
ABAP非Unicode系統中字串拼接(CONCATENATE)時吃字元問題
阿新 • • 發佈:2018-12-27
系統是老R3,非Unicdoe系統,某些表字段是從外界系統過來的,由於介面設計的固定長度,外界系統傳超長字串過來後,就可能從最後一箇中文字元中間截斷,這問題到還沒什麼,只不過顯示時最後一個字元顯示成亂碼而已,但是,如果將這些表字段撈出來與其它分隔符(如豎線) CONCATENATE時,可能會將這個分隔符吃掉,導致這些資料拋到對方系統後,無法再分隔,還原成一個個欄位
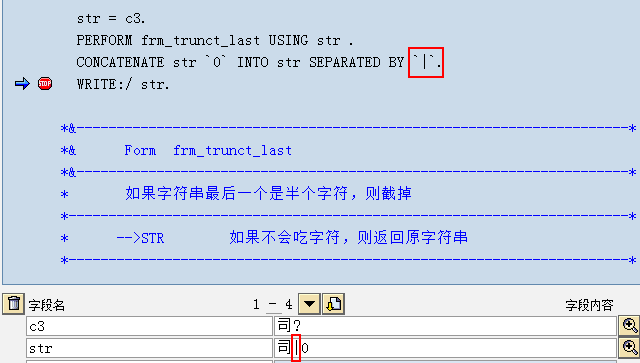
如下面執行過程中:c3本身是一個 司 字後面跟半個中文字元,當使用 豎線分隔符與0字元CONCATENATE後,發現豎線沒有了,它與前面的?問號(注:不是真正的問號,而是由於編碼B5在GBK字符集裡找不到,ABAP編輯器以問號顯示而已)合成

下面是經過frm_trunct_last 方法將半個中文字元截斷後,再CONCATENATE拼接時,分隔符豎線就不會被吃掉了:
 DATA: str TYPE string.DATA: x3(3) TYPE x.DATA: c3(3) TYPE c.FIELD-SYMBOLS:<c3> TYPE x.START-OF-SELECTION. ASSIGN c3 TO <c3> CASTING. "CBBE為“司”的編碼,B5為前半個漢字編碼,如“祙、單”等字的前半個就是B5 <c3> = 'CBBEB5'."模擬半個中文
DATA: str TYPE string.DATA: x3(3) TYPE x.DATA: c3(3) TYPE c.FIELD-SYMBOLS:<c3> TYPE x.START-OF-SELECTION. ASSIGN c3 TO <c3> CASTING. "CBBE為“司”的編碼,B5為前半個漢字編碼,如“祙、單”等字的前半個就是B5 <c3> = 'CBBEB5'."模擬半個中文注:分隔符是否被吃掉了,在螢幕輸出上是看不出來的,如下面是輸出結果:
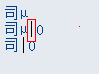 但從上面的除錯過程可以看出是被吃掉了,經測試傳到其他系統後,也是會被吃掉的
但從上面的除錯過程可以看出是被吃掉了,經測試傳到其他系統後,也是會被吃掉的