
決策樹系列(一)——基礎知識回顧與總結
決策樹系列(一)——基礎知識回顧與總結
1.決策樹的定義
樹想必大家都會比較熟悉,是由節點和邊兩種元素組成的結構。理解樹,就需要理解幾個關鍵詞:根節點、父節點、子節點和葉子節點。
父節點和子節點是相對的,說白了子節點由父節點根據某一規則分裂而來,然後子節點作為新的父親節點繼續分裂,直至不能分裂為止。而根節點是沒有父節點的節點,即初始分裂節點,葉子節點是沒有子節點的節點,如下圖所示:
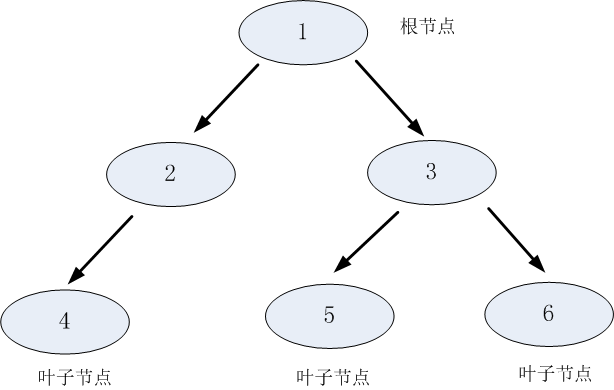
圖1.1 樹的結構示意圖
決策樹利用如上圖所示的樹結構進行決策,每一個非葉子節點是一個判斷條件,每一個葉子節點是結論。從跟節點開始,經過多次判斷得出結論。
2. 決策樹如何做決策
從一個分類例子說起:
銀行希望能夠通過一個人的資訊(包括職業、年齡、收入、學歷)去判斷他是否有貸款的意向,從而更有針對性地完成工作。下表是銀行現在能夠掌握的資訊,我們的目標是通過對下面的資料進行分析建立一個預測使用者貸款一下的模型。
表2.1 銀行使用者資訊表
| 職業 |
年齡 |
收入 |
學歷 |
是否貸款 |
| 自由職業 |
28 |
5000 |
高中 |
是 |
| 工人 |
36 |
5500 |
高中 |
否 |
| 工人 |
42 |
2800 |
初中 |
是 |
| 白領 |
45 |
3300 |
小學 |
是 |
| 白領 |
25 |
10000 |
本科 |
是 |
| 白領 |
32 |
8000 |
碩士 |
否 |
| 白領 |
28 |
13000 |
博士 |
是 |
| 自由職業 |
21 |
4000 |
本科 |
否 |
| 自由職業 |
22 |
3200 |
小學 |
否 |
| 工人 |
33 |
3000 |
高中 |
否 |
| 工人 |
48 |
4200 |
小學 |
否 |
(注:上表中的資料都由本人捏造,不具有任何實際的意義)
上邊中有4個客戶的屬性,如何綜合利用這些屬性去判斷使用者的貸款意向?決策樹的做法是每次選擇一個屬性進行判斷,如果不能得出結論,繼續選擇其他屬性進行判斷,直到能夠“肯定地”判斷出使用者的型別或者是上述屬性都已經使用完畢。比如說我們要判斷一個客戶的貸款意向,我們可以先根據客戶的職業進行判斷,如果不能得出結論,再根據年齡作判斷,這樣以此類推,直到可以得出結論為止。
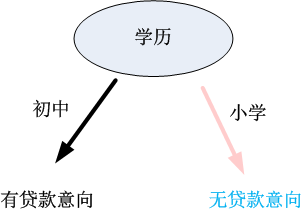
決策樹用樹結構實現上述的判斷流程,如圖2.1所示:
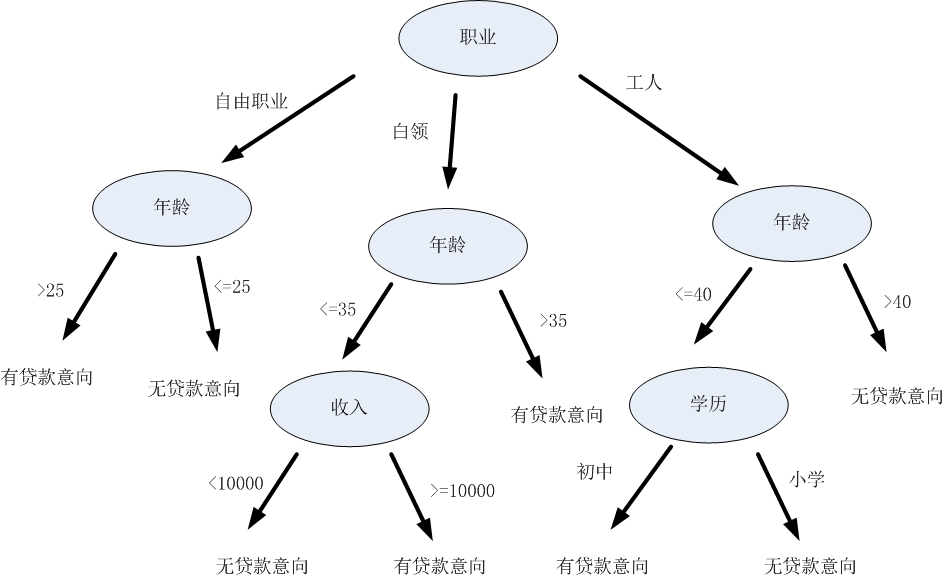
圖2.1 銀行貸款意向分析決策樹示意圖
通過圖2.1的訓練資料,我們可以建議圖2.1所示的決策樹,其輸入是使用者的資訊,輸出是使用者的貸款意向。如果要判斷某一客戶是否有貸款的意向,直接根據使用者的職業、收入、年齡以及學歷就可以分析得出使用者的型別。如某客戶的資訊為:{職業、年齡,收入,學歷}={工人、39, 1800,小學},將資訊輸入上述決策樹,可以得到下列的分析步驟和結論。
第一步:根據該客戶的職業進行判斷,選擇“工人”分支;
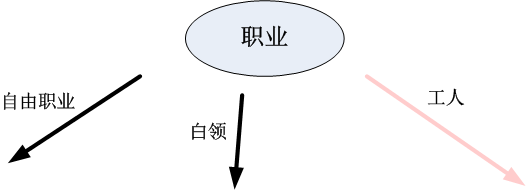
第二步:根據客戶的年齡進行選擇,選擇年齡”<=40”這一分支;
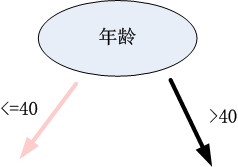
第三步:根據客戶的學歷進行選擇,選擇”小學”這一分支,得出該客戶無貸款意向的結論。
3. 決策樹的構建
那麼問題就來了,如何構建如圖2.1所示一棵決策樹呢?決策樹的構建是資料逐步分裂的過程,構建的步驟如下:
步驟1:將所有的資料看成是一個節點,進入步驟2;
步驟2:從所有的資料特徵中挑選一個數據特徵對節點進行分割,進入步驟3;
步驟3:生成若干孩子節點,對每一個孩子節點進行判斷,如果滿足停止分裂的條件,進入步驟4;否則,進入步驟2;
步驟4:設定該節點是子節點,其輸出的結果為該節點數量佔比最大的類別。
從上述步驟可以看出,決策生成過程中有兩個重要的問題:
(1)資料如何分割
(2)如何選擇分裂的屬性
(3)什麼時候停止分裂
3.1 資料分割
假如我們已經選擇了一個分裂的屬性,那怎樣對資料進行分裂呢?
分裂屬性的資料型別分為離散型和連續性兩種情況,對於離散型的資料,按照屬性值進行分裂,每個屬性值對應一個分裂節點;對於連續性屬性,一般性的做法是對資料按照該屬性進行排序,再將資料分成若干區間,如[0,10]、[10,20]、[20,30]…,一個區間對應一個節點,若資料的屬性值落入某一區間則該資料就屬於其對應的節點。
例:
表3.1 分類資訊表
| 職業 |
年齡 |
是否貸款 |
| 白領 |
30 |
否 |
| 工人 |
40 |
否 |
| 工人 |
20 |
否 |
| 學生 |
15 |
否 |
| 學生 |
18 |
是 |
| 白領 |
42 |
是 |
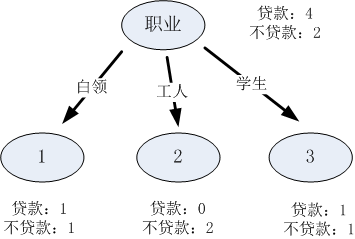
(1)屬性1“職業”是離散型變數,有三個取值,分別為白領、工人和學生,根據三個取值對原始的資料進行分割,如下表所示:
表3.2 屬性1資料分割表
| 取值 |
貸款 |
不貸款 |
| 白領 |
1 |
1 |
| 工人 |
0 |
2 |
| 學生 |
1 |
1 |
表3.2可以表示成如下的決策樹結構:
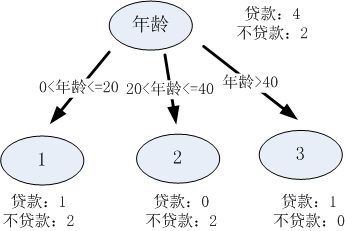
(2)屬性2是連續性變數,這裡將資料分成三個區間,分別是[10,20]、[20,30]、[30,40],則每一個區間的分裂結果如下:
表3.3 屬性2資料分割表
| 區間 |
貸款 |
不貸款 |
| [0,20] |
1 |
2 |
| (20,40] |
0 |
2 |
| (40,—] |
1 |
0 |
表3.3可以表示成如下的決策樹結構:
3.2 分裂屬性的選擇
我們知道了分裂屬性是如何對資料進行分割的,那麼我們怎樣選擇分裂的屬性呢?
決策樹採用貪婪思想進行分裂,即選擇可以得到最優分裂結果的屬性進行分裂。那麼怎樣才算是最優的分裂結果?最理想的情況當然是能找到一個屬性剛好能夠將不同類別分開,但是大多數情況下分裂很難一步到位,我們希望每一次分裂之後孩子節點的資料儘量”純”,以下圖為例:
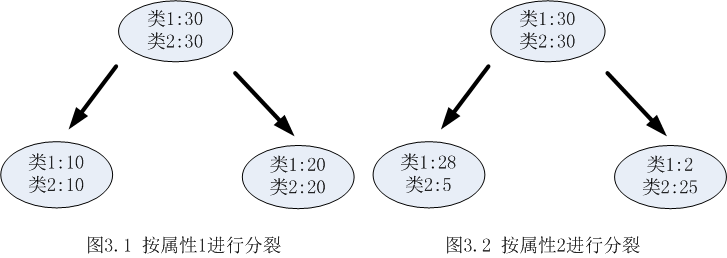
從圖3.1和圖3.2可以明顯看出,屬性2分裂後的孩子節點比屬性1分裂後的孩子節點更純:屬性1分裂後每個節點的兩類的數量還是相同,跟根節點的分類結果相比完全沒有提高;按照屬性2分裂後每個節點各類的數量相差比較大,可以很大概率認為第一個孩子節點的輸出結果為類1,第2個孩子節點的輸出結果為2。
選擇分裂屬性是要找出能夠使所有孩子節點資料最純的屬性,決策樹使用資訊增益或者資訊增益率作為選擇屬性的依據。
(1)資訊增益
用資訊增益表示分裂前後跟的資料複雜度和分裂節點資料複雜度的變化值,計算公式表示為:
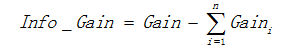
其中Gain表示節點的複雜度,Gain越高,說明覆雜度越高。資訊增益說白了就是分裂前的資料複雜度減去孩子節點的資料複雜度的和,資訊增益越大,分裂後的複雜度減小得越多,分類的效果越明顯。
節點的複雜度可以用以下兩種不同的計算方式:
a)熵
熵描述了資料的混亂程度,熵越大,混亂程度越高,也就是純度越低;反之,熵越小,混亂程度越低,純度越高。 熵的計算公式如下所示:
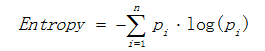
其中Pi表示類i的數量佔比。以二分類問題為例,如果兩類的數量相同,此時分類節點的純度最低,熵等於1;如果節點的資料屬於同一類時,此時節點的純度最高,熵 等於0。
b)基尼值
基尼值計算公式如下:
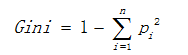
其中Pi表示類i的數量佔比。其同樣以上述熵的二分類例子為例,當兩類數量相等時,基尼值等於0.5 ;當節點資料屬於同一類時,基尼值等於0 。基尼值越大,資料越不純。
例:
以熵作為節點複雜度的統計量,分別求出下面例子的資訊增益,圖3.1表示節點選擇屬性1進行分裂的結果,圖3.2表示節點選擇屬性2進行分裂的結果,通過計算兩個屬性分裂後的資訊增益,選擇最優的分裂屬性。
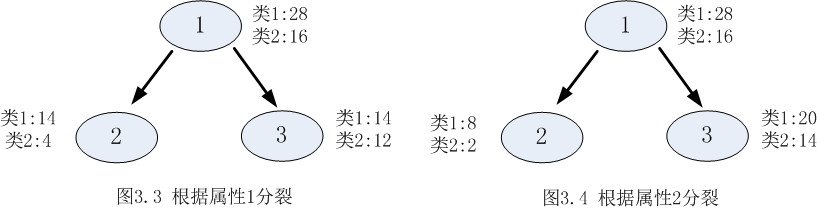
屬性1:
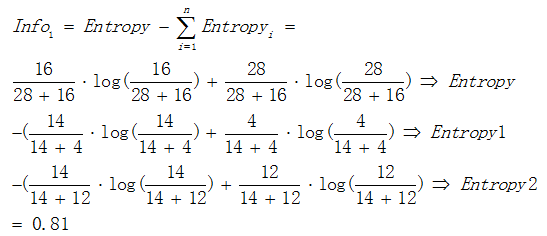
屬性2:
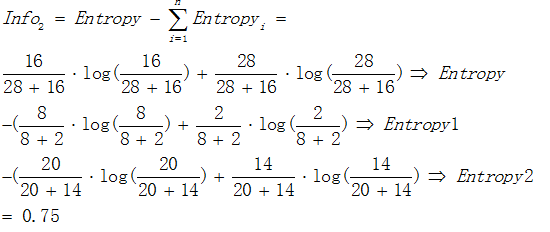
由於 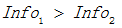 ,所以屬性1與屬性2相比是更優的分裂屬性,故選擇屬性1作為分裂的屬性。
,所以屬性1與屬性2相比是更優的分裂屬性,故選擇屬性1作為分裂的屬性。
(2)資訊增益率
使用資訊增益作為選擇分裂的條件有一個不可避免的缺點:傾向選擇分支比較多的屬性進行分裂。為了解決這個問題,引入了資訊增益率這個概念。資訊增益率是在資訊增益的基礎上除以分裂節點資料量的資訊增益(聽起來很拗口),其計算公式如下:
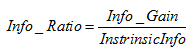
其中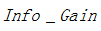 表示資訊增益,
表示資訊增益,  表示分裂子節點資料量的資訊增益,其計算公式為:
表示分裂子節點資料量的資訊增益,其計算公式為:
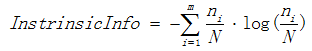
其中m表示子節點的數量,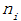 表示第i個子節點的資料量,N表示父節點資料量,說白了, 其實
表示第i個子節點的資料量,N表示父節點資料量,說白了, 其實 是分裂節點的熵,如果節點的資料鏈越接近,越大,如果子節點越大,越大,而
是分裂節點的熵,如果節點的資料鏈越接近,越大,如果子節點越大,越大,而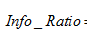 就會越小,能夠降低節點分裂時選擇子節點多的分裂屬性的傾向性。資訊增益率越高,說明分裂的效果越好。
就會越小,能夠降低節點分裂時選擇子節點多的分裂屬性的傾向性。資訊增益率越高,說明分裂的效果越好。
還是資訊增益中提及的例子為例:
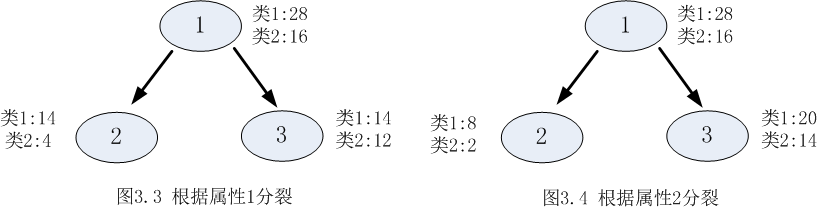
屬性1的資訊增益率:
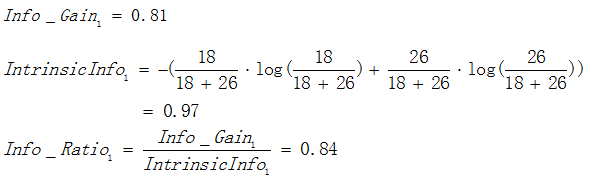
屬性2的資訊增益率:
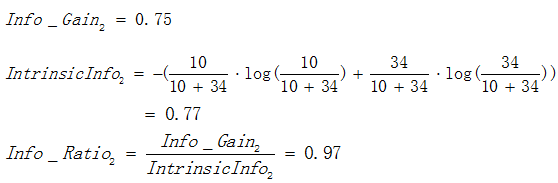
由於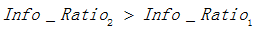 ,故選擇屬性2作為分裂的屬性。
,故選擇屬性2作為分裂的屬性。
3.3 停止分裂的條件
決策樹不可能不限制地生長,總有停止分裂的時候,最極端的情況是當節點分裂到只剩下一個數據點時自動結束分裂,但這種情況下樹過於複雜,而且預測的經度不高。一般情況下為了降低決策樹複雜度和提高預測的經度,會適當提前終止節點的分裂。
以下是決策樹節點停止分裂的一般性條件:
(1)最小節點數
當節點的資料量小於一個指定的數量時,不繼續分裂。兩個原因:一是資料量較少時,再做分裂容易強化噪聲資料的作用;二是降低樹生長的複雜性。提前結束分裂一定程度上有利於降低過擬合的影響。
(2)熵或者基尼值小於閥值。
由上述可知,熵和基尼值的大小表示資料的複雜程度,當熵或者基尼值過小時,表示資料的純度比較大,如果熵或者基尼值小於一定程度數,節點停止分裂。
(3)決策樹的深度達到指定的條件
節點的深度可以理解為節點與決策樹跟節點的距離,如根節點的子節點的深度為1,因為這些節點與跟節點的距離為1,子節點的深度要比父節點的深度大1。決策樹的深度是所有葉子節點的最大深度,當深度到達指定的上限大小時,停止分裂。
(4)所有特徵已經使用完畢,不能繼續進行分裂。
被動式停止分裂的條件,當已經沒有可分的屬性時,直接將當前節點設定為葉子節點。
3.4 決策樹的構建方法
根據決策樹的輸出結果,決策樹可以分為分類樹和迴歸樹,分類樹輸出的結果為具體的類別,而回歸樹輸出的結果為一個確定的數值。
決策樹的構建演算法主要有ID3、C4.5、CART三種,其中ID3和C4.5是分類樹,CART是分類迴歸樹,將在本系列的ID3、C4.5和CART中分別講述。
其中ID3是決策樹最基本的構建演算法,而C4.5和CART是在ID3的基礎上進行優化的演算法。
4. 決策樹的優化
一棵過於複雜的決策樹很可能出現過擬合的情況,如果完全按照3中生成一個完整的決策樹可能會出現預測不準確的情況,因此需要對決策樹進行優化,優化的方法主要有兩種,一是剪枝,二是組合樹,將在本系列的剪枝和組合樹中分別講述。