
python爬蟲【二】爬取新聞
在一個新聞站點或者絢麗的網頁會有許多id和class 我們可以通過觀察來看到我們需要的資訊在那些id和class下
但是這裡介紹兩種快速便捷的方法
第一種使用谷歌瀏覽器自帶的開發者工具
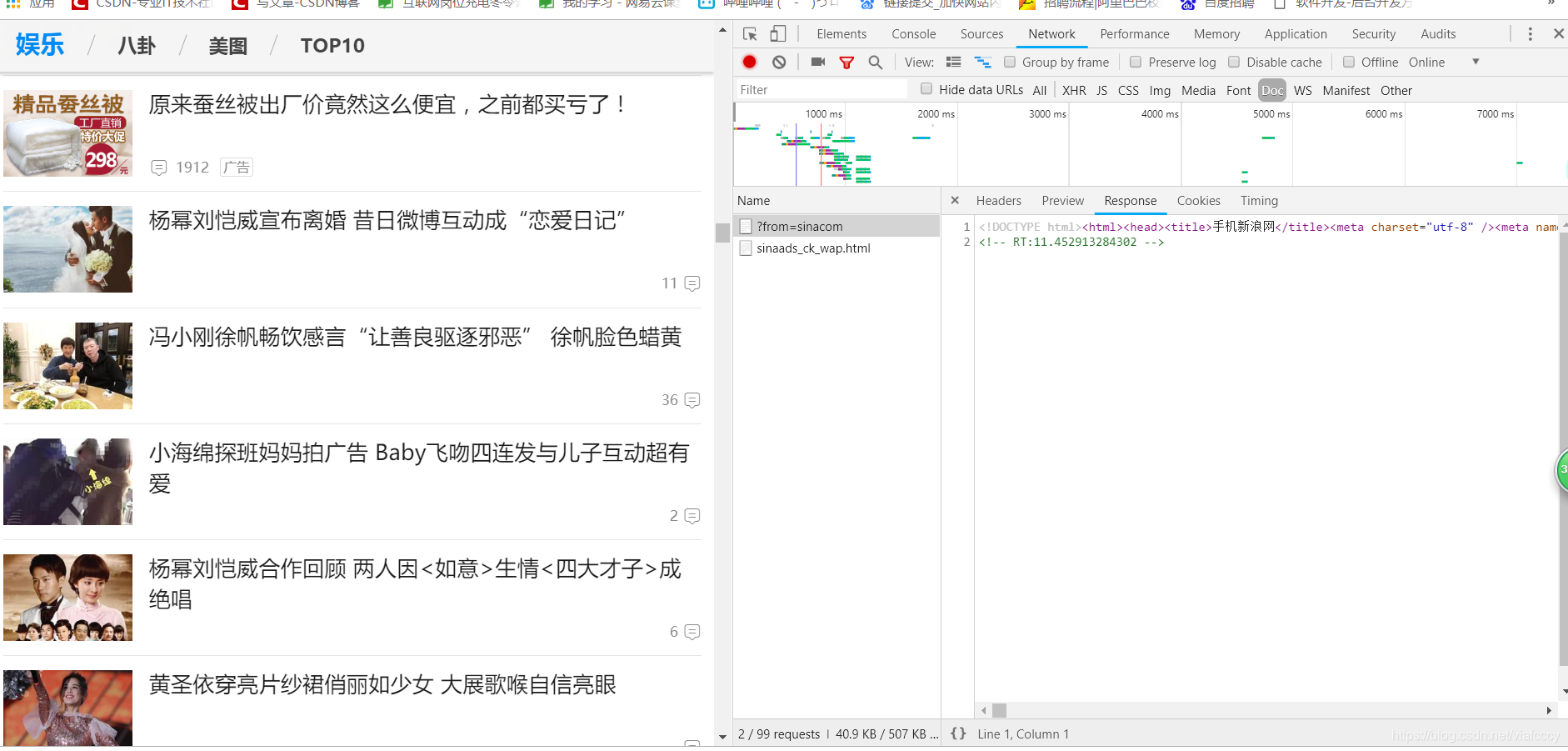
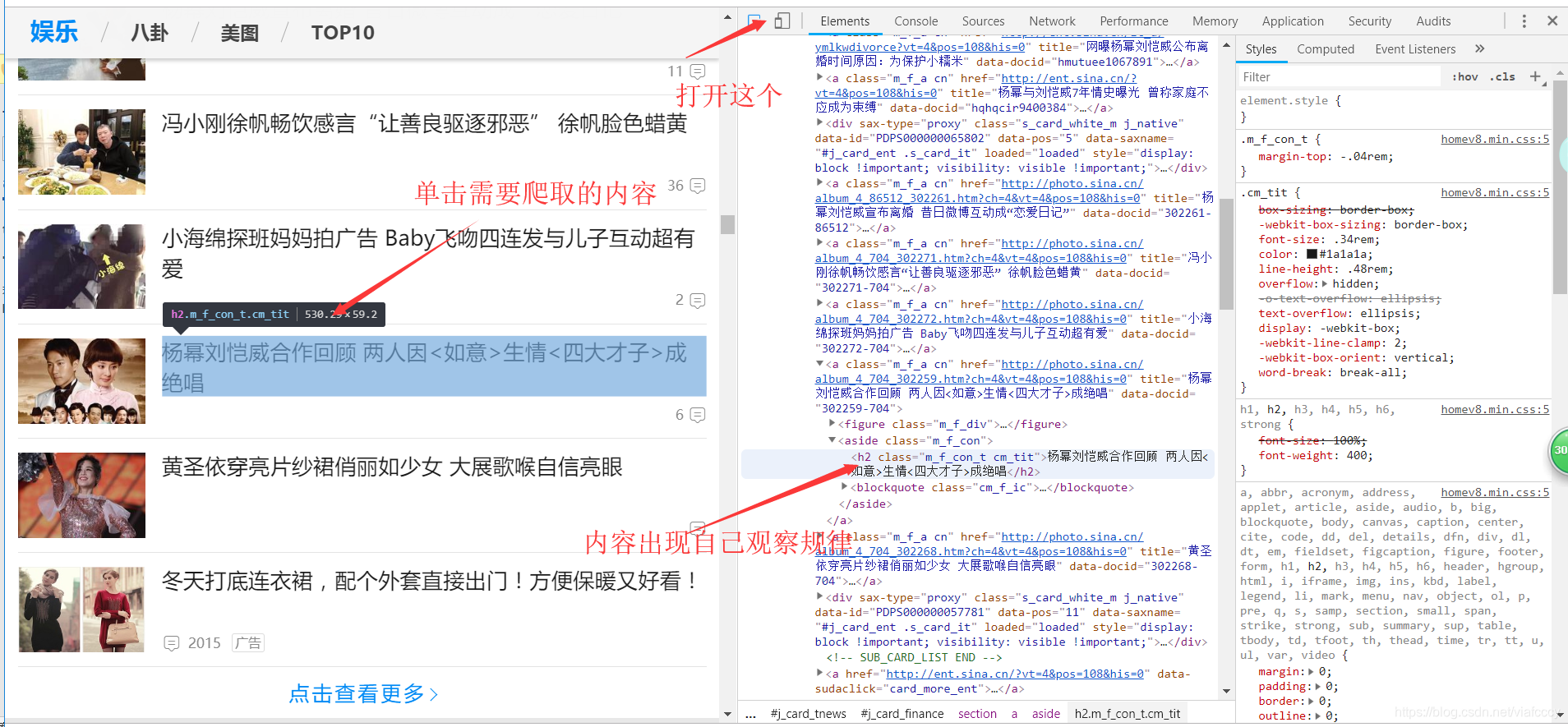
或者安裝infolite外掛安裝方法看這篇https://blog.csdn.net/viafcccy/article/details/85221588
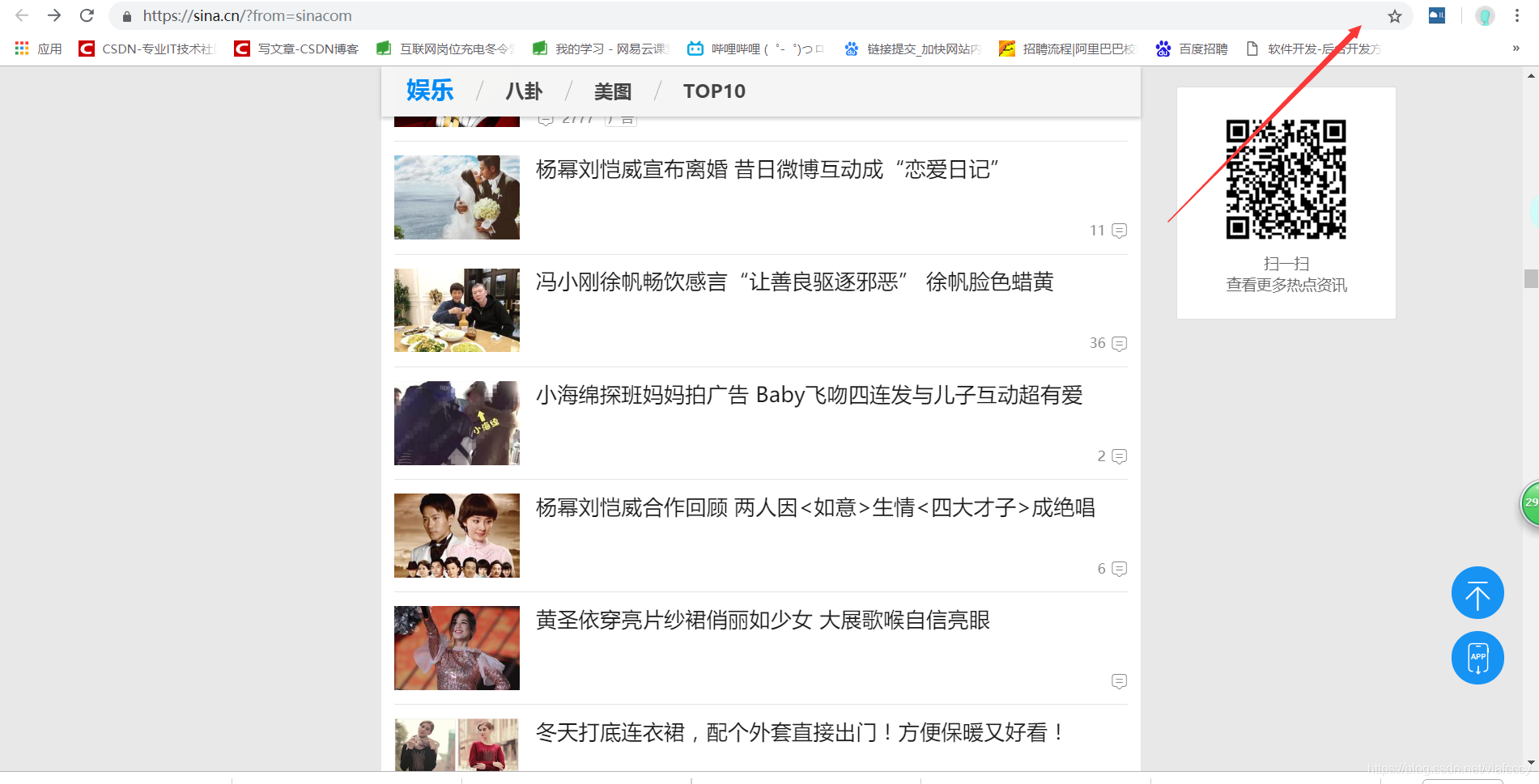
點選開啟infolite工具
直接點選需要的位置就可出現相應的語句
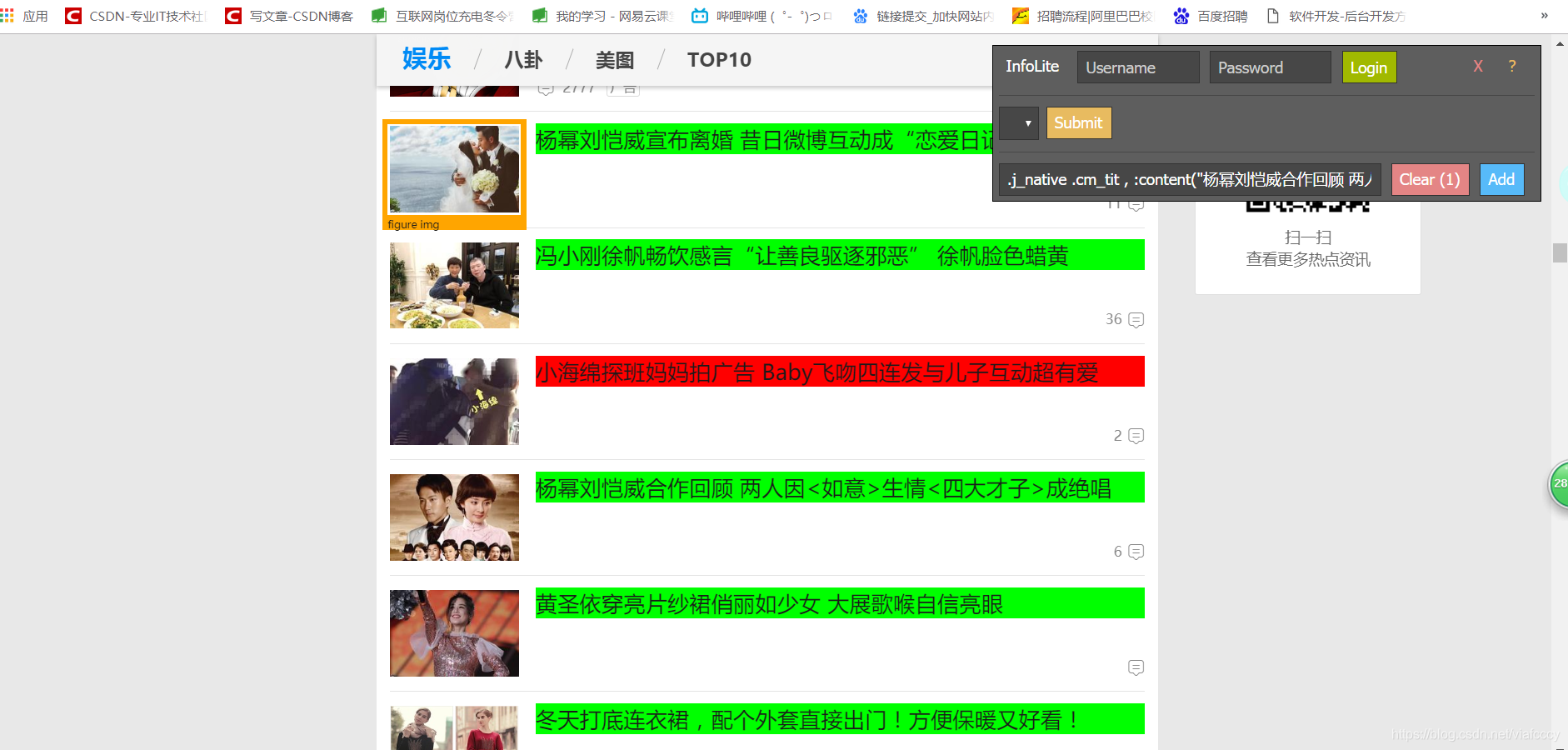
可以看到紅色的和我們需要的不一樣是廣告
我們通過觀察可以發現
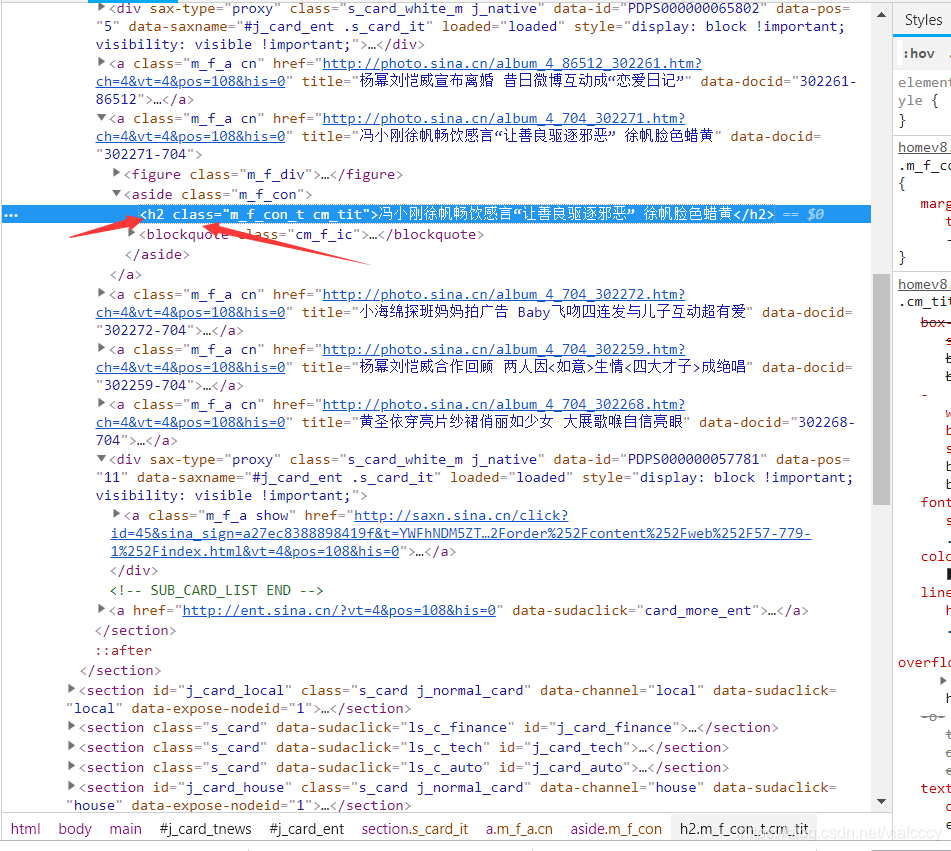
我們使用這兩個工具 就可以快速爬取指定的標籤
impot requests
from bs4 import BeautifulSoup
res = requests.get('url')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
for news in soup.select('.類的名稱'):
if len(news.select('標籤名稱')) > 0:
變數名 = news.select('.類名稱/標籤名')[0].text
print(變數名)
相關推薦
python爬蟲【二】爬取新聞
在一個新聞站點或者絢麗的網頁會有許多id和class 我們可以通過觀察來看到我們需要的資訊在那些id和class下 但是這裡介紹兩種快速便捷的方法 第一種使用谷歌瀏覽器自帶的開發者工具 或者安裝infolite外掛安裝方法看這篇https:/
python爬蟲【一】爬取文字
我們在安裝py是建議如果使用windows不要安裝原生的py因為windows的c編譯器原因會使某些套件安裝起來有麻煩 也就是安裝anaconda版本的pyhttps://www.anaconda.com/download/#windows py官網下載的是原生版本https://www
python爬蟲【例項】爬取豆瓣電影評分連結並圖示()-問題如何爬取電影圖片(解決有程式碼)
這裡只有尾巴,來分析一下確定範圍:如何爬取圖片並下載?參考:http://blog.csdn.net/chaoren666/article/details/53488083----------------------------------------------------
【python爬蟲自學筆記】-----爬取網易雲歌單中歌曲歌詞
工具:python3.6 ,pycharm 開始對網頁的內容進行爬取的時候,使用requests獲得響應,只傳url,但是沒有獲得響應,使用urllib新增請求頭部,並對response的內容使用utf-8進行解碼,使用BeautifulSoup轉換為html物件,
python爬蟲十二:爬取快速ip代理,攻破503
轉:https://zhuanlan.zhihu.com/p/26701898 1.自定爬蟲方法 # -*- coding: utf-8 -*- import scrapy import requests from proxy.items import ProxyItem
Python開發簡單爬蟲(二)---爬取百度百科頁面數據
class 實例 實例代碼 編碼 mat 分享 aik logs title 一、開發爬蟲的步驟 1.確定目標抓取策略: 打開目標頁面,通過右鍵審查元素確定網頁的url格式、數據格式、和網頁編碼形式。 ①先看url的格式, F12觀察一下鏈接的形式;② 再看目標文本信息的
【爬蟲入門5】爬取酷狗TOP500
#coding utf-8 import time import requests from bs4 import BeautifulSoup class spider_KG_top500(object): def __init__(self):
python網路爬蟲學習(二)一個爬取百度貼吧的爬蟲程式
今天進一步學習了python網路爬蟲的知識,學會了寫一個簡單的爬蟲程式,用於爬取百度貼吧的網頁並儲存為HTML檔案。下面對我在實現這個功能時的程式碼以及所遇到的問題的記錄總結和反思。 首先分析實現這個功能的具體思路: 通過對貼吧URL的觀察,可以看出貼吧中的
【爬蟲入門】【非同步】爬取人人車車輛資訊1.0
# 爬取人人車車車輛資訊。 # 多執行緒/多程序:提高程式碼的執行效率,放在爬蟲中就是提高爬取效率。因為可以使用多個程序同時對多個頁面發起請求。 # 之前的糗事百科/51job同步執行:按照先後順序一個一個執行。 from urllib.request import urlopen from ur
【爬蟲入門】【同步】爬取人人車車輛資訊1.0
# 爬取人人車車車輛資訊。 from urllib.request import urlopen from urllib.error import HTTPError import re, sqlite3 class RRCSpider(object): """ 人人車爬蟲類
【爬蟲入門】【正則表示式】【非同步】爬取人人車車輛資訊1.0
# 爬取人人車車車輛資訊。 # 多執行緒/多程序:提高程式碼的執行效率,放在爬蟲中就是提高爬取效率。因為可以使用多個程序同時對多個頁面發起請求。 # 之前的糗事百科/51job同步執行:按照先後順序一個一個執行。 from urllib.request import urlopen from ur
【爬蟲入門】【正則表示式】【同步】爬取人人車車輛資訊1.0
# 爬取人人車車車輛資訊。 from urllib.request import urlopen from urllib.error import HTTPError import re, sqlite3 class RRCSpider(object): """ 人人車爬蟲類
【爬蟲入門】【Json】爬取智聯招聘
爬蟲中也會經常會遇到以JSON資料返回內容的網站,這種網站不再需要使用正則表示式匹配文字,直接分析網站是否含有介面返回JSON,如果有,直接使用json.load()對json字串進行解析就可以獲取資料。 # pip install requests:比較流行的第三方請求庫 #https
【Python還能幹嘛】爬取微信好友頭像完成馬賽克拼圖(千圖成像)~
馬賽克拼圖 何謂馬賽克拼圖(千圖成像),簡單來說就是將若干小圖片平湊成為一張大圖,如下圖路飛一樣,如果放大看你會發現裡面都是一些海賊王裡面的圖片。 Our Tragets 爬取所有微信好友的頭像
Python爬蟲之利用BeautifulSoup爬取豆瓣小說(三)——將小說信息寫入文件
設置 one 行為 blog 應該 += html uil rate 1 #-*-coding:utf-8-*- 2 import urllib2 3 from bs4 import BeautifulSoup 4 5 class dbxs: 6 7
爬蟲任務二:爬取(用到htmlunit和jsoup)通過百度搜索引擎關鍵字搜取到的新聞標題和url,並保存在本地文件中(主體借鑒了網上的資料)
標題 code rgs aps snap one reader url 預處理 采用maven工程,免著到處找依賴jar包 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http:
Python爬蟲【五】Scrapy分布式原理筆記
啟動 size inf p s 集合 內存 運行 請求 max Scrapy單機架構 在這裏scrapy的核心是scrapy引擎,它通過裏面的一個調度器來調度一個request的隊列,將request發給downloader,然後來執行request請求 但是這些requ
Python爬蟲系列 - 初探:爬取旅遊評論
blank .text http fir win64 ati coo get stat Python爬蟲目前是基於requests包,下面是該包的文檔,查一些資料還是比較方便。 http://docs.python-requests.org/en/master/ 爬取某旅遊
Python 爬蟲簡單實現 (爬取下載連結)
原文地址:https://www.jianshu.com/p/8fb5bc33c78e 專案地址:https://github.com/Kulbear/All-IT-eBooks-Spider 這幾日和朋友搜尋東西的
Python 爬蟲技巧1 | 將爬取網頁中的相對路徑轉換為絕對路徑
1.背景: 在爬取網頁中的過程中,我對目前爬蟲專案後端指令碼中拼接得到絕對路徑的方法很不滿意,今天很無意瞭解到在python3 的 urllib.parse模組對這個問題有著非常完善的解決策略,真的是上天有眼,感動! 2.urllib.parse模組 This module define