
Word2vec原理與應用
用一個普通的向量表示一個詞,將所有這些向量放在一起形成一個詞向量空間,而每一向量則為該空間中的一個點,在這個空間上的詞向量之間的距離度量也可以表示對應的兩個詞之間的“距離”。所謂兩個詞之間的“距離”,就是這兩個詞之間的語法,語義之間的相似性。
只介紹基於Hierarchical Softmax的CBOW模型,其他模型參考文章的參考連結。
原理
語言模型的目標函式
一般為對數似然函式 C為所有語料 針對所有語料進行極大似然

預測函式
訓練過程中所有詞全部生成,輸入詞(語料庫已有)查詢出結果即可。
p(w|Context(w))
模型學習
基於Hierarchical Softmax的CBOW模型
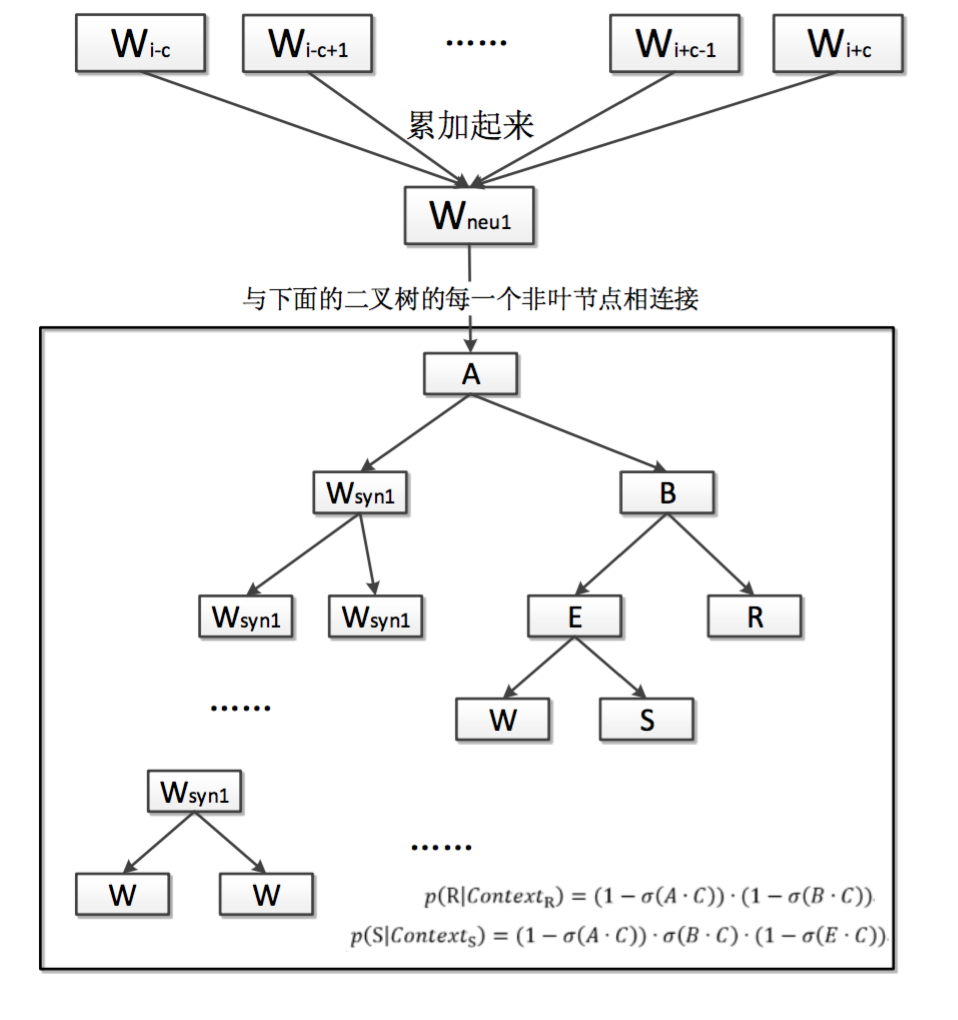
輸入層:上下文詞向量
隱藏層:詞向量的累加和
輸出層:Huffman樹(根據所有語料頻數構建),葉子節點代表語料庫中的詞,每次分支看做二分類,往左負類,往右正類。
label=1-huffman編碼(d)
梯度計算:
一個節點被分為正類的概率:
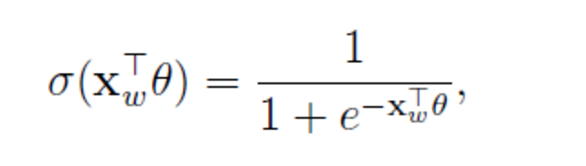
sigmoid函式
負類的概率:
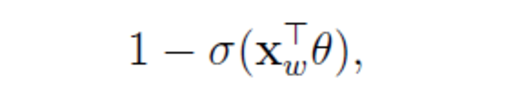
對於詞典中D中的任意詞w,Huffman樹必存在一條從根節點到詞的路徑,每次分支為一次二分類,每一次分類就產生一個概率,
這些概率連乘 就是p(w|Context(w))

目標函式變為:
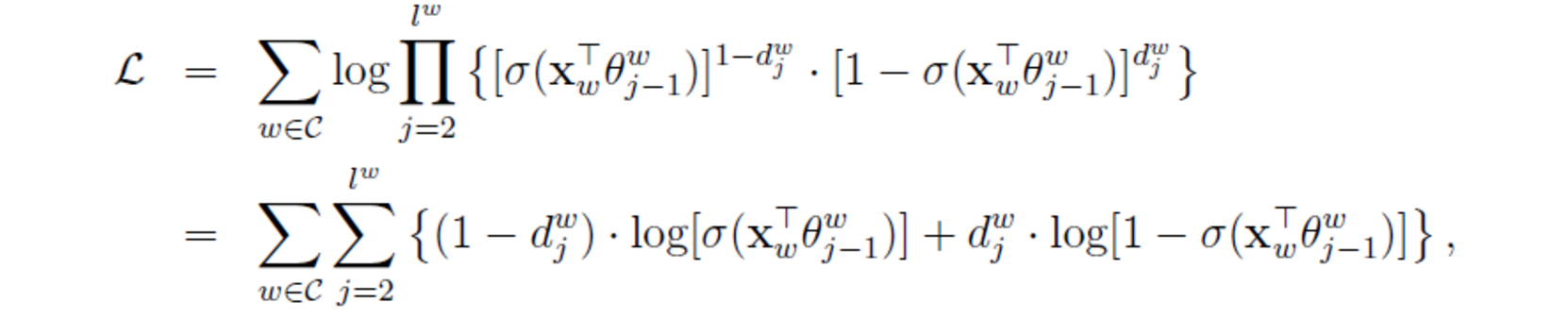
為了推導方便上面花括號裡內容記為L(w,j)
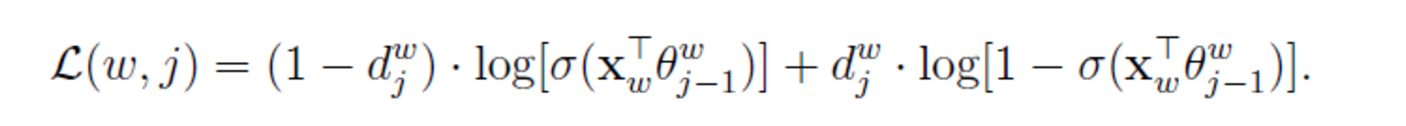
訓練過程:
每一個樣本(w,Context(w)) 更新一次引數
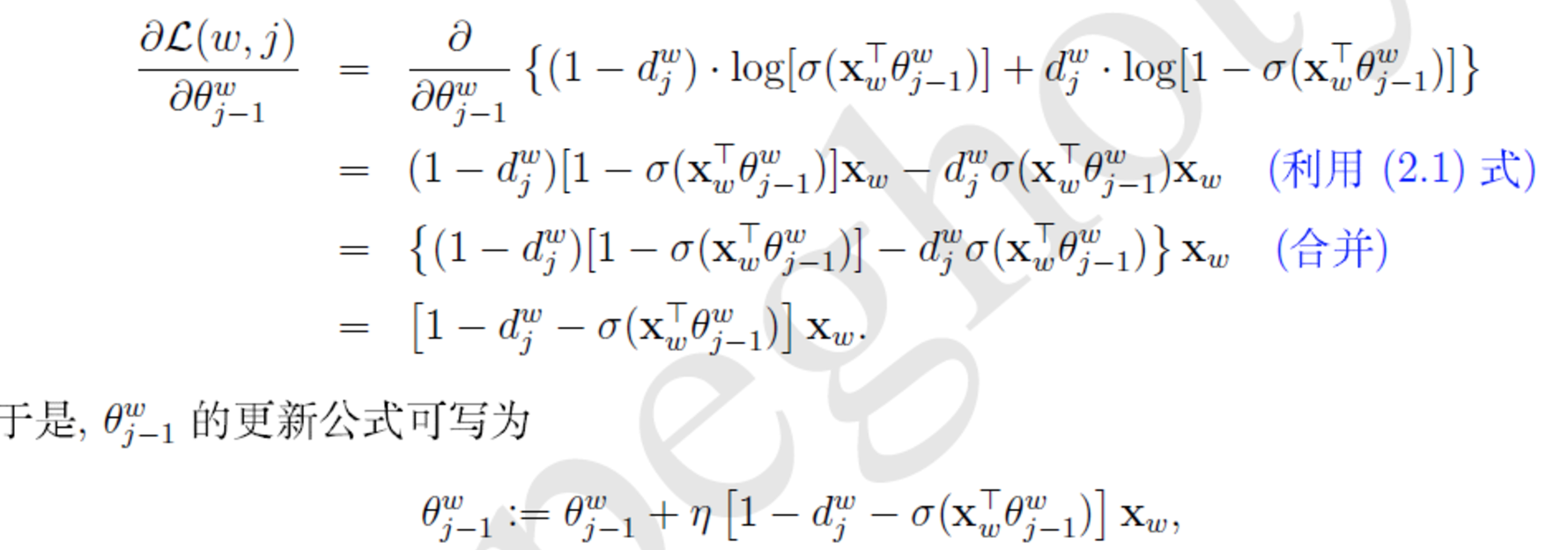

w詞向量更新
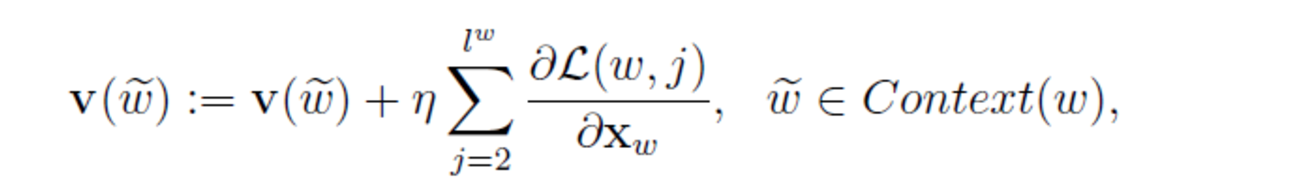
虛擬碼:

python程式碼實踐
安裝
pip install –upgrade gensim
或者
easy_install -U gensim
初始化語料庫
(每行格式是詞以空格分割)
使用維基百科中文語料庫:中英文維基百科語料上的word2vec實驗
讀入多檔案每行內容:
例如,如果我們的輸入散佈在磁碟上的多個檔案中,每行一個句子,那麼不是將所有內容都載入到記憶體列表中,我們可以逐行處理輸入檔案。(讀入多檔案每行內容)
class MySentences(object):
def __init__(self, dirname) 訓練語料庫
常見引數預設size=100, window=5, min_count=5
min_count是在0-100之間,這取決於你的資料集的大小,忽略出現次數少於多少的無意義的詞。
window:是詞向量訓練時的上下文掃描視窗大小,視窗為5就是考慮前5個詞和後5個詞;
size是每個詞的向量維度;較大的size值需要更多的訓練資料,但可以導致更好(更準確)的模型。
workers 程序數用於訓練並行化 預設1無並行化
import logging
##設定log日誌格式: 時間:級別:訊息 級別是INFO以上輸出
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
run='test'
##拼接字串 %s代替變數 後面%跟上變數
logging.info("running %s began %s "%(run,'!'))
##模型訓練
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
##設定訓練例項格式 每行一個list陣列
sentences = [['first', 'sentence'], ['second', 'sentence']]
#model = Word2Vec(sentences, size=100, window=5, min_count=5, workers=4)
model = Word2Vec(sentences, size=10, window=5, min_count=0, workers=4)從檔案中讀取
from gensim import Word2Vec
from gensim.Word2Vec import LineSentence
# inp為輸入語料
inp = 'demo.txt'
model = Word2Vec(LineSentence(inp), size=100, window=5, min_count=1, workers=4)儲存和載入模型
model.save('./mymodel')
model = Word2Vec.load('./mymodel')檢視單個詞向量
model.wv['second']
#or 中文model[u'汽車']
model['second']增量訓練模型
model.train(more_sentences)
##model.train(LineSentence(more_inp))計算兩詞之間的餘弦相似度
##輸出相似的topn
model.most_similar(positive=['first', 'second'], negative=['sentence'], topn=1)
##查詢語料庫有的詞彙 ?
model.doesnt_match("breakfast first dinner lunch".split())
##計算兩個詞的餘弦相似度
model.similarity('first', 'second')計算一個詞的最近似的詞,倒排序
#word.decode('utf-8')most_similar(word.decode('utf-8'), topn=topN)
result = model.most_similar(u'足球')
for each in result:
print each[0] , each[1]計算兩個集合之間的餘弦似度
當出現某個詞語不在這個訓練集合中的時候,會報錯!
list1 = [u'今天', u'我', u'很', u'開心']
list2 = [u'空氣',u'清新', u'善良', u'開心']
list_sim1 = model.n_similarity(list1, list2)整合
# coding: utf-8
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import logging
##設定log日誌格式: 時間:級別:訊息 級別是INFO以上輸出
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
run='test'
##拼接字串 %s代替變數 後面%跟上變數
logging.info("running %s began %s "%(run,'!'))
inp = 'demo.txt'
model = Word2Vec(LineSentence(inp), size=100, window=5, min_count=1, workers=4)
# model.save('./mymodel')
# model = Word2Vec.load('./mymodel')
print model[u'弓箭']
print model.similarity(u'弓箭', u'櫻花樹')
print model.doesnt_match(u"亞特蘭 櫻花樹 小布".split())
result = model.most_similar(u'櫻花樹')
for each in result:
print each[0] , each[1]
result = model.most_similar(positive=[u'櫻花樹', u'鐵環'], negative=[u'亞特蘭'], topn=5)
for each in result:
print each[0] , each[1]
list1 = [u'鐵環', u'櫻花樹', u'熱門貨', u'轉學']
list2 = [u'鐵環',u'櫻花樹', u'弓箭', u'英雄主義']
list_sim1 = model.n_similarity(list1, list2)
print list_sim1Doc2Vec
import gensim, logging
import os
logging.basicConfig(format = '%(asctime)s : %(levelname)s : %(message)s', level = logging.INFO)
sentences = gensim.models.doc2vec.TaggedLineDocument('review_pure_text.txt')
model = gensim.models.Doc2Vec(sentences, size = 100, window = 5)
model.save('review_pure_text_model.txt')
print len(model.docvecs)
out = file('review_pure_text_vector.txt', 'w')
for idx, docvec in enumerate(model.docvecs):
for value in docvec:
out.write(str(value) + ' ')
out.write('\n')
print idx
print docvec
out.close()輸入檔案Tweets_id_text.txt的格式就是每個doc 對應內容的分詞,空格隔開,每個doc是一行
用TaggedLineDocument 實現,每個doc預設編號