
RAID和LVM磁碟陣列
RAID磁碟冗餘陣列
CPU的處理效能保持著高速增長,Intel公司在2017年最新發布的i9-7980XE處理器晶片更是達到了18核心36執行緒。但與此同時,硬碟裝置的效能提升卻不是很大,因此逐漸成為當代計算機整體效能的瓶頸。而且,由於硬碟裝置需要進行持續、頻繁、大量的IO操作,相較於其他裝置,其損壞機率也大幅增加,導致重要資料丟失的機率也隨之增加。
1988年,加利福尼亞大學伯克利分校首次提出並定義了RAID技術的概念。RAID技術通過把多個硬碟裝置組合成一個容量更大、安全性更好的磁碟陣列,並把資料切割成多個區段後分別存放在各個不同的物理硬碟裝置上,然後利用分散讀寫技術來提升磁碟陣列整體的效能,同時把多個重要資料的副本同步到不同的物理硬碟裝置上,從而起到了非常好的資料冗餘備份效果。
任何事物都有它的兩面性。RAID技術確實具有非常好的資料冗餘備份功能,但是它也相應地提高了成本支出。就像原本我們只有一個電話本,但是為了避免遺失,我們將聯絡人號碼資訊寫成了兩份,自然要為此多買一個電話本,這也就相應地提升了成本支出。RAID技術的設計初衷是減少因為採購硬碟裝置帶來的費用支出,但是與資料本身的價值相比較,現代企業更看重的則是RAID技術所具備的冗餘備份機制以及帶來的硬碟吞吐量的提升。也就是說,RAID不僅降低了硬碟裝置損壞後丟失資料的機率,還提升了硬碟裝置的讀寫速度,所以它在絕大多數運營商或大中型企業中得以廣泛部署和應用。
出於成本和技術方面的考慮,需要針對不同的需求在資料可靠性及讀寫效能上作出權衡,制定出滿足各自需求的不同方案。目前已有的RAID磁碟陣列的方案至少有十幾種,接下來會詳細寫RAID 0、RAID 1、RAID 5與RAID 10這4種最常見的方案。
1. RAID 0
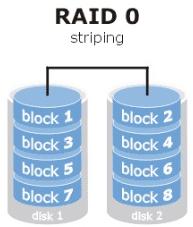
RAID 0技術把多塊物理硬碟裝置(至少兩塊)通過硬體或軟體的方式串聯在一起,組成一個大的卷組,並將資料依次寫入到各個物理硬碟中。這樣一來,在最理想的狀態下,硬碟裝置的讀寫效能會提升數倍,但是若任意一塊硬碟發生故障將導致整個系統的資料都受到破壞。通俗來說,RAID 0技術能夠有效地提升硬碟資料的吞吐速度,但是不具備資料備份和錯誤修復能力。如圖7-1所示,資料被分別寫入到不同的硬碟裝置中,即disk1和disk2硬碟裝置會分別儲存資料資料,最終實現提升讀取、寫入速度的效果。
2. RAID 1
儘管RAID 0技術提升了硬碟裝置的讀寫速度,但是它是將資料依次寫入到各個物理硬碟中,也就是說,它的資料是分開存放的,其中任何一塊硬碟發生故障都會損壞整個系統的資料。因此,如果生產環境對硬碟裝置的讀寫速度沒有要求,而是希望增加資料的安全性時,就需要用到RAID 1技術了。
在圖7-2所示的RAID 1技術示意圖中可以看到,它是把兩塊以上的硬碟裝置進行繫結,在寫入資料時,是將資料同時寫入到多塊硬碟裝置上(可以將其視為資料的映象或備份)。當其中某一塊硬碟發生故障後,一般會立即自動以熱交換的方式來恢復資料的正常使用。
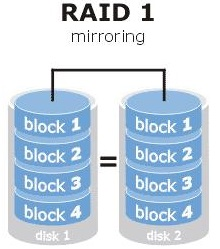
RAID 1技術雖然十分注重資料的安全性,但是因為是在多塊硬碟裝置中寫入了相同的資料,因此硬碟裝置的利用率得以下降,從理論上來說,圖7-2所示的硬碟空間的真實可用率只有50%,由三塊硬碟裝置組成的RAID 1磁碟陣列的可用率只有33%左右,以此類推。而且,由於需要把資料同時寫入到兩塊以上的硬碟裝置,這無疑也在一定程度上增大了系統計算功能的負載。
那麼,有沒有一種RAID方案既考慮到了硬碟裝置的讀寫速度和資料安全性,還兼顧了成本問題呢?實際上,單從資料安全和成本問題上來講,就不可能在保持原有硬碟裝置的利用率且還不增加新裝置的情況下,能大幅提升資料的安全性。下面將要講解的RAID 5技術雖然在理論上兼顧了三者(讀寫速度、資料安全性、成本),但實際上更像是對這三者的“相互妥協”。
3. RAID 5
如圖7-3所示,RAID5技術是把硬碟裝置的資料奇偶校驗資訊儲存到其他硬碟裝置中。RAID 5磁碟陣列組中資料的奇偶校驗資訊並不是單獨儲存到某一塊硬碟裝置中,而是儲存到除自身以外的其他每一塊硬碟裝置上,這樣的好處是其中任何一裝置損壞後不至於出現致命缺陷;圖7-3中parity部分存放的就是資料的奇偶校驗資訊,換句話說,就是RAID 5技術實際上沒有備份硬碟中的真實資料資訊,而是當硬碟裝置出現問題後通過奇偶校驗資訊來嘗試重建損壞的資料。RAID這樣的技術特性“妥協”地兼顧了硬碟裝置的讀寫速度、資料安全性與儲存成本問題。

4. RAID 10
鑑於RAID 5技術是因為硬碟裝置的成本問題對讀寫速度和資料的安全效能而有了一定的妥協,但是大部分企業更在乎的是資料本身的價值而非硬碟價格,因此生產環境中主要使用RAID 10技術。
顧名思義,RAID 10技術是RAID 1+RAID 0技術的一個“組合體”。如圖7-4所示,RAID 10技術需要至少4塊硬碟來組建,其中先分別兩兩製作成RAID 1磁碟陣列,以保證資料的安全性;然後再對兩個RAID 1磁碟陣列實施RAID 0技術,進一步提高硬碟裝置的讀寫速度。這樣從理論上來講,只要壞的不是同一組中的所有硬碟,那麼最多可以損壞50%的硬碟裝置而不丟失資料。由於RAID 10技術繼承了RAID 0的高讀寫速度和RAID 1的資料安全性,在不考慮成本的情況下RAID 10的效能都超過了RAID 5,因此當前成為廣泛使用的一種儲存技術。

部署磁碟陣列
虛擬機器中新增4塊硬碟裝置來製作一個RAID 10磁碟陣列

關閉系統之後,再在虛擬機器中新增硬碟裝置,否則可能會因為計算機架構的不同而導致虛擬機器系統無法識別新增的硬碟裝置。
mdadm命令用於管理Linux系統中的軟體RAID硬碟陣列,格式為“mdadm [模式] <RAID裝置名稱> [選項] [成員裝置名稱]”。
當前,生產環境中用到的伺服器一般都配備RAID陣列卡,儘管伺服器的價格越來越便宜,但是我們沒有必要為了做一個實驗而去單獨購買一臺伺服器,而是可以學會用mdadm命令在Linux系統中建立和管理軟體RAID磁碟陣列,而且它涉及的理論知識的操作過程與生產環境中的完全一致。mdadm命令的常用引數以及作用如表所示。
mdadm命令的常用引數和作用
| 引數 | 作用 |
| -a | 檢測裝置名稱 |
| -n | 指定裝置數量 |
| -l | 指定RAID級別 |
| -C | 建立 |
| -v | 顯示過程 |
| -f | 模擬裝置損壞 |
| -r | 移除裝置 |
| -Q | 檢視摘要資訊 |
| -D | 檢視詳細資訊 |
| -S | 停止RAID磁碟陣列 |
接下來,使用mdadm命令建立RAID 10,名稱為“/dev/md0”。
udev是Linux系統核心中用來給硬體命名的服務,其命名規則也非常簡單。我們可以通過命名規則猜測到第二個SCSI儲存裝置的名稱會是/dev/sdb,然後依此類推。使用硬碟裝置來部署RAID磁碟陣列很像是將幾位同學組成一個班級,但總不能將班級命名為/dev/sdbcde吧。儘管這樣可以一眼看出它是由哪些元素組成的,但是並不利於我們的記憶和閱讀。更何況如果我們是使用10、50、100個硬碟來部署RAID磁碟陣列呢?
此時,就需要使用mdadm中的引數了。其中,-C引數代表建立一個RAID陣列卡;-v引數顯示建立的過程,同時在後面追加一個裝置名稱/dev/md0,這樣/dev/md0就是建立後的RAID磁碟陣列的名稱;-a yes引數代表自動建立裝置檔案;-n 4引數代表使用4塊硬碟來部署這個RAID磁碟陣列;而-l 10引數則代表RAID 10方案;最後再加上4塊硬碟裝置的名稱就搞定了。
[[email protected]172-0-190-33 ~]# mdadm -Cv /dev/md0 -a yes -n 5 -l 10 /dev/sd /dev/sdc /dev/sdd /dev/sde /dev/sdf mdadm: layout defaults to n2 mdadm: layout defaults to n2 mdadm: chunk size defaults to 512K mdadm: size set to 8379392K mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.
其次,把製作好的RAID磁碟陣列格式化為ext4格式:
[[email protected]172-0-190-33 ~]# mkfs.ext4 /dev/md0 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=128 blocks, Stripe width=640 blocks 1310720 inodes, 5237120 blocks 261856 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2153775104 160 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 160562, 2654208, 4096000 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done
再次,建立掛載點然後把硬碟裝置進行掛載操作。掛載成功後可看到可用空間為20GB。
[[email protected]172-0-190-33 ~]# mkdir /RAID [[email protected]172-0-190-33 ~]# mount /dev/md0 /RAID [[email protected]172-0-190-33 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda6 22G 1.4G 20G 7% / devtmpfs 909M 0 909M 0% /dev tmpfs 920M 0 920M 0% /dev/shm tmpfs 920M 8.6M 911M 1% /run tmpfs 920M 0 920M 0% /sys/fs/cgroup /dev/sda3 13G 225M 13G 2% /var /dev/sda2 15G 33M 15G 1% /home /dev/sda1 197M 137M 61M 70% /boot tmpfs 184M 0 184M 0% /run/user/0 /dev/md0 20G 45M 19G 1% /RAID
最後,檢視/dev/md0磁碟陣列的詳細資訊,並把掛載資訊寫入到配置檔案中,使其永久生效。
[[email protected]172-0-190-33 ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Thu Dec 27 02:31:18 2018 Raid Level : raid10 Array Size : 20948480 (19.98 GiB 21.45 GB) Used Dev Size : 8379392 (7.99 GiB 8.58 GB) Raid Devices : 5 Total Devices : 5 Persistence : Superblock is persistent Update Time : Thu Dec 27 02:34:01 2018 State : clean Active Devices : 5 Working Devices : 5 Failed Devices : 0 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Name : 0 UUID : 7ad6d007:6905175f:bf75f342:fa448011 Events : 19 Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf
[[email protected] ~]# echo "/dev/md0 /RAID exit4 defaults 0 0" >> /etc/fstab
損壞磁碟陣列及修復
之所以在生產環境中部署RAID 10磁碟陣列,是為了提高硬碟儲存裝置的讀寫速度及資料的安全性,但由於我們的硬碟裝置是在虛擬機器中模擬出來的,因此對讀寫速度的改善可能並不直觀。所以寫下RAID磁碟陣列損壞後的處理方法。
在確認有一塊物理硬碟裝置出現損壞而不能繼續正常使用後,應該使用mdadm命令將其移除,然後檢視RAID磁碟陣列的狀態,可以發現狀態已經改變。
咱們在生產環境中部署RAID10磁碟陣列組目的就是為了提高儲存裝置的IO讀寫速度及資料的安全性,但因為這次是在本機電腦上模擬出來的硬碟裝置所以對於讀寫速度的改善可能並不直觀,所以加上RAID磁碟陣列組損壞後的處理方法,這樣以後步入了運維崗位後不會因為突發事件而手忙腳亂。首先確認有一塊物理硬碟裝置出現損壞不能再繼續正常使用後,模擬兩塊磁碟損壞:
[[email protected]172-0-190-33 ~]# mdadm /dev/md0 -f /dev/sdb mdadm: set /dev/sdb faulty in /dev/md0 [[email protected]172-0-190-33 ~]# mdadm /dev/md0 -f /dev/sdd mdadm: set /dev/sdd faulty in /dev/md0
使用mdadm命令來予以移除之後檢視下RAID磁碟陣列組的狀態已經被改變:
[[email protected]172-0-190-33 ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Thu Dec 27 02:31:18 2018 Raid Level : raid10 Array Size : 20948480 (19.98 GiB 21.45 GB) Used Dev Size : 8379392 (7.99 GiB 8.58 GB) Raid Devices : 5 Total Devices : 5 Persistence : Superblock is persistent Update Time : Thu Dec 27 03:03:42 2018 State : clean, degraded Active Devices : 3 Working Devices : 3 Failed Devices : 2 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Consistency Policy : resync Name : 0 UUID : 7ad6d007:6905175f:bf75f342:fa448011 Events : 23 Number Major Minor RaidDevice State - 0 0 0 removed 1 8 32 1 active sync /dev/sdc - 0 0 2 removed 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 0 8 16 - faulty /dev/sdb 2 8 48 - faulty /dev/sdd
在RAID 10級別的磁碟陣列中,當RAID 1磁碟陣列中存在一個故障盤時並不影響RAID 10磁碟陣列的使用。當購買了新的硬碟裝置後再使用mdadm命令來予以替換即可,在此期間我們可以在/RAID目錄中正常地建立或刪除檔案。由於我們是在虛擬機器中模擬硬碟,所以先重啟系統,然後再把新的硬碟新增到RAID磁碟陣列中。
[[email protected] ~]# umount /RAID [[email protected] ~]# mdadm /dev/md0 -a /dev/sdb [[email protected] ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Mon Jan 30 00:08:56 2017 Raid Level : raid10 Array Size : 41909248 (39.97 GiB 42.92 GB) Used Dev Size : 20954624 (19.98 GiB 21.46 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Mon Jan 30 00:19:53 2017 State : clean Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : near=2 Chunk Size : 512K Name : localhost.localdomain:0 (local to host localhost.localdomain) UUID : d3491c05:cfc81ca0:32489f04:716a2cf0 Events : 56 Number Major Minor RaidDevice State 4 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde [[email protected] ~]# mount -a
磁碟陣列+備份盤
RAID 10磁碟陣列中最多允許50%的硬碟裝置發生故障,但是存在這樣一種極端情況,即同一RAID 1磁碟陣列中的硬碟裝置若全部損壞,也會導致資料丟失。換句話說,在RAID 10磁碟陣列中,如果RAID 1中的某一塊硬碟出現了故障,而我們正在前往修復的路上,恰巧該RAID1磁碟陣列中的另一塊硬碟裝置也出現故障,那麼資料就被徹底丟失了。這種RAID 1磁碟陣列中的硬碟裝置同時損壞的情況還真被我的學生遇到過。
在這樣的情況下,該怎麼辦呢?其實,我們完全可以使用RAID備份盤技術來預防這類事故。該技術的核心理念就是準備一塊足夠大的硬碟,這塊硬碟平時處於閒置狀態,一旦RAID磁碟陣列中有硬碟出現故障後則會馬上自動頂替上去。這樣很棒吧!
為了避免多個實驗之間相互發生衝突,我們需要保證每個實驗的相對獨立性,為此需要大家自行將虛擬機器還原到初始狀態。另外,由於剛才已經演示了RAID 10磁碟陣列的部署方法,我們現在來看一下RAID 5的部署效果。部署RAID 5磁碟陣列時,至少需要用到3塊硬碟,還需要再加一塊備份硬碟,所以總計需要在虛擬機器中模擬4塊硬碟裝置,如圖7-6所示。

圖7-6 在虛擬機器中模擬新增4塊硬碟裝置
現在建立一個RAID 5磁碟陣列+備份盤。在下面的命令中,引數-n 3代表建立這個RAID 5磁碟陣列所需的硬碟數,引數-l 5代表RAID的級別,而引數-x 1則代表有一塊備份盤。當檢視/dev/md0(即RAID 5磁碟陣列的名稱)磁碟陣列的時候就能看到有一塊備份盤在等待中了。
[[email protected] ~]# mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/sdb /dev/sdc /dev/sdd /dev/sde mdadm: layout defaults to left-symmetric mdadm: layout defaults to left-symmetric mdadm: chunk size defaults to 512K mdadm: size set to 20954624K mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. [[email protected] ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri May 8 09:20:35 2017 Raid Level : raid5 Array Size : 41909248 (39.97 GiB 42.92 GB) Used Dev Size : 20954624 (19.98 GiB 21.46 GB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Fri May 8 09:22:22 2017 State : clean Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Name : linuxprobe.com:0 (local to host linuxprobe.com) UUID : 44b1a152:3f1809d3:1d234916:4ac70481 Events : 18 Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 4 8 48 2 active sync /dev/sdd 3 8 64 - spare /dev/sde
現在將部署好的RAID 5磁碟陣列格式化為ext4檔案格式,然後掛載到目錄上,之後就可以使用了。 [[email protected] ~]# mkfs.ext4 /dev/md0 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=128 blocks, Stripe width=256 blocks 2621440 inodes, 10477312 blocks 523865 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2157969408 320 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done [[email protected] ~]# echo "/dev/md0 /RAID ext4 defaults 0 0" >> /etc/fstab [[email protected] ~]# mkdir /RAID [[email protected] ~]# mount -a
最後是見證奇蹟的時刻!我們再次把硬碟裝置/dev/sdb移出磁碟陣列,然後迅速檢視/dev/md0磁碟陣列的狀態,就會發現備份盤已經被自動頂替上去並開始了資料同步。RAID中的這種備份盤技術非常實用,可以在保證RAID磁碟陣列資料安全性的基礎上進一步提高資料可靠性,所以,如果公司不差錢的話還是再買上一塊備份盤以防萬一。
[[email protected] ~]# mdadm /dev/md0 -f /dev/sdb mdadm: set /dev/sdb faulty in /dev/md0 [[email protected] ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri May 8 09:20:35 2017 Raid Level : raid5 Array Size : 41909248 (39.97 GiB 42.92 GB) Used Dev Size : 20954624 (19.98 GiB 21.46 GB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Fri May 8 09:23:51 2017 State : active, degraded, recovering Active Devices : 2 Working Devices : 3 Failed Devices : 1 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Rebuild Status : 0% complete Name : linuxprobe.com:0 (local to host linuxprobe.com) UUID : 44b1a152:3f1809d3:1d234916:4ac70481 Events : 21 Number Major Minor RaidDevice State 3 8 64 0 spare rebuilding /dev/sde 1 8 32 1 active sync /dev/sdc 4 8 48 2 active sync /dev/sdd 0 8 16 - faulty /dev/sdb
LVM邏輯卷管理器
前面學習的硬碟裝置管理技術雖然能夠有效地提高硬碟裝置的讀寫速度以及資料的安全性,但是在硬碟分好區或者部署為RAID磁碟陣列之後,再想修改硬碟分割槽大小就不容易了。換句話說,當用戶想要隨著實際需求的變化調整硬碟分割槽的大小時,會受到硬碟“靈活性”的限制。這時就需要用到另外一項非常普及的硬碟裝置資源管理技術了—LVM(邏輯卷管理器)。LVM可以允許使用者對硬碟資源進行動態調整。
邏輯卷管理器是Linux系統用於對硬碟分割槽進行管理的一種機制,理論性較強,其建立初衷是為了解決硬碟裝置在建立分割槽後不易修改分割槽大小的缺陷。儘管對傳統的硬碟分割槽進行強制擴容或縮容從理論上來講是可行的,但是卻可能造成資料的丟失。而LVM技術是在硬碟分割槽和檔案系統之間添加了一個邏輯層,它提供了一個抽象的卷組,可以把多塊硬碟進行卷組合並。這樣一來,使用者不必關心物理硬碟裝置的底層架構和佈局,就可以實現對硬碟分割槽的動態調整。LVM的技術架構如圖7-7所示。

圖 ----邏輯卷管理器的技術結構
為了幫助大家理解,劉遄老師來舉一個吃貨的例子。比如小明家裡想吃饅頭但是麵粉不夠了,於是媽媽從隔壁老王家、老李家、老張家分別借來一些麵粉,準備蒸饅頭吃。首先需要把這些麵粉(物理卷[PV,Physical Volume])揉成一個大面團(卷組[VG,Volume Group]),然後再把這個大面團分割成一個個小饅頭(邏輯卷[LV,Logical Volume]),而且每個小饅頭的重量必須是每勺麵粉(基本單元[PE,Physical Extent])的倍數。
物理卷處於LVM中的最底層,可以將其理解為物理硬碟、硬碟分割槽或者RAID磁碟陣列,這都可以。卷組建立在物理卷之上,一個卷組可以包含多個物理卷,而且在卷組建立之後也可以繼續向其中新增新的物理卷。邏輯卷是用卷組中空閒的資源建立的,並且邏輯卷在建立後可以動態地擴充套件或縮小空間。這就是LVM的核心理念。
部署邏輯卷
一般而言,在生產環境中無法精確地評估每個硬碟分割槽在日後的使用情況,因此會導致原先分配的硬碟分割槽不夠用。比如,伴隨著業務量的增加,用於存放交易記錄的資料庫目錄的體積也隨之增加;因為分析並記錄使用者的行為從而導致日誌目錄的體積不斷變大,這些都會導致原有的硬碟分割槽在使用上捉襟見肘。而且,還存在對較大的硬碟分割槽進行精簡縮容的情況。
我們可以通過部署LVM來解決上述問題。部署LVM時,需要逐個配置物理卷、卷組和邏輯卷。常用的部署命令如表7-2所示。
表 常用的LVM部署命令
| 功能/命令 | 物理卷管理 | 卷組管理 | 邏輯卷管理 |
| 掃描 | pvscan | vgscan | lvscan |
| 建立 | pvcreate | vgcreate | lvcreate |
| 顯示 | pvdisplay | vgdisplay | lvdisplay |
| 刪除 | pvremove | vgremove | lvremove |
| 擴充套件 | vgextend | lvextend | |
| 縮小 | vgreduce | lvreduce |
為了避免多個實驗之間相互發生衝突,請大家自行將虛擬機器還原到初始狀態,並在虛擬機器中新增兩塊新硬碟裝置,然後開機,如圖7-8所示。
在虛擬機器中新增兩塊新硬碟裝置的目的,是為了更好地演示LVM理念中使用者無需關心底層物理硬碟裝置的特性。我們先對這兩塊新硬碟進行建立物理卷的操作,可以將該操作簡單理解成讓硬碟裝置支援LVM技術,或者理解成是把硬碟裝置加入到LVM技術可用的硬體資源池中,然後對這兩塊硬碟進行卷組合並,卷組的名稱可以由使用者來自定義。接下來,根據需求把合併後的卷組切割出一個約為150MB的邏輯卷裝置,最後把這個邏輯卷裝置格式化成EXT4檔案系統後掛載使用。在下文中,將對每一個步驟再作一些簡單的描述。
第1步:讓新新增的兩塊硬碟裝置支援LVM技術。
[[email protected] ~]# pvcreate /dev/sdb /dev/sdc Physical volume "/dev/sdb" successfully created Physical volume "/dev/sdc" successfully created

圖7-8 在虛擬機器中新增兩塊新的硬碟裝置
第2步:把兩塊硬碟裝置加入到storage卷組中,然後檢視卷組的狀態。
[[email protected] ~]# vgcreate storage /dev/sdb /dev/sdc Volume group "storage" successfully created [[email protected] ~]# vgdisplay --- Volume group --- VG Name storage System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 39.99 GiB PE Size 4.00 MiB Total PE 10238 Alloc PE / Size 0 / 0 Free PE / Size 10238 / 39.99 GiB VG UUID KUeAMF-qMLh-XjQy-ArUo-LCQI-YF0o-pScxm1 ………………省略部分輸出資訊………………
第3步:切割出一個約為150MB的邏輯卷裝置。
這裡需要注意切割單位的問題。在對邏輯捲進行切割時有兩種計量單位。第一種是以容量為單位,所使用的引數為-L。例如,使用-L 150M生成一個大小為150MB的邏輯卷。另外一種是以基本單元的個數為單位,所使用的引數為-l。每個基本單元的大小預設為4MB。例如,使用-l 37可以生成一個大小為37×4MB=148MB的邏輯卷。
[[email protected] ~]# lvcreate -n vo -l 37 storage Logical volume "vo" created [[email protected] ~]# lvdisplay --- Logical volume --- LV Path /dev/storage/vo LV Name vo VG Name storage LV UUID D09HYI-BHBl-iXGr-X2n4-HEzo-FAQH-HRcM2I LV Write Access read/write LV Creation host, time localhost.localdomain, 2017-02-01 01:22:54 -0500 LV Status available # open 0 LV Size 148.00 MiB Current LE 37 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:2 ………………省略部分輸出資訊………………
第4步:把生成好的邏輯捲進行格式化,然後掛載使用。
Linux系統會把LVM中的邏輯卷裝置存放在/dev裝置目錄中(實際上是做了一個符號連結),同時會以卷組的名稱來建立一個目錄,其中儲存了邏輯卷的裝置對映檔案(即/dev/卷組名稱/邏輯卷名稱)。
[[email protected] ~]# mkfs.ext4 /dev/storage/vo mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) Stride=0 blocks, Stripe width=0 blocks 38000 inodes, 151552 blocks 7577 blocks (5.00%) reserved for the super user First data block=1 Maximum filesystem blocks=33816576 19 block groups 8192 blocks per group, 8192 fragments per group 2000 inodes per group Superblock backups stored on blocks: 8193, 24577, 40961, 57345, 73729 Allocating group tables: done Writing inode tables: done Creating journal (4096 blocks): done Writing superblocks and filesystem accounting information: done [[email protected] ~]# mkdir /linuxprobe [[email protected] ~]# mount /dev/storage/vo /linuxprobe
第5步:檢視掛載狀態,並寫入到配置檔案,使其永久生效。
[[email protected] ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/rhel-root 18G 3.0G 15G 17% / devtmpfs 905M 0 905M 0% /dev tmpfs 914M 140K 914M 1% /dev/shm tmpfs 914M 8.8M 905M 1% /run tmpfs 914M 0 914M 0% /sys/fs/cgroup /dev/sr0 3.5G 3.5G 0 100% /media/cdrom /dev/sda1 497M 119M 379M 24% /boot /dev/mapper/storage-vo 145M 7.6M 138M 6% /linuxprobe [[email protected] ~]# echo "/dev/storage/vo /linuxprobe ext4 defaults 0 0" >> /etc/fstab
7.2.2 擴容邏輯卷
在前面的實驗中,卷組是由兩塊硬碟裝置共同組成的。使用者在使用儲存裝置時感知不到裝置底層的架構和佈局,更不用關心底層是由多少塊硬碟組成的,只要卷組中有足夠的資源,就可以一直為邏輯卷擴容。擴充套件前請一定要記得解除安裝裝置和掛載點的關聯。
[[email protected] ~]# umount /linuxprobe
第1步:把上一個實驗中的邏輯卷vo擴充套件至290MB。
[[email protected] ~]# lvextend -L 290M /dev/storage/vo Rounding size to boundary between physical extents: 292.00 MiB Extending logical volume vo to 292.00 MiB Logical volume vo successfully resized
第2步:檢查硬碟完整性,並重置硬碟容量。
[[email protected] ~]# e2fsck -f /dev/storage/vo e2fsck 1.42.9 (28-Dec-2013) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/storage/vo: 11/38000 files (0.0% non-contiguous), 10453/151552 blocks [[email protected] ~]# resize2fs /dev/storage/vo resize2fs 1.42.9 (28-Dec-2013) Resizing the filesystem on /dev/storage/vo to 299008 (1k) blocks. The filesystem on /dev/storage/vo is now 299008 blocks long.
第3步:重新掛載硬碟裝置並檢視掛載狀態。
[[email protected] ~]# mount -a [[email protected] ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/rhel-root 18G 3.0G 15G 17% / devtmpfs 985M 0 985M 0% /dev tmpfs 994M 80K 994M 1% /dev/shm tmpfs 994M 8.8M 986M 1% /run tmpfs 994M 0 994M 0% /sys/fs/cgroup /dev/sr0 3.5G 3.5G 0 100% /media/cdrom /dev/sda1 497M 119M 379M 24% /boot /dev/mapper/storage-vo 279M 2.1M 259M 1% /linuxprobe
7.2.3 縮小邏輯卷
相較於擴容邏輯卷,在對邏輯捲進行縮容操作時,其丟失資料的風險更大。所以在生產環境中執行相應操作時,一定要提前備份好資料。另外Linux系統規定,在對LVM邏輯捲進行縮容操作之前,要先檢查檔案系統的完整性(當然這也是為了保證我們的資料安全)。在執行縮容操作前記得先把檔案系統解除安裝掉。
[[email protected] ~]# umount /linuxprobe
第1步:檢查檔案系統的完整性。
[[email protected] ~]# e2fsck -f /dev/storage/vo e2fsck 1.42.9 (28-Dec-2013) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/storage/vo: 11/74000 files (0.0% non-contiguous), 15507/299008 blocks
第2步:把邏輯卷vo的容量減小到120MB。
[[email protected] ~]# resize2fs /dev/storage/vo 120M resize2fs 1.42.9 (28-Dec-2013) Resizing the filesystem on /dev/storage/vo to 122880 (1k) blocks. The filesystem on /dev/storage/vo is now 122880 blocks long. [[email protected] ~]# lvreduce -L 120M /dev/storage/vo WARNING: Reducing active logical volume to 120.00 MiB THIS MAY DESTROY YOUR DATA (filesystem etc.) Do you really want to reduce vo? [y/n]: y Reducing logical volume vo to 120.00 MiB Logical volume vo successfully resized
第3步:重新掛載檔案系統並檢視系統狀態。
[[email protected] ~]# mount -a [[email protected] ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/rhel-root 18G 3.0G 15G 17% / devtmpfs 985M 0 985M 0% /dev tmpfs 994M 80K 994M 1% /dev/shm tmpfs 994M 8.8M 986M 1% /run tmpfs 994M 0 994M 0% /sys/fs/cgroup /dev/sr0 3.5G 3.5G 0 100% /media/cdrom /dev/sda1 497M 119M 379M 24% /boot /dev/mapper/storage-vo 113M 1.6M 103M 2% /linuxprobe
邏輯卷快照
LVM還具備有“快照卷”功能,該功能類似於虛擬機器軟體的還原時間點功能。例如,可以對某一個邏輯卷裝置做一次快照,如果日後發現數據被改錯了,就可以利用之前做好的快照捲進行覆蓋還原。LVM的快照卷功能有兩個特點:
快照卷的容量必須等同於邏輯卷的容量;
快照卷僅一次有效,一旦執行還原操作後則會被立即自動刪除。
首先檢視卷組的資訊。
[[email protected] ~]# vgdisplay --- Volume group --- VG Name storage System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 4 VG Access read/write VG Status resizable MAX LV 0 Cur LV 1 Open LV 1 Max PV 0 Cur PV 2 Act PV 2 VG Size 39.99 GiB PE Size 4.00 MiB Total PE 10238 Alloc PE / Size 30 / 120.00 MiB Free PE / Size 10208 / 39.88 GiB VG UUID CTaHAK-0TQv-Abdb-R83O-RU6V-YYkx-8o2R0e ………………省略部分輸出資訊………………
通過卷組的輸出資訊可以清晰看到,卷組中已經使用了120MB的容量,空閒容量還有39.88GB。接下來用重定向往邏輯卷裝置所掛載的目錄中寫入一個檔案。
[[email protected] ~]# echo "Welcome to Linuxprobe.com" > /linuxprobe/readme.txt [[email protected] ~]# ls -l /linuxprobe total 14 drwx------. 2 root root 12288 Feb 1 07:18 lost+found -rw-r--r--. 1 root root 26 Feb 1 07:38 readme.txt
第1步:使用-s引數生成一個快照卷,使用-L引數指定切割的大小。另外,還需要在命令後面寫上是針對哪個邏輯卷執行的快照操作。
[[email protected] ~]# lvcreate -L 120M -s -n SNAP /dev/storage/vo Logical volume "SNAP" created [[email protected] ~]# lvdisplay --- Logical volume --- LV Path /dev/storage/SNAP LV Name SNAP VG Name storage LV UUID BC7WKg-fHoK-Pc7J-yhSd-vD7d-lUnl-TihKlt LV Write Access read/write LV Creation host, time localhost.localdomain, 2017-02-01 07:42:31 -0500 LV snapshot status active destination for vo LV Status available # open 0 LV Size 120.00 MiB Current LE 30 COW-table size 120.00 MiB COW-table LE 30 Allocated to snapshot 0.01% Snapshot chunk size 4.00 KiB Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:3 ………………省略部分輸出資訊………………
第2步:在邏輯卷所掛載的目錄中建立一個100MB的垃圾檔案,然後再檢視快照卷的狀態。可以發現儲存空間佔的用量上升了。
[[email protected] ~]# dd if=/dev/zero of=/linuxprobe/files count=1 bs=100M 1+0 records in 1+0 records out 104857600 bytes (105 MB) copied, 3.35432 s, 31.3 MB/s [[email protected] ~]# lvdisplay --- Logical volume --- LV Path /dev/storage/SNAP LV Name SNAP VG Name storage LV UUID BC7WKg-fHoK-Pc7J-yhSd-vD7d-lUnl-TihKlt LV Write Access read/write LV Creation host, time localhost.localdomain, 2017-02-01 07:42:31 -0500 LV snapshot status active destination for vo LV Status available # open 0 LV Size 120.00 MiB Current LE 30 COW-table size 120.00 MiB COW-table LE 30 Allocated to snapshot 83.71% Snapshot chunk size 4.00 KiB Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:3
第3步:為了校驗SNAP快照卷的效果,需要對邏輯捲進行快照還原操作。在此之前記得先解除安裝掉邏輯卷裝置與目錄的掛載。
[[email protected] ~]# umount /linuxprobe [[email protected] ~]# lvconvert --merge /dev/storage/SNAP Merging of volume SNAP started. vo: Merged: 21.4% vo: Merged: 100.0% Merge of snapshot into logical volume vo has finished. Logical volume "SNAP" successfully removed
第4步:快照卷會被自動刪除掉,並且剛剛在邏輯卷裝置被執行快照操作後再創建出來的100MB的垃圾檔案也被清除了。
[[email protected] ~]# mount -a [[email protected] ~]# ls /linuxprobe/ lost+found readme.txt
刪除邏輯卷
當生產環境中想要重新部署LVM或者不再需要使用LVM時,則需要執行LVM的刪除操作。為此,需要提前備份好重要的資料資訊,然後依次刪除邏輯卷、卷組、物理卷裝置,這個順序不可顛倒。
第1步:取消邏輯卷與目錄的掛載關聯,刪除配置檔案中永久生效的裝置引數。
[[email protected] ~]# umount /linuxprobe [[email protected] ~]# vim /etc/fstab # # /etc/fstab # Created by anaconda on Fri Feb 19 22:08:59 2017 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/rhel-root / xfs defaults 1 1 UUID=50591e35-d47a-4aeb-a0ca-1b4e8336d9b1 /boot xfs defaults 1 2 /dev/mapper/rhel-swap swap swap defaults 0 0 /dev/cdrom /media/cdrom iso9660 defaults 0 0 /dev/storage/vo /linuxprobe ext4 defaults 0 0
第2步:刪除邏輯卷裝置,需要輸入y來確認操作。
[[email protected] ~]# lvremove /dev/storage/vo Do you really want to remove active logical volume vo? [y/n]: y Logical volume "vo" successfully removed
第3步:刪除卷組,此處只寫卷組名稱即可,不需要裝置的絕對路徑。
[[email protected] ~]# vgremove storage Volume group "storage" successfully removed
第4步:刪除物理卷裝置。
[相關推薦
RAID和LVM磁碟陣列
RAID磁碟冗餘陣列 CPU的處理效能保持著高速增長,Intel公司在2017年最新發布的i9-7980XE處理器晶片更是達到了18核心36執行緒。但與此同時,硬碟裝置的效能提升卻不是很大,因此逐漸成為當代計算機整體效能的瓶頸。而且,由於硬碟裝置需要進行持續、頻繁、大量的IO操作,相較於其他裝置
linux學習第七章使用RAID和LVM磁碟陣列技術
一、RAID磁碟冗餘陣列 1988年,加利福尼亞大學伯克利分校首次提出並定義了RAID技術的概念。RAID技術通過把多個硬碟裝置
第七天 學習 使用RAID與LVM磁碟陣列技術
RAID磁碟冗餘陣列 1、硬碟成本問題 2、高效能 i/o速度 3、高可用 資料安全性 mdadm命令用於管理Linux系統中的軟體RAID硬碟陣列,格式為“mdadm [模式] <RAID裝置名稱> [選項] [成員裝置名稱]” -a 檢測裝
raid和lvm
raid lvm 一:raidraid 磁盤陣列riad級別 最少磁盤數 可用磁盤容量 性能 安全性 riad0 2 所有磁盤容量之和
磁盤配額,RAID和LVM管理
磁盤配額 RAID LVM邏輯卷 一、磁盤配額 1.磁盤配額的作用??磁盤配額就限制用戶在該目錄中使用空間的大小和限制用戶 上傳文件的數量(也就是inode號)。2.舉例在創建磁盤配額時,需要關閉selinux [root@centos6 ~]#vim /etc/selinux/config #
Linux磁盤掛載與RAID和LVM
int 管理操作 軟件 管理 xtend 事先 掛載文件系統 性能 鏈接文件 Linux磁盤掛載掛載:將額外文件系統與根文件系統某現存的目錄建立關聯關系,進而使得此目錄作為其他文件訪問入口的行為。 卸載:解除掛載的關聯關系的過程。 掛載點:掛載的目標位置。 linux中掛載
Linux 學習之路(十一):RAID和LVM
傳輸速度 Mb/8=MB 硬碟的介面: IDE(ATA):133Mbps 並行匯流排 SATA:300Mbps,600Mbps,6Gbps 序列匯流排 USB:USB3.0:480Mbps 序列匯流排 SCSI:Small Computer System Int
centos的raid和LVM管理筆記
efault 資源 sdc 需要 mkfs格式化 兩個 流程 分布 級別 磁盤管理(disk manage) - 01-16-AMRAID磁盤陣列應用場景:公司購買了5塊2G的硬盤,要求工程師將這5塊硬盤用某種技術從邏輯上組合成一個大 容量的存儲空間(如2G*5=10G)。
10.RAID和LVM分區
受限 png bubuko 圖片 不用 軟raid 沒有 事先 硬件 企業中一般通過硬件完成RAID,不用軟raid,功能性能差,冗余也受限操作系統,軟RAID降低好多性能想要優化不要用LVMLVM可以對設置好的分區大小進行動態的調整,前提是分區格式做成8e的標號不用LVM
CentOS下軟raid和lvm結合
line idc rdo 回車 aux been eba cto last 一.添加三塊10G硬盤 [[email protected] ~]# fdisk -l |grep sd 磁盤 /dev/sda:53.7 GB, 53687091200 字節,10485
光纖儲存重組raid磁碟陣列和raid資料恢復成功案例
今天我給大家分享的是一篇關於raid磁碟陣列資料恢復的案例,本案例中包含了對磁碟陣列的修復和重組過程,raid資料恢復中的方法比較通用,希望在資料恢復方面對大家有所幫助。 Raid陣列情況介紹: 需要進行資料恢復的陣列搭建在一臺某品牌的S5020型號光纖儲存上。這個磁碟陣列中一共包含了14塊硬碟,其中10
03: Split分離解析 RAID磁碟陣列 程序管理 日誌管理 總結和答疑
Top NSD SERVICES DAY03 1 案例1:配置並驗證Split分離解析 1.1 問題 本例要求配置一臺智慧DNS伺服器,針對同一個FQDN,當不同的客戶機來查詢時能夠給出不同的答案。需要完成下列任務: 從主機192.168.4.207查詢時,結果
Linux進階篇--磁碟陣列(RAID)和邏輯卷管理
磁碟陣列RAID RAID:RedundantArrays of Inexpensive(Independent)Disks 早期被稱為RedundantArrays of Inexpensive Disks(廉價的磁碟陣列),後來隨著技術的不斷完善,又被
linux雲自動化系統運維19(磁盤陣列raid,lvm管理)
linux軟件能做的raid1.讀取速度加倍,兩塊磁盤一起讀取raid0.寫 兩塊硬盤,一塊寫一半raid5:raid1+raid0 三塊磁盤mdadm -C /dev/md0 -a yes -l 1 -n 2 -x 1 /dev/vdb{1..3}-C;創建 -a :添加 -l:優先級 -n:使用
RAID、LVM和btrfs文件系統
linux RAID LVM btrfs一、RAID: Redundant Arrays of Inexpensive Disks,廉價磁盤冗余陣列; Redundant Arrays of Independent Disks,獨立磁盤冗余陣列; 將多個相對廉價的IDE接口的磁盤組合成一個&
RAID和邏輯卷管理器(LVM)
RAID和邏輯卷管理器(LVM)什麽是RAID RAID:RedundantArrays of Inexpensive(Independent)Disks 廉價的獨立磁盤 1988年由加利福尼亞大學伯克利分校(University of California-Berkeley)“A Case fo
使用RAID與LVM磁盤陣列技術。
size 管理 格式化 mda 創建raid lvm aid oss watermark 1、在虛擬機中添加4塊硬盤設備來制作一個RAID 10磁盤陣列2、使用mdadm中的參數創建RAID磁盤陣列3、把制作好的RAID磁盤陣列格式化為ext4格式。4、創建掛載點然後把硬盤
【儲存】RAID磁碟陣列(Redundant Arrays of Independent Disks)
RAID 的兩個關鍵目標是提高資料可靠性和 I/O 效能。在整個系統中,RAID被看作是由兩個或更多磁碟組成的儲存空間,通過併發地在多個磁碟上讀寫資料來提高儲存系統的 I/O 效能。大多數 RAID 等級具有完備的資料校驗、糾正措施,從而提高系統的容錯性,甚至映象方式,大大增強系統的可靠性,Redundant
各種磁碟陣列模式(各種raid)之間的區別
各種需求各種場景,可以應用不同的磁碟陣列模式 RAID0
軟體磁碟陣列(software raid)
一、基本概念 1.磁碟陣列RAID,即容錯廉價磁碟陣列,RAID可以通過一些技術將多個較小的磁碟整合成一個較大的磁碟裝置,並把資料切割成多個區段後分別存放在各個不同的物理硬碟裝置上,然後利用分散讀寫技術來提升磁碟陣列整體的效能,同時把多個重要資料的副本同步到不同的物理硬碟裝置上 2.RAID