
equals()和HashCode()深入理解以及Hash演算法原理
1.深入理解equals():
- 在我的一篇部落格“==”和.equals()的區別中向讀者提出提醒: Object類中的equals方法和“==”是一樣的,沒有區別,即倆個物件的比較是比較他們的棧記憶體中儲存的記憶體地址。而String類,Integer類等等一些類,是重寫了equals方法,才使得equals和“==不同”,他們比較的是值是不是相等。所以,當自己建立類時,自動繼承了Object的equals方法,要想實現不同的等於比較,必須重寫equals方法。
- 我們看下面這個例子:
package cn.galc.test;
public class TestEquals {
public - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
畫出記憶體分析圖分析c1和c2比較的結果,當執行Cat c1 = new Cat(1,1,1); Cat c2 = new Cat(1,1,1); 之後記憶體之中佈局如下圖:
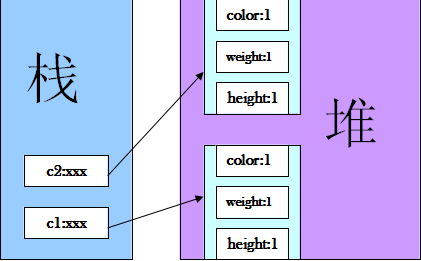
- 由此我們看出,當我們new一個物件時,將在記憶體里加載一份它自己的記憶體,而不是共用!對於static修飾的變數和方法則儲存在方法區中,只加載一次,不會再多copy一份記憶體。
- 所以我們在判斷倆個物件邏輯上是否相等,即物件的內容是否相等不能直接使用繼承於Object類的equals()方法,我們必須得重寫equals()方法,改變這個方法預設的實現。下面在Cat類裡面重寫這個繼承下來的equals()方法:
class Cat {
int color, weight, height;
public Cat(int color, int weight, int height) {
this.color = color;
this.weight = weight;
this.height = height;
}
/**
* 這裡是重寫相等從Object類繼承下來的equals()方法,改變這個方法預設的實現,
* 通過我們自己定義的實現來判斷決定兩個物件在邏輯上是否相等。
* 這裡我們定義如果兩隻貓的color,weight,height都相同,
* 那麼我們就認為這兩隻貓在邏輯上是一模一樣的,即這兩隻貓是“相等”的。
*/
public boolean equals(Object obj){
if (obj==null){
return false;
}
else{
/**
* instanceof是物件運算子。
* 物件運算子用來測定一個物件是否屬於某個指定類或指定的子類的例項。
* 如果左邊的物件是右邊的類建立的物件,則運算結果為true,否則為false。
*/
if (obj instanceof Cat){
Cat c = (Cat)obj;
if (c.color==this.color && c.weight==this.weight && c.height==this.height){
return true;
}
}
}
return false;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 設計思路很簡單:先判斷比較物件是否為null—>判斷比較物件是否為要比較類的例項—–>比較倆個成員變數是否完全相等。
//另外一種常用重寫方法
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null) return false;
if (getClass() != obj.getClass()) return false;
People other = (People) obj;
if (age != other.age) return false;
if (firstName == null) {
if (other.firstName != null) return false;
} else if (!firstName.equals(other.firstName)) return false;
if (lastName == null) {
if (other.lastName != null) return false;
} else if (!lastName.equals(other.lastName)) return false;
return true;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 這樣通過在類中重寫equals()方法,我們可以比較在同一個類下不同物件是否相等了。
2.Hash演算法原理以及HashCode深入理解
- Java中的Collection有兩類,一類是List,一類是Set。List內的元素是有序的,元素可以重複。Set元素無序,但元素不可重複。要想保證元素不重複,兩個元素是否重複應該依據什麼來判斷呢?用Object.equals方法。但若每增加一個元素就檢查一次,那麼當元素很多時,後新增到集合中的元素比較的次數就非常多了。也就是說若集合中已有1000個元素,那麼第1001個元素加入集合時,它就要呼叫1000次equals方法。這顯然會大大降低效率。於是Java採用了雜湊表的原理。
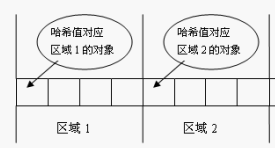
- 當Set接收一個元素時根據該物件的記憶體地址算出hashCode,看它屬於哪一個區間,再這個區間裡呼叫equeals方法。【特別注意】這裡需要注意的是:當倆個物件的hashCode值相同的時候,Hashset會將物件儲存在同一個位置,但是他們equals返回false,所以實際上這個位置採用鏈式結構來儲存多個物件。
-
上面方法確實提高了效率。但一個面臨問題:若兩個物件equals相等,但不在一個區間,因為hashCode的值在重寫之前是對記憶體地址計算得出,所以根本沒有機會進行比較,會被認為是不同的物件。所以Java對於eqauls方法和hashCode方法是這樣規定的:
1 如果兩個物件相同,那麼它們的hashCode值一定要相同。也告訴我們重寫equals方法,一定要重寫hashCode方法,也就是說hashCode值要和類中的成員變數掛上鉤,物件相同–>成員變數相同—->hashCode值一定相同。
2 如果兩個物件的hashCode相同,它們並不一定相同,這裡的物件相同指的是用eqauls方法比較。 -
下面來看一下一個具體的例子: RectObject物件:
package com.weijia.demo;
public class RectObject {
public int x;
public int y;
public RectObject(int x,int y){
this.x = x;
this.y = y;
}
@Override
public int hashCode(){
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj){
if(this == obj)
return true;
if(obj == null)
return false;
if(getClass() != obj.getClass())
return false;
final RectObject other = (RectObject)obj;
if(x != other.x){
return false;
}
if(y != other.y){
return false;
}
return true;
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 我們重寫了父類Object中的hashCode和equals方法,看到hashCode和equals方法中,如果兩個RectObject物件的x,y值相等的話他們的hashCode值是相等的,同時equals返回的是true;
下面是測試程式碼:
package com.weijia.demo;
import java.util.HashSet;
public class Demo {
public static void main(String[] args){
HashSet<RectObject> set = new HashSet<RectObject>();
RectObject r1 = new RectObject(3,3);
RectObject r2 = new RectObject(5,5);
RectObject r3 = new RectObject(3,3);
set.add(r1);
set.add(r2);
set.add(r3);
set.add(r1);
System.out.println("size:"+set.size());
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
我們向HashSet中存入到了四個物件,列印set集合的大小,結果是多少呢? 執行結果:size:2
為什麼會是2呢?這個很簡單了吧,因為我們重寫了RectObject類的hashCode方法,只要RectObject物件的x,y屬性值相等那麼他的hashCode值也是相等的,所以先比較hashCode的值,r1和r2物件的x,y屬性值不等,所以他們的hashCode不相同的,所以r2物件可以放進去,但是r3物件的x,y屬性值和r1物件的屬性值相同的,所以hashCode是相等的,這時候在比較r1和r3的equals方法,因為他麼兩的x,y值是相等的,所以r1,r3物件是相等的,所以r3不能放進去了,同樣最後再新增一個r1也是沒有沒有新增進去的,所以set集合中只有一個r1和r2這兩個物件下面我們把RectObject物件中的hashCode方法註釋,即不重寫Object物件中的hashCode方法,在執行一下程式碼:
執行結果:size:3
這個結果也是很簡單的,首先判斷r1物件和r2物件的hashCode,因為Object中的hashCode方法返回的是物件本地記憶體地址的換算結果,不同的例項物件的hashCode是不相同的,同樣因為r3和r1的hashCode也是不相等的,但是r1==r1的,所以最後set集合中只有r1,r2,r3這三個物件,所以大小是3下面我們把RectObject物件中的equals方法中的內容註釋,直接返回false,不註釋hashCode方法,執行一下程式碼:
執行結果:size:3 這個結果就有點意外了,我們來分析一下:
首先r1和r2的物件比較hashCode,不相等,所以r2放進set中,再來看一下r3,比較r1和r3的hashCode方法,是相等的,然後比較他們兩的equals方法,因為equals方法始終返回false,所以r1和r3也是不相等的,r3和r2就不用說了,他們兩的hashCode是不相等的,所以r3放進set中,再看r4,比較r1和r4發現hashCode是相等的,在比較equals方法,因為equals返回false,所以r1和r4不相等,同一r2和r4也是不相等的,r3和r4也是不相等的,所以r4可以放到set集合中,那麼結果應該是size:4,那為什麼會是3呢?
這時候我們就需要檢視HashSet的原始碼了,下面是HashSet中的add方法的原始碼:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 這裡我們可以看到其實HashSet是基於HashMap實現的,我們在點選HashMap的put方法,原始碼如下:
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
我們主要來看一下if的判斷條件,
首先是判斷hashCode是否相等,不相等的話,直接跳過,相等的話,然後再來比較這兩個物件是否相等或者這兩個物件的equals方法,因為是進行的或操作,所以只要有一個成立即可,那這裡我們就可以解釋了,其實上面的那個集合的大小是3,因為最後的一個r1沒有放進去,以為r1==r1返回true的,所以沒有放進去了。所以集合的大小是3,如果我們將hashCode方法設定成始終返回false的話,這個集合就是4了。
最後我們在來看一下hashCode造成的記憶體洩露的問題:看一下程式碼:
package com.weijia.demo;
import java.util.HashSet;
public class Demo {
public static void main(String[] args){
HashSet<RectObject> set = new HashSet<RectObject>();
RectObject r1 = new RectObject(3,3);
RectObject r2 = new RectObject(5,5);
RectObject r3 = new RectObject(3,3);
set.add(r1);
set.add(r2);
set.add(r3);
r3.y = 7;
System.out.println("刪除前的大小size:"+set.size());
set.remove(r3);
System.out.println("刪除後的大小size:"+set.size());
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 執行結果:
刪除前的大小size:3
刪除後的大小size:3
擦,發現一個問題了,而且是個大問題呀,我們呼叫了remove刪除r3物件,以為刪除了r3,但事實上並沒有刪除,這就叫做記憶體洩露,就是不用的物件但是他還在記憶體中。所以我們多次這樣操作之後,記憶體就爆了。看一下remove的原始碼:
/**
* Removes the specified element from this set if it is present.
* More formally, removes an element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>,
* if this set contains such an element. Returns <tt>true</tt> if
* this set contained the element (or equivalently, if this set
* changed as a result of the call). (This set will not contain the
* element once the call returns.)
*
* @param o object to be removed from this set, if present
* @return <tt>true</tt> if the set contained the specified element
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 然後再看一下remove方法的原始碼:
/**
* Removes the mapping for the specified key from this map if present.
*
* @param key key whose mapping is to be removed from the map
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 在看一下removeEntryForKey方法原始碼:
/**
* Removes and returns the entry associated with the specified key
* in the HashMap. Returns null if the HashMap contains no mapping
* for this key.
*/
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 我們看到,在呼叫remove方法的時候,會先使用物件的hashCode值去找到這個物件,然後進行刪除,這種問題就是因為我們在修改了r3物件的y屬性的值,又因為RectObject物件的hashCode方法中有y值參與運算,所以r3物件的hashCode就發生改變了,所以remove方法中並沒有找到r3了,所以刪除失敗。即r3的hashCode變了,但是他儲存的位置沒有更新,仍然在原來的位置上,所以當我們用他的新的hashCode去找肯定是找不到了。
上面的這個記憶體洩露告訴我一個資訊:如果我們將物件的屬性值參與了hashCode的運算中,在進行刪除的時候,就不能對其屬性值進行修改,否則會出現嚴重的問題。