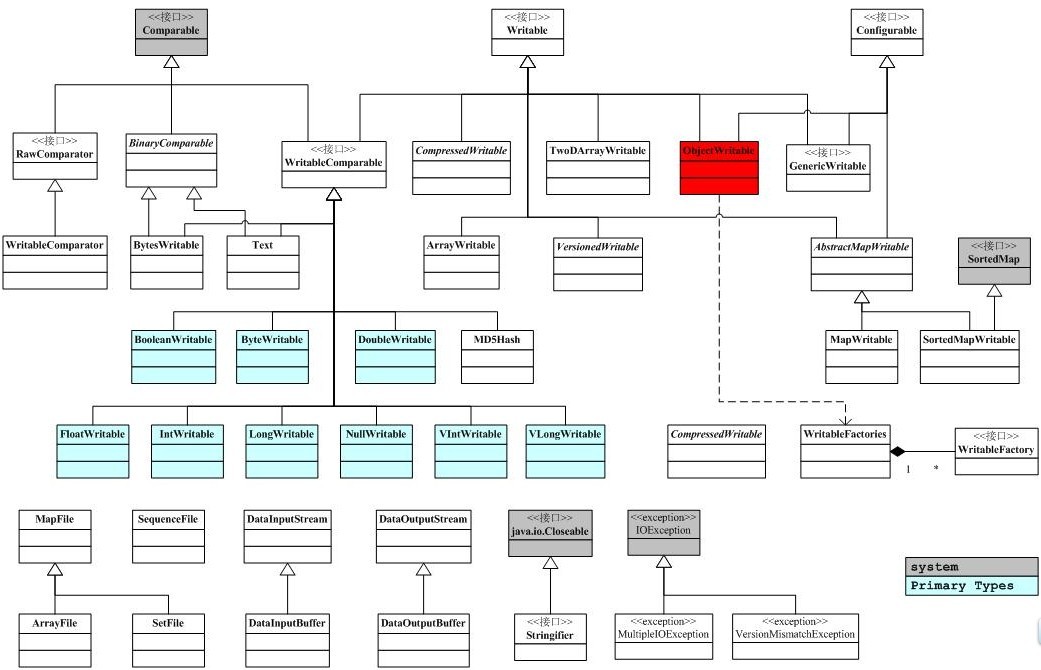
3.RawComparator介面
hadoop為序列化提供了優化,型別的比較對M/R而言至關重要,Key和Key的比較也是在排序階段完成的,hadoop提供了原生的比較器介面RawComparator<T>用於序列化位元組間的比較,該介面允許其實現直接比較資料流中的記錄,無需反序列化為物件,RawComparator是一個原生的優化介面類,它只是簡單的提供了用於資料流中簡單的資料對比方法,從而提供優化:
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte
} 該介面並非被多數的衍生類所實現,其直接的子類為WritableComparator,多數情況下是作為實現Writable介面的類的內建類,提供序列化位元組的比較。下面是RawComparator介面內建類的實現類圖:

首先,我們看 RawComparator的直接實現類WritableComparator:

WritableComparator類似於一個登錄檔,裡面通過靜態map記錄了所有Comparators成員用一張Hash表記錄Key=Class,value=WritableComprator的註冊資訊.
WritableComparator主要提供了兩個功能
1.提供了對原始compare()方法的一個預設實現
預設實現是先反序列化為對像再通過對像比較(有開銷的問題),所以一般都會被具體writeCompatable類的Comparator類覆蓋以加快效率。
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {
thrownew RuntimeException(e);
}
return compare(key1, key2); // compare them
}
2.充當RawComparable例項的工廠,以註冊Writable的實現
例如,為了獲取IntWritable的Comparator,可以直接呼叫其get方法。
接下來撿關鍵程式碼來分析writableComparator類,該類是RawComparator介面的直接子類。
程式碼1:registry 註冊器
// registry 註冊器:記載了WritableComparator類的集合
privatestaticcomparators = new HashMap<Class, WritableComparator>();
----------------------------------------------------------------程式碼2:獲取WritableComparator例項
說明:hashMap作為容器類執行緒不安全,故需要synchronized同步,get方法根據key=Class返回對應的WritableComparator,若返回的是空值NUll,則呼叫protected Constructor進行構造,而其兩個protected的建構函式實則是呼叫了newKey()方法進行NewInstance
publicstatic synchronized WritableComparator get(Class<? extends WritableComparable> c) {WritableComparator comparator = comparators.get(c);if (comparator ==null)
comparator =new WritableComparator(c, true);return comparator;
}
----------------------------------------------------------------
程式碼3:WritableComparator構造方法
new WritableComparator(c, true)
WritableComparator的建構函式原始碼如下:/*
* keyClass,key1,key2和buffer都是用於WritableComparator的建構函式
*/private final Class<? extends WritableComparable> keyClass;
private final WritableComparable key1; //WritableComparable介面private final WritableComparable key2;
private final DataInputBuffer buffer; //輸入緩衝流protected WritableComparator(Class<? extends WritableComparable> keyClass,boolean createInstances) {
this.keyClass = keyClass;if (createInstances) {
key1 = newKey();
key2 = newKey();
buffer =new DataInputBuffer();
} else {
key1 = key2 =null;
buffer =null;
}
}
上述的keyClass,key1,key2,buffer是記錄HashMap對應的key值,用於WritableComparator的建構函式,但由其建構函式中我們可以看出WritableComparator根據Boolean createInstance來判斷是否例項化key1,key2和buffer,而key1,key2是用於接收比較的兩個key。在WritableComparator的建構函式裡面通過newKey()的方法去例項化實現WritableComparable介面的一個物件,下面是newKey()的原始碼,通過hadoop自身的反射去例項化了一個WritableComparable介面物件。
public WritableComparable newKey() {return ReflectionUtils.newInstance(keyClass, null);
}
----------------------------------------------------------------
程式碼4:Compare()方法
(1).public int compare(Object a, Object b);
(2).public int compare(WritableComparable a, WritableComparable b);
(3).public intbyte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
三個compare()過載方法中,compare(Object a, Object b)利用子類塑形為WritableComparable而呼叫了第2個compare方法,而第2個Compare()方法則呼叫了Writable.compaerTo();最後一個compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)方法原始碼如下:publicint compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {thrownew RuntimeException(e);
}return compare(key1, key2); // compare them
}
Compare方法的一個預設實現方式,根據介面key1,ke2反序列化為物件再進行比較。
利用Buffer為橋接中介,把位元組陣列儲存為buffer後,呼叫key1(WritableComparable)的反序列化方法,再來比較key1,ke2,由此處可以看出,該compare方法是將要比較的二進位制流反序列化為物件,再呼叫方法第2個過載方法進行比較。
----------------------------------------------------------------程式碼5:方法define方法
該方法用於註冊WritebaleComparaor物件到登錄檔中,注意同時該方法也需要同步,程式碼如下:
public static synchronized void define(Class c, WritableComparator comparator) {comparators.put(c, comparator);
}
----------------------------------------------------------------
程式碼6:餘下諸如readInt的靜態方法
這些方法用於實現WritableComparable的各種例項,例如 IntWritable例項:內部類Comparator類需要根據自己的IntWritable型別過載WritableComparator裡面的compare()方法,可以說WritableComparator裡面的compare()方法只是提供了一個預設的實現,而真正的compare()方法實現需要根據自己的型別如IntWritable進行過載,所以WritableComparator方法中的那些readInt..等方法只是底層的封裝的一個實現,方便內部Comparator進行呼叫而已。
下面我們著重看下BooleanWritable類的內建RawCompartor<T>的實現過程:
public static class Comparator extends WritableComparator {public Comparator() {//呼叫父類的Constructor初始化keyClass=BooleanWrite.class
super(BooleanWritable.class);
}
//重寫父類的序列化比較方法,用些類用到父類提供的預設方法
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
boolean a = (readInt(b1, s1) == 1) ? true : false;
boolean b = (readInt(b2, s2) == 1) ? true : false;
return ((a == b) ? 0 : (a == false) ? -1 : 1);
}
}
//註冊
static {
WritableComparator.define(BooleanWritable.class, new Comparator());
}
總結:
hadoop 類似於Java的類包,即提供了Comparable介面(對應於writableComparable介面)和Comparator類(對應於RawComparator類)用於實現序列化的比較,在hadoop 的IO包中已經封裝了JAVA的基本資料型別用於序列化和反序列化,一般自己寫的類實現序列化和反序列化需要繼承WritableComparable介面並且內建一個Comparator(繼承於WritableComparator)的格式來實現自己的物件。
5.WritableFactory介面作為工廠模式的WritableFactory,其抽象為一個介面,提供了具體的Writable物件建立例項的抽象方法newInstance(),程式碼如下:
publicinterface WritableFactory {
/** Return a new instance. */Writable newInstance();
} WritableFactories類類似於WritableComparator類利用HashMap註冊記錄著所有實現上述介面的WritableFactory的集合,與之不同的是WritableFactories是一個單例模式,所有的方法都是靜態的。
關鍵程式碼:
//提供了一個key=class,value=WritableFactory的登錄檔
private static final HashMap<Class, WritableFactory> CLASS_TO_FACTORY = new HashMap<Class, WritableFactory>();
public static Writable newInstance(Class<? extends Writable> c, Configuration conf) {
WritableFactory factory = WritableFactories.getFactory(c);
if (factory != null) {
//該方法的newInstanceof是呼叫了factory.newInstance()即你了實現的WritableFactory的newInstance()方法
Writable result = factory.newInstance();
if (result instanceof Configurable) {
((Configurable) result).setConf(conf);
}
return result;
} else {
return ReflectionUtils.newInstance(c, conf);
}
}
6.InputBuffer和DataInputBuffer類
類似於JAVA.IO 的裝飾器模式, InputBuffer輸入緩衝和DataInputBuffer資料緩衝的實現封裝於內部類Buffer,該類的功能只是提供一個空的緩衝區,用於儲存資料。Buffer程式碼如下:
private static class Buffer extends ByteArrayInputStream {
public Buffer() {
super(new byte[] {});
}
public void reset(byte[] input, int start, int length) {
this.buf = input;
this.count = start+length;
this.mark = start;
this.pos = start;
}
public int getPosition() { return pos; }
public
相關推薦
hadoop 序列化原始碼淺析 (轉)
轉自:http://my.oschina.net/tuzibuluo/blog?catalog=1278261.Writable介面 Hadoop 並沒有使用 JAVA 的序列化,而是引入了自己實的序列化系統, package org.apache.hadoop.io 這個包中定義了大量的可序
大資料-Hadoop生態(12)-Hadoop序列化和原始碼追蹤
1.什麼是序列化
2.為什麼要序列化
3.為什麼不用Java的序列化
4.自定義bean物件實現序列化介面(Writable)
在企業開發中往往常用的基本序列化型別不能滿足所有需求,比如在Hadoop框架內部傳遞一個bean物件,那麼該物件就需要實現序列化介面。
具體實現bean物件序列
Hadoop Serialization -- hadoop序列化具體解釋 (2)【Text,BytesWritable,NullWritable】
tao small oid rem cef get() 每一個 包含 協同工作
回想:
回想序列化,事實上原書的結構非常清晰,我截圖給出書中的章節結構:
序列化最基本的,最底層的是實現writable接口,wiritable規定讀和寫的遊戲規則 (void
Hadoop序列化與Writable接口(一)
temp 們的 ffi err 時間 sea 部分 過程 自身 Hadoop序列化與Writable接口(一)
序列化
序列化(serialization)是指將結構化的對象轉化為字節流,以便在網絡上傳輸或者寫入到硬盤進行永久存儲;相對的反序列化(deserializat
Hadoop序列化-流量彙總案例
Hadoop序列化案例-流量彙總需求
作者:尹正傑
版權宣告:原創作品,謝絕轉載!否則將追究法律責任。
一.Hadoop序列
MapReduce常見演算法 與自定義排序及Hadoop序列化
MapReduce常見演算法 •單詞計數 •資料去重 •排序 •Top K •選擇 以求最值為例,從100萬資料中選出一行最小值 •投影 以求處理手機上網日誌為例,從其11個欄位選出了五個欄位(列)來顯示我們的手機上網流量 •分組 相當於分割槽,以求處理手機上網日誌為例,喊手機號和非手
自定義Hadoop序列化been Demo
package hadoop.mapreduce.serializable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import
學習Hadoop第十二課(Hadoop序列化機制、Linux安裝Eclipse及建立快捷圖示、使用Maven開發)
我看的視訊就是這個,看到有人寫了,就轉過來了
上節課我們一起學習了MapReduce的一個簡單例項,這節課我們一起來學習Hadoop的序列化機制。
首先我們來學習一下,什麼叫做序列化,序列化是指把結構化物件轉換成位元組流,這樣做的目的當然是便於在網路中傳輸。
表單序列化的資料轉成物件
$.fn.serializeObject = function()
{
var o = {};
var a = this.serializeArray();
$.each(a, function() {
if (o[this.name] !== undefin
Hadoop 7days -hadoop序列化機制及 使用maven開發 MR統計上下行流量的例子開發
MR執行流程:(1).客戶端提交一個mr的jar包給JobClient(提交方式:hadoop jar ...)(2).JobClient通過RPC和ResourceManager進行通訊,返回一個存放jar包的地址(HDFS)和jobId(3).client將jar包寫入到
Hadoop序列化案例
一、問題描述
根據所給的資料輸出每一個手機號上網的上載流量、下載流量和總流量。
二、資料格式
輸入資料(部分)格式
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.1
Hadoop Serialization -- hadoop序列化詳解 (2)【Text,BytesWritable,NullWritable】
回顧:
回顧序列化,其實原書的結構很清晰,我截圖給出書中的章節結構:
序列化最主要的,最底層的是實現writable介面,wiritable規定讀和寫的遊戲規則 (void write(DataOu
圖解Janusgraph系列-圖資料底層序列化原始碼分析(Data Serialize)
# 圖解Janusgraph系列-圖資料底層序列化原始碼分析(Data Serialize)
大家好,我是`洋仔`,JanusGraph圖解系列文章,`實時更新`~
#### 圖資料庫文章總目錄:
* **整理所有圖相關文章,請移步(超鏈):**[圖資料庫系列-文章總目錄 ](https://li
淺析SQL Server在可序列化隔離級別下,防止幻讀的範圍鎖的鎖定問題
tran .html 表格 des locks 構建 isolation 錯誤 ron
本文出處:http://www.cnblogs.com/wy123/p/7501261.html (保留出處並非什麽原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後
jackson實體轉json時 為NULL不參加序列化的匯總
ica writev ber src 配置 () 全局 rgb 使用 首先加入依賴<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gso
【轉】編寫高質量代碼改善C#程序的157個建議——建議54:為無用字段標註不可序列化
快捷鍵 語法 文件中 chan 有意 否則 [] strong 還原
建議54:為無用字段標註不可序列化
序列化是指這樣一種技術:把對象轉變成流。相反過程,我們稱為反序列化。在很多場合都需要用到這項技術。
把對象保存到本地,在下次運行程序的時候,恢復這個對象。
把對象
jquery的form序列化後轉json
return ray str query ring .html body inf blog //form序列化後 轉jsonfunction arrayToJson(formArray){ var dataArray = {}; $.each(formArray,fun
[轉]java-小技巧-001-Long序列化到前端不支持
方式 .cn ria https a long tostring span per pre 調試接口,發現java Long序列化有問題,百度解決方式如下:
1、引入:
jackson-mapper-asl-1.9.2.jar
2、導入:
import org.code
Django跳轉,緩存,信號,序列化
哈哈 前後端 跳轉 信號 ext 返回 path cookies 如果 跳轉問題
如果我現在停留在文章的詳情頁,用戶未登陸,如果你要評論,或者點贊就應該回到登陸頁面登陸
如果登陸成功了,就要返回到當初跳轉過來的頁面
第一種通過前後端傳送數據
$(‘.hit‘).click
Hadoop IO操作之序列化
數據 new 前言 一個 就是 clas 之間 其中 ava 前言:為什麽Hadoop基本類型還要定義序列化?
1、Hadoop在集群之間通信或者RPC調用時需要序列化,而且要求序列化要快,且體積要小,占用帶寬小。
2、java的序列化機制占用大量計算開銷,且序列化
hadoop 序列化原始碼淺析 (轉)
轉自:http://my.oschina.net/tuzibuluo/blog?catalog=1278261.Writable介面 Hadoop 並沒有使用 JAVA 的序列化,而是引入了自己實的序列化系統, package org.apache.hadoop.io 這個包中定義了大量的可序
大資料-Hadoop生態(12)-Hadoop序列化和原始碼追蹤
1.什麼是序列化 2.為什麼要序列化 3.為什麼不用Java的序列化 4.自定義bean物件實現序列化介面(Writable) 在企業開發中往往常用的基本序列化型別不能滿足所有需求,比如在Hadoop框架內部傳遞一個bean物件,那麼該物件就需要實現序列化介面。 具體實現bean物件序列
Hadoop Serialization -- hadoop序列化具體解釋 (2)【Text,BytesWritable,NullWritable】
tao small oid rem cef get() 每一個 包含 協同工作 回想: 回想序列化,事實上原書的結構非常清晰,我截圖給出書中的章節結構: 序列化最基本的,最底層的是實現writable接口,wiritable規定讀和寫的遊戲規則 (void
Hadoop序列化與Writable接口(一)
temp 們的 ffi err 時間 sea 部分 過程 自身 Hadoop序列化與Writable接口(一) 序列化 序列化(serialization)是指將結構化的對象轉化為字節流,以便在網絡上傳輸或者寫入到硬盤進行永久存儲;相對的反序列化(deserializat
Hadoop序列化-流量彙總案例
Hadoop序列化案例-流量彙總需求 作者:尹正傑 版權宣告:原創作品,謝絕轉載!否則將追究法律責任。 一.Hadoop序列
MapReduce常見演算法 與自定義排序及Hadoop序列化
MapReduce常見演算法 •單詞計數 •資料去重 •排序 •Top K •選擇 以求最值為例,從100萬資料中選出一行最小值 •投影 以求處理手機上網日誌為例,從其11個欄位選出了五個欄位(列)來顯示我們的手機上網流量 •分組 相當於分割槽,以求處理手機上網日誌為例,喊手機號和非手
自定義Hadoop序列化been Demo
package hadoop.mapreduce.serializable; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import
學習Hadoop第十二課(Hadoop序列化機制、Linux安裝Eclipse及建立快捷圖示、使用Maven開發)
我看的視訊就是這個,看到有人寫了,就轉過來了 上節課我們一起學習了MapReduce的一個簡單例項,這節課我們一起來學習Hadoop的序列化機制。 首先我們來學習一下,什麼叫做序列化,序列化是指把結構化物件轉換成位元組流,這樣做的目的當然是便於在網路中傳輸。
表單序列化的資料轉成物件
$.fn.serializeObject = function() { var o = {}; var a = this.serializeArray(); $.each(a, function() { if (o[this.name] !== undefin
Hadoop 7days -hadoop序列化機制及 使用maven開發 MR統計上下行流量的例子開發
MR執行流程:(1).客戶端提交一個mr的jar包給JobClient(提交方式:hadoop jar ...)(2).JobClient通過RPC和ResourceManager進行通訊,返回一個存放jar包的地址(HDFS)和jobId(3).client將jar包寫入到
Hadoop序列化案例
一、問題描述 根據所給的資料輸出每一個手機號上網的上載流量、下載流量和總流量。 二、資料格式 輸入資料(部分)格式 1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.1
Hadoop Serialization -- hadoop序列化詳解 (2)【Text,BytesWritable,NullWritable】
回顧: 回顧序列化,其實原書的結構很清晰,我截圖給出書中的章節結構: 序列化最主要的,最底層的是實現writable介面,wiritable規定讀和寫的遊戲規則 (void write(DataOu
圖解Janusgraph系列-圖資料底層序列化原始碼分析(Data Serialize)
# 圖解Janusgraph系列-圖資料底層序列化原始碼分析(Data Serialize) 大家好,我是`洋仔`,JanusGraph圖解系列文章,`實時更新`~ #### 圖資料庫文章總目錄: * **整理所有圖相關文章,請移步(超鏈):**[圖資料庫系列-文章總目錄 ](https://li
淺析SQL Server在可序列化隔離級別下,防止幻讀的範圍鎖的鎖定問題
tran .html 表格 des locks 構建 isolation 錯誤 ron 本文出處:http://www.cnblogs.com/wy123/p/7501261.html (保留出處並非什麽原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後
jackson實體轉json時 為NULL不參加序列化的匯總
ica writev ber src 配置 () 全局 rgb 使用 首先加入依賴<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gso
【轉】編寫高質量代碼改善C#程序的157個建議——建議54:為無用字段標註不可序列化
快捷鍵 語法 文件中 chan 有意 否則 [] strong 還原 建議54:為無用字段標註不可序列化 序列化是指這樣一種技術:把對象轉變成流。相反過程,我們稱為反序列化。在很多場合都需要用到這項技術。 把對象保存到本地,在下次運行程序的時候,恢復這個對象。 把對象
jquery的form序列化後轉json
return ray str query ring .html body inf blog //form序列化後 轉jsonfunction arrayToJson(formArray){ var dataArray = {}; $.each(formArray,fun
[轉]java-小技巧-001-Long序列化到前端不支持
方式 .cn ria https a long tostring span per pre 調試接口,發現java Long序列化有問題,百度解決方式如下: 1、引入: jackson-mapper-asl-1.9.2.jar 2、導入: import org.code
Django跳轉,緩存,信號,序列化
哈哈 前後端 跳轉 信號 ext 返回 path cookies 如果 跳轉問題 如果我現在停留在文章的詳情頁,用戶未登陸,如果你要評論,或者點贊就應該回到登陸頁面登陸 如果登陸成功了,就要返回到當初跳轉過來的頁面 第一種通過前後端傳送數據 $(‘.hit‘).click
Hadoop IO操作之序列化
數據 new 前言 一個 就是 clas 之間 其中 ava 前言:為什麽Hadoop基本類型還要定義序列化? 1、Hadoop在集群之間通信或者RPC調用時需要序列化,而且要求序列化要快,且體積要小,占用帶寬小。 2、java的序列化機制占用大量計算開銷,且序列化