
Hive表的分割槽與分桶
阿新 • • 發佈:2018-12-27
1.Hive分割槽表
Hive使用select語句進行查詢的時候一般會掃描整個表內容,會消耗很多時間做沒必要的工作。Hive可以在建立表的時候指定分割槽空間,這樣在做查詢的時候就可以很好的提高查詢的效率。
建立分割槽表的語法:
create table tablename(
name string
)partitioned by(key,type...);示例
附:上述語句表示在建表時劃分了date_time和type兩個分割槽也叫雙分割槽,一個分割槽的話就叫單分割槽,上述語句執行完以後我們查看錶的結果會發現多了分割槽的兩個欄位。drop table if exists employees; create table if not exists employees( name string, salary float, subordinate array<string>, deductions map<string,float>, address struct<street:string,city:string,num:int> ) partitioned by (date_time string,type string) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':' lines terminated by '\n' stored as textfile location '/hive/inner';
desc employees;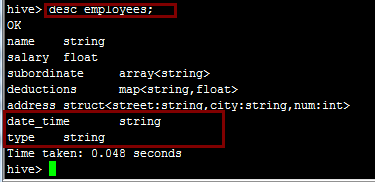
注:在檔案系統中的表現為date_time為一個資料夾,type為date_time的子資料夾。
向分割槽表中插入資料(要指定分割槽)
hive> load data local inpath '/usr/local/src/employee_data' into table employees partition(date_time='2015-01_24',type='userInfo'); Copying data from file:/usr/local/src/employee_data Copying file: file:/usr/local/src/employee_data Loading data to table default.employees partition (date_time=2015-01_24, type=userInfo) OK Time taken: 0.22 seconds hive>
資料插入後在檔案系統中顯示為:
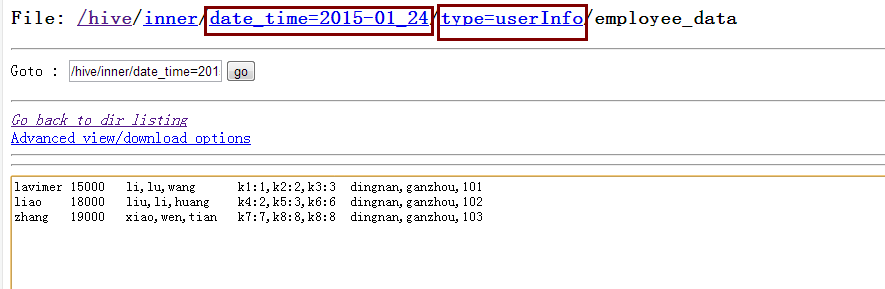
注:從上圖中我們就可以發現type分割槽是作為子資料夾的形式存在的。
新增分割槽:
alter table employees add if not exists partition(date_time='2088-08-18',type='liaozhongmin');檢視分割槽:
show partitions employees;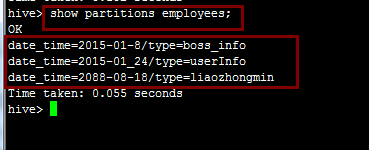
刪除不想要的分割槽
alter table employees drop if exists partition(date_time='2015-01_24',type='userInfo');
再次檢視分割槽:
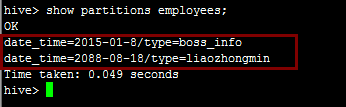
2.Hive桶表
對於每一個表或者是分割槽,Hive可以進一步組織成桶,也就是說桶是更為細粒度的資料範圍劃分。Hive是針對某一列進行分桶。Hive採用對列值雜湊,然後除以桶的個數求餘的方式決定該條記錄存放在哪個桶中。分桶的好處是可以獲得更高的查詢處理效率。使取樣更高效。
示例:
create table bucketed_user(
id int,
name string
)
clustered by(id) sorted by(name) into 4 buckets
row format delimited fields terminated by '\t'
stored as textfile;
另外一個要注意的問題是使用桶表的時候我們要開啟桶表:
set hive.enforce.bucketing = true;現在我們將表employees中name和salary查詢出來再插入到這張表中:
insert overwrite table bucketed_user select salary,name from employees;我們通過查詢語句可以檢視插進來的資料:
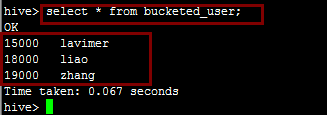
資料在檔案中的表現形式如下,分成了四個桶:
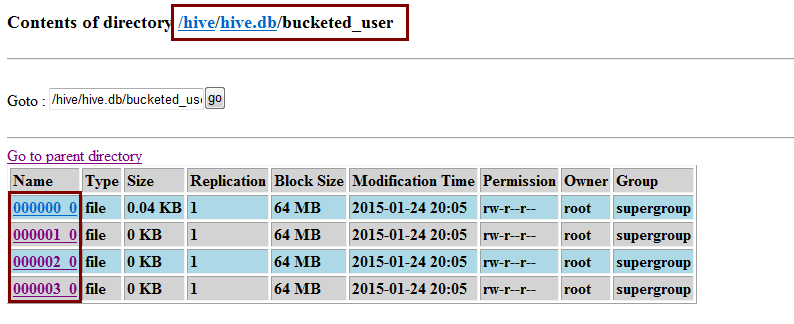
當從桶表中進行查詢時,hive會根據分桶的欄位進行計算分析出資料存放的桶中,然後直接到對應的桶中去取資料,這樣做就很好的提高了效率。