
Storm WordCount程式設計模型,併發度&分組策略
阿新 • • 發佈:2018-12-27
程式設計模型:
Spout
/** * @program: WordCountSpout.class * @description: 傳輸資料到bolt,有一個抽象類BaseRichSpout,BaseRichBolt,一個介面IRichSpout,IRichBolt, * 常用抽象類 * @author: YCF * @create: 2018/12/22 **/ public class WordCountSpout extends BaseRichSpout { //定義收集器 SpoutOutputCollector Collector ; //初始化 public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector Collector) { this.Collector = Collector; } //傳送資料到Bolt public void nextTuple() { //傳送資料 Collector.emit(new Values("I am ycf very hen shuai")); //延時 try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } //宣告 public void declareOutputFields(OutputFieldsDeclarer out) { out.declare(new Fields("itstar")); } }
Bolt
public class WordCountSplitBolt extends BaseRichBolt { //定義收集器 OutputCollector Collector ; //初始化 public void prepare(Map map, TopologyContext topologyContext, OutputCollector Collector) { this.Collector = Collector; } //業務邏輯 public void execute(Tuple in) { //獲取資料 String line = in.getStringByField("itstar"); //資料切分 String[] fields = line.split(" "); //傳送資料 for (String w : fields){ Collector.emit(new Values(w,1)); } } //宣告 public void declareOutputFields(OutputFieldsDeclarer out) { out.declare(new Fields("word","sum")); } }
public class WordCountBolt extends BaseRichBolt { Map<String,Integer> map = new HashMap(); //初始化 public void prepare(Map map, TopologyContext topologyContext, OutputCollector Collector) { } //業務邏輯 public void execute(Tuple in) { //獲取資料 String word = in.getStringByField("word"); Integer sum = in.getIntegerByField("sum"); //資料整合 if (map.containsKey(word)){ Integer value = map.get(word); map.put(word,value+sum); }else { map.put(word,sum); } //列印到控制檯 System.err.println(Thread.currentThread().getName()+"\t"+"單詞位:"+ word + "\t 當前已出現次數為:" + map.get(word)); } //宣告 public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } }
Driver
public class WordCountDrive {
public static void main(String[] args) {
//例項化拓撲
TopologyBuilder builder = new TopologyBuilder();
//指定設定,分組策略
builder.setSpout("WordCountSpout",new WordCountSpout(),2);
builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(),4).fieldsGrouping("WordCountSpout",new Fields("itstar"));
builder.setBolt("WordCountBolt",new WordCountBolt(),2).fieldsGrouping("WordCountSplitBolt",new Fields("word"));
//初始化配置
Config config = new Config();
//提交任務
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCountTopology",config,builder.createTopology());
}
}
執行結果(擷取部分):
Thread-20-WordCountBolt-executor[2 2] 單詞位:ycf 當前已出現次數為:34
Thread-26-WordCountBolt-executor[1 1] 單詞位:hen 當前已出現次數為:34
Thread-20-WordCountBolt-executor[2 2] 單詞位:very 當前已出現次數為:34
Thread-20-WordCountBolt-executor[2 2] 單詞位:shuai 當前已出現次數為:34
Thread-20-WordCountBolt-executor[2 2] 單詞位:am 當前已出現次數為:35
Thread-20-WordCountBolt-executor[2 2] 單詞位:ycf 當前已出現次數為:35
Thread-26-WordCountBolt-executor[1 1] 單詞位:I 當前已出現次數為:35
Thread-20-WordCountBolt-executor[2 2] 單詞位:very 當前已出現次數為:35
Thread-26-WordCountBolt-executor[1 1] 單詞位:hen 當前已出現次數為:35
Thread-20-WordCountBolt-executor[2 2] 單詞位:shuai 當前已出現次數為:35
Thread-26-WordCountBolt-executor[1 1] 單詞位:I 當前已出現次數為:36
Thread-26-WordCountBolt-executor[1 1] 單詞位:hen 當前已出現次數為:36
Thread-20-WordCountBolt-executor[2 2] 單詞位:am 當前已出現次數為:36
Thread-20-WordCountBolt-executor[2 2] 單詞位:ycf 當前已出現次數為:36
Thread-20-WordCountBolt-executor[2 2] 單詞位:very 當前已出現次數為:36
Thread-20-WordCountBolt-executor[2 2] 單詞位:shuai 當前已出現次數為:36
Thread-20-WordCountBolt-executor[2 2] 單詞位:am 當前已出現次數為:37
Thread-26-WordCountBolt-executor[1 1] 單詞位:I 當前已出現次數為:37
Thread-20-WordCountBolt-executor[2 2] 單詞位:ycf 當前已出現次數為:37
Thread-26-WordCountBolt-executor[1 1] 單詞位:hen 當前已出現次數為:37
Thread-20-WordCountBolt-executor[2 2] 單詞位:very 當前已出現次數為:37
Thread-20-WordCountBolt-executor[2 2] 單詞位:shuai 當前已出現次數為:37
Thread-20-WordCountBolt-executor[2 2] 單詞位:am 當前已出現次數為:38
Spout->傳輸資料->Bolt->將資料分切+1(map)
->Bolt->整合資料(reduce)
併發度&分組策略
1)Fields Grouping
按照欄位分組。相同欄位傳送到一個task中。
2)shuffle Grouping
隨機分組。輪詢。平均分配。隨機分發tuple,保證每個bolt中的tuple數量相同。
3)Non Grouping
不分組
採用這種策略每個bolt中接收的單詞不同。
4)All Grouping
廣播發送
5)Global Grouping
全域性分組
分配給task id值最小的
根據執行緒id判斷,只分噢誒給執行緒id最小的
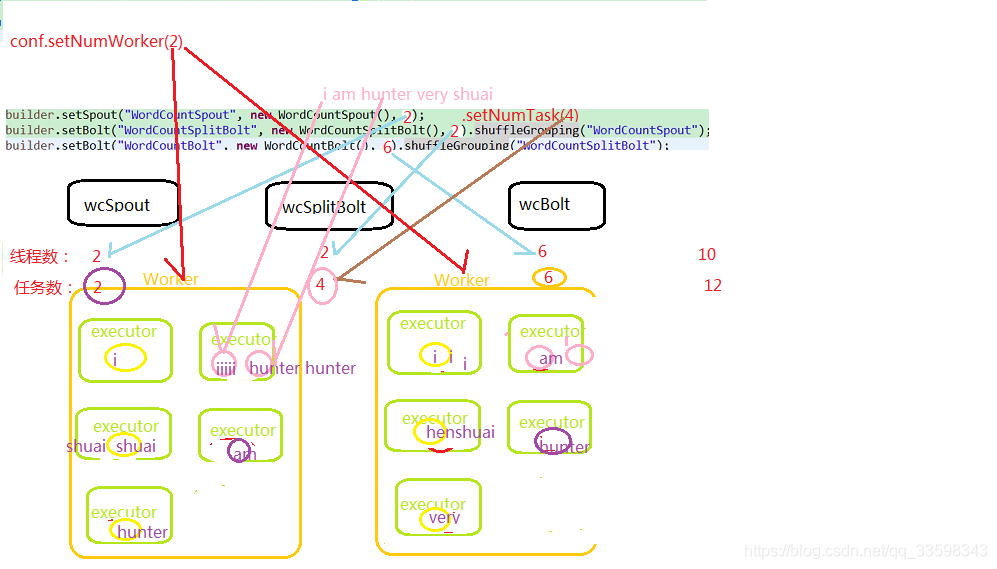
設定
Worker數為2個
總的執行緒數為10個,並行度決定了執行緒數/executor的數量,也就是10個executor.
總的任務數為12個,因為splitBolt設定了task數為4個,所以是2+4+6
一個executor可以對應多個task任務,所以splitBolt的task,在圖中executor中是兩個與兩個的
每個執行緒是單獨執行自己的業務邏輯,對於我們這個wordcount的程式來說,使用圖中的shuffle分組策略是影響了業務邏輯的,因為他隨機分給每個執行緒單詞,每個執行緒都有可能接收同樣的單詞,並且執行自己的業務邏輯,也就造成每個執行緒統計的同樣的單詞可能有數量差異,還需要把每個執行緒的結果都給加起來,我們這裡改成1的並行度就不影響業務邏輯了。
上面程式設計模型,我們使用的欄位分組策略,不影響業務邏輯