
尚矽谷 Java面試題 第一季 - 20181221
SSM
一、SpringBean的作用域之間有什麼區別?
其實就是scope屬性裡設定singleton | prototype 兩個屬性,預設是singleton單例的
prototype是多例項。
其他的request:每次HTTP請求會建立新的bean,該作用域僅適用於WebApplicationContext環境。
session:同一個HTTP session共享bean,該作用域僅適用於WebApplicationContext環境。
二、Spring支援的常用資料庫事務傳播屬性和事務隔離級別?
三、SpringMVC解決中如何解決POST請求中文亂碼問題
springmvc提供了過濾器CharacterEncodingFilter:這個類有兩個變數String型別的encoding、boolean型別forceEncoding預設false,核心方法doFilterInternal,方法中有request.setCharacterEncoding設定請求字符集,設force那個為true的話,可以設定response.setCharacterEncoding。
那麼在web.xml裡需要配置這一屬性:
<!--post方式字符集-->
<filter>
<filter-name>CharacterEncodingFilter</ get方式,修改Tomcat的server.xml中的配置。
四、簡單的談一下SpringMVC的工作流程
springmvc在處理模型資料有兩種方式:方式一.返回值是ModelAndView、方式二.在引數中傳入Map,Model或者ModelMap;最後都會轉換為一個 ModelAndView物件(所以是以request作用域來響應使用者)
流程如下圖:
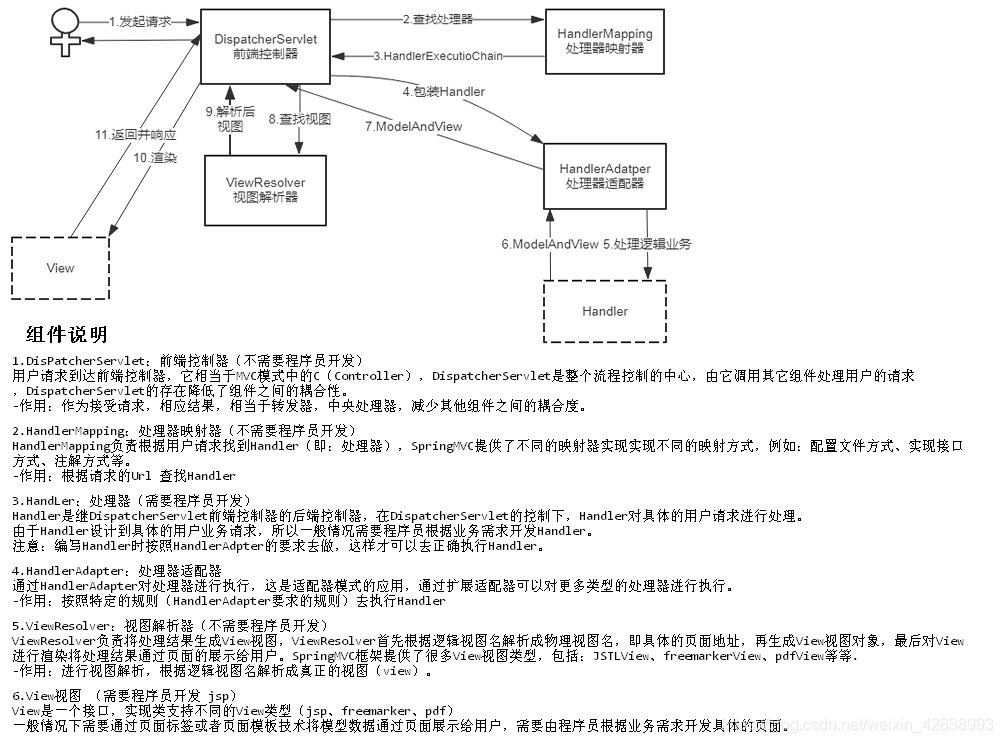
總結
請求過來後,先到DispatcherServlet中央處理器,之後它會呼叫處理器對映器找到HandlerMapping處理器對映器裡的方法,返回HandlerExecultionChain物件,這個物件包含了所有的攔截器和處理器。
之後拿到HandlerAdapter處理器介面卡,由它找到對應的處理器去呼叫請求,相當於呼叫controller之後,會返回ModelAndView物件,這個物件返回到中央處理器。
中央處理器通過我們在springmvc配置檔案中配的InternalResourceViewResolver檢視解析器,得到檢視InternalResourceView。
得到檢視之後,呼叫裡邊的方法進行渲染檢視,將我們的模型資料,在頁面給使用者呈現出來,響應給使用者。
五、MyBatis中當實體類中的屬性名和表中的欄位名不一樣,怎麼辦?(三種解決方案)
- 寫sql語句時起別名
- 在MyBatis的全域性配置檔案中開啟駝峰命名規則(前提只是將資料庫中下劃線對映)
- 在Mapper對映檔案中使用ResultMap自定義對映
Java高階
一、Linux常用服務類相關命令
CentOS 6
- 常用基本命令-程序類
- 註冊在系統中的標準化程式
- service 服務名 start
- service 服務名 stop
- service 服務名 restart
- service 服務名 reload
- service 服務名 status
- 通過chkconfig 命令設定自啟動程式
- chkcongfig --list #可以檢視所有對應服務自啟動狀態開關
- chkcongfig --level 3 服務名 off #on自啟動、off不自啟動
執行級別runlevel(centos6),
常用級別3和5
0 停機、1 單使用者root狀態、2 多使用者狀態、3 有網多使用者狀態、4. 保留、5 圖形模式、6、重啟
CentOS 7
- 註冊在系統中的標準化程式
- systemctl start 服務名
- systemctl restart 服務名
- systemctl stop 服務名 #示例:停防火牆 systemctl stop firewalld
- systemctl reload 服務名
- systemctl status 服務名
- 檢視服務的命令
- systemctl list-unit-files #示例:systemctl list-unit-files |grep firewalld
- systemctl --type service
- 設定自啟動/不自啟動
- systemctl enable 服務名
- systemctl disable 服務名
二、git分支相關命令
Git:分散式版本控制工具
-
建立分支
-
切換分支
一步完成:git checkout -b <分支名> #直接就完成了建立,並切換過去了
-
合併分支
先切換到主幹 git checkout master
git merge <分支名> -
刪除分支
先切換到主幹 git checkout master
git branch -D <分支名>
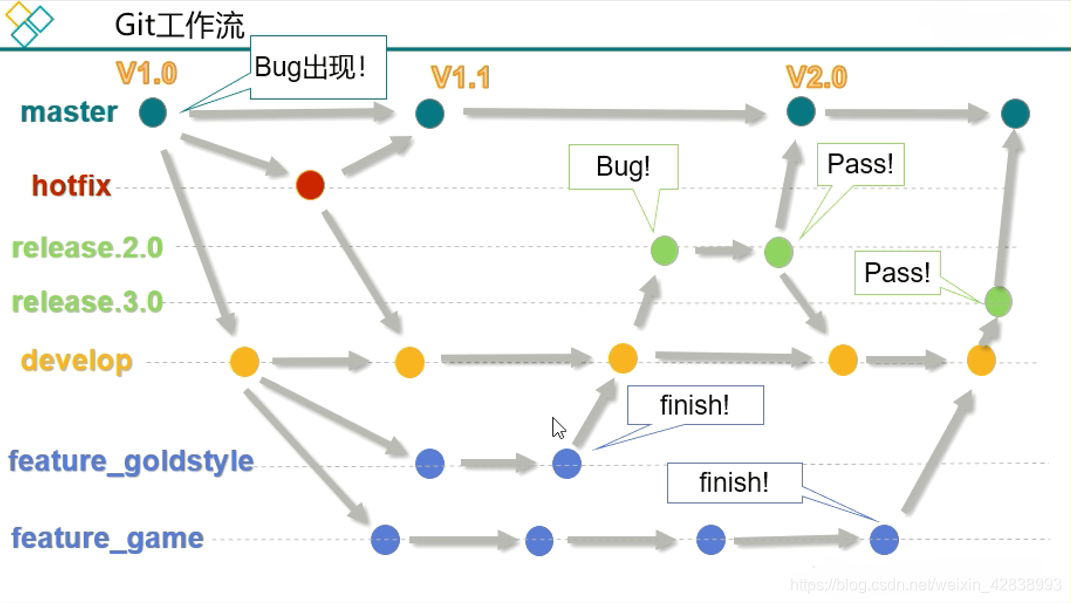
工作流:
master分支,分出多個develop分支,並行開發互不影響;出現bug了,可以有master分出一個臨時分支,處理完後再合併到master中合併上線;之後將臨時分支合併到develop分支,保證版本一致,避免bug重複出現。
開發人員開發完成了,先合併到dev分支,建立測試分支進行測試,沒問題了在合併到master上線,之後再和dev合併保證一致。
三、redis持久化幾種型別及區別?
兩種:
-
RDB(Redis DataBase)快照,將所有記憶體資料進行
全量儲存;優點:省空間,效率高;缺點:資料量大耗效能,最後一次持久化可能資料丟失 -
AOF(Append Of File)日誌,以日誌形式來記錄每個寫操作
增量操作;優點:備份穩健,可讀日誌處理誤操作;缺點:佔更多磁碟,備份慢,佔效能
四、Mysql建索引的時機?
MySQL官方定義:索引(Index)是幫助MySQL高效獲取資料的資料結構。簡而言之,索引本質是資料結構。
優:提高檢索效率,降低資料庫IO成本;通過索引列對資料進行排序,降低排序成本,降低cpu消耗。
劣:降低更新表的速度,因為更新表時,不僅要儲存資料,還要儲存索引更新了的索引列欄位,不斷調整索引資訊。
實際上,索引也是一張表,該表儲存了主鍵與索引欄位,並指向實體表的記錄,所以索引列也要佔用空間
- 建立索引
主鍵自動唯一、頻繁查詢欄位、外來鍵關聯欄位、組合索引價效比高、排序欄位、統計或分組欄位(分組更傷效能)
- 不建立索引
表記錄太少、頻繁增刪改、where用不到欄位、過濾性不好欄位(例:性別)
五、JVM垃圾回收機制 - GC發生在JVM哪部分,有幾種GC,它們的演算法是什麼?
GC發生在heap堆中。
GC是分代收集演算法:頻繁收集年輕代``Minor GC、次數較少老年代``Full GC、永久區不GC
GC的四大演算法:
- 引用回收演算法(物件有引用,就不回收,已淘汰,無法處理迴圈引用)
- 複製演算法(發生在YG、效率高,無碎片,佔空間)
- 標記清楚(發生在OG、省空間,產生碎片)
- 標記壓縮(OG、成本高)
- 標記清除壓縮(OG、③④混合)
Java專案
一、redis在專案中的使用場景 (各資料型別)
-
String
繫結ip地址,可以記錄ip地址的操作。 -
Hash
儲存使用者資訊【id,name,age】
Hset(key,field,value)
Hset(userKey,id,101)
當我修改使用者資訊某一項屬性的時候,可以直接取出單一的值。
不建議使用String型別是因為,在反序列化時,會全部序列化出來,會增加IO次數,降低效能。 -
List
實現最新訊息的排行,
還可以利用List的push命令,將任務存在list集合中,同時使用另一個命令,將任務從集合中取出[pop]。
Redis — List 資料型別來模擬訊息佇列。【電商中的秒殺就可以採用這種方式來完成一個秒殺活動】 -
Set
特殊之處:可以自動排重(非重複)。比如說微博中將每個人的好友存在集合(Set)中,
這樣求兩個人的共通好友的操作。我們只需要求交集即可。 -
Zset (SortedSet)
以某一個條件為權重,進行排序。 京東:商品詳情的時候,都會有一個綜合排名,還可以按照價格進行排名。
二、ES和solr的區別?
它們都是基於Lucene搜尋伺服器基礎上開發,高效能的企業級搜尋服務。【它們都是基於分詞技術構建的倒排索引方式進行查詢】
區別:
- 當實時建立索引的時候,solr會產生io阻塞,而es則不會,es查詢效能高於solr。
- 在不斷動態新增資料的時候,solr的檢索效率會下降,es則不會。
- Solr利用zk進行分散式管理,es自身帶有分散式系統管理功能。
Solr的本質是web專案,需要部署到web伺服器上,啟動伺服器時需配置solr。 - Solr支援更多的格式資料[xml、json、csv],而es僅支援json檔案格式。
- Solr是傳統搜尋應用的有力解決方案,但是es更適合新興實時搜尋應用。【solr適合已有資料搜尋時,效率更好;需要動態增添資料時,es效率更高】
- solr的觀望提供功能更多,es更注重核心搜尋功能,高階功能需要三方整合。
-
Solr叢集圖
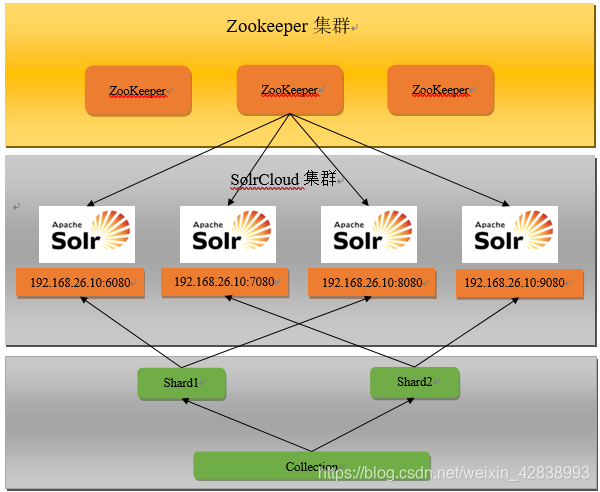
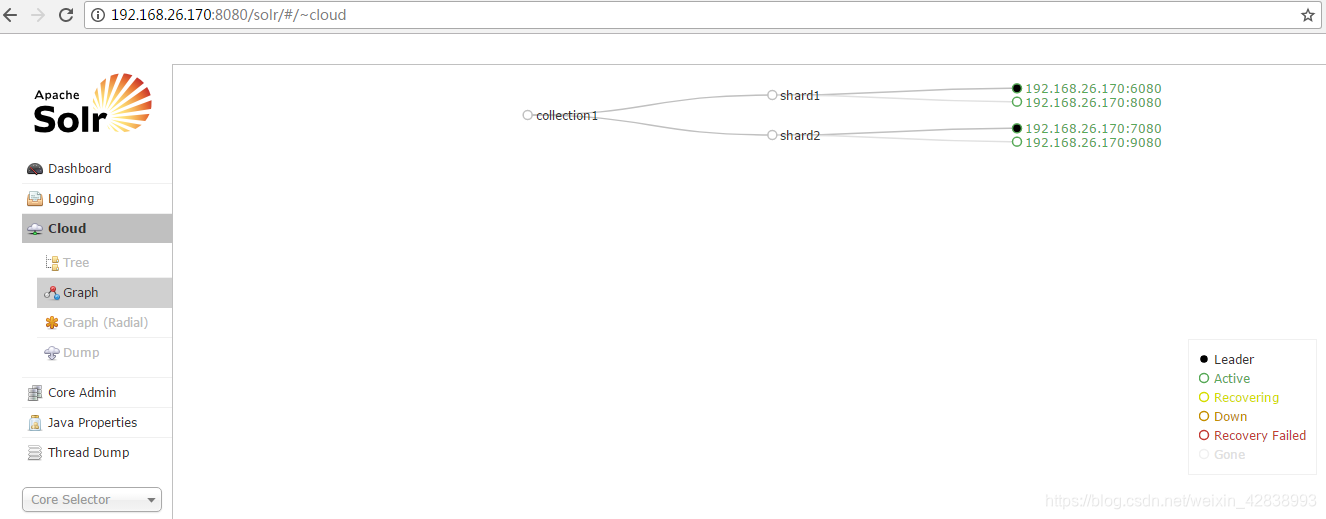
-
ElasticSearch叢集圖
三、單點登入實現過程?
單點登入:一處登入、多處使用
(前提:單點登入多使用在分散式系統中)
【京東:單點登入是將token放入到cookie中】
四、購物車實現過程?
- 購物車跟使用者的關係!
無論買多少商品,一個使用者必須對應一個購物車。單點登入在購物車之前。 - 跟購物車有關操作
- 新增購物車
使用者未登入:資料儲存到Redis【京東將未登入購物車放在redis中,給未登入使用者儲存唯一標識uuid,儲存使用者未登入時的購物車資訊】、cookie
使用者登入:Redis快取[hash或string:hset(key,field,value)],讀寫速度快;保證資料安全性,將資料存到資料庫中。 - 展示購物車
未登入狀態:直接從cookie中取得資料展示即可
登入狀態:使用者一旦登入,必須顯示資料庫或Redis以及cookie中的購物車綜合資料
五、訊息佇列的使用?
分散式系統中處理高併發的情景。
由於高併發的環境下,來不及同步處理大量請求,則會導致請求發生阻塞。這是使用訊息佇列的非同步通訊可以解決問題。
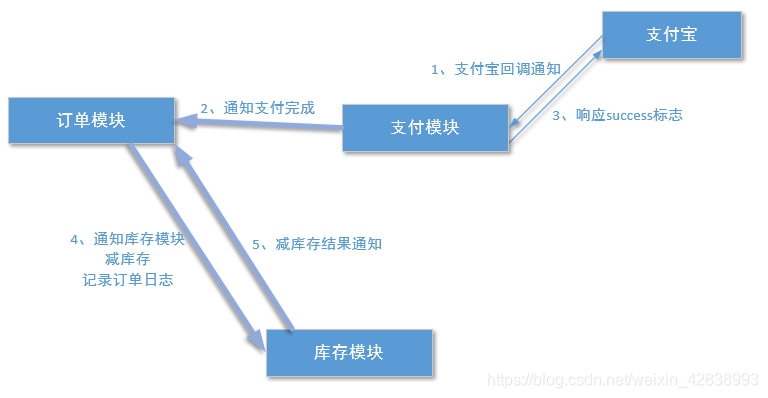
訊息佇列弊端:
訊息的不確定性,延遲佇列,輪詢技術來解決該問題即可!(ActiveMQ java)