
CentOS 7.1系統自動重啟的Bug定位過程
【問題】
有同事反應最近有多臺MongoDB的伺服器CentOS 7.1系統會自動重啟,分析了下問題原因。
【排查過程】
1、 檢查系統日誌/var/log/message,並沒有記錄異常資訊,journalctl相關日誌只記錄發生過重啟
2、 系統預設配置了kdump,使用crash工具分析/var/crash下的轉儲檔案vmcore,命令如下:
crash /usr/lib/debug/lib/modules/3.10.0-327.36.3.el7.x86_64/vmlinux /tmp/vmcore
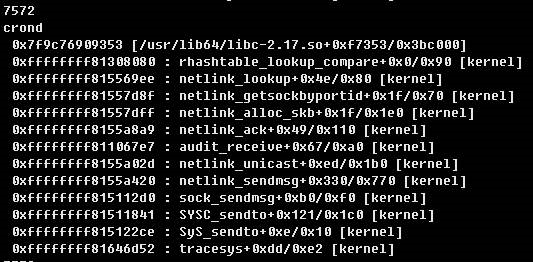
3、 可以看到kernel crash時的Call Trace,關鍵資訊標註為黃色字型
crash> bt
PID: 9979 TASK: ffff8804b4020b80 CPU: 2 COMMAND: "crond"
#0 [ffff8804b42db778] machine_kexec at ffffffff81051e9b
#1 [ffff8804b42db7d8] crash_kexec at ffffffff810f27e2
#2 [ffff8804b42db8a8] oops_end at ffffffff8163f448
#3 [ffff8804b42db8d0] no_context at ffffffff8162f561
#4 [ffff8804b42db920] __bad_area_nosemaphore at ffffffff8162f5f7
#5 [ffff8804b42db968] bad_area at ffffffff8162f91b
#6 [ffff8804b42db990] __do_page_fault at ffffffff81642235
#7 [ffff8804b42db9f0] trace_do_page_fault at ffffffff81642403
#8 [ffff8804b42dba28] do_async_page_fault at ffffffff81641ae9
#9 [ffff8804b42dba40] async_page_fault at ffffffff8163e678
[exception RIP: netlink_compare
RIP: ffffffff815560bb RSP: ffff8804b42dbaf8 RFLAGS: 00010246
RAX: 0000000000000000 RBX: 000000049f250000 RCX: 00000000c3637c42
RDX: 00000000000026fb RSI: ffff8804b42dbb48 RDI: 000000049f24fb78
RBP: ffff8804b42dbb30 R8: ffff8804b42dbb44 R9: 0000000000002170
R10: 0000000000000000 R11: ffff8804b42db966 R12: ffff88061dcd2678
R13: ffff8804b42dbb48 R14: ffffffff815560b0 R15: ffff88061b639000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#10 [ffff8804b42dbb00] rhashtable_lookup_compare at ffffffff813080d0
#11 [ffff8804b42dbb38] netlink_lookup at ffffffff815569ee
#12 [ffff8804b42dbb68] netlink_getsockbyportid at ffffffff81557d8f
#13 [ffff8804b42dbb80] netlink_alloc_skb at ffffffff81557dff
#14 [ffff8804b42dbbb8] netlink_ack at ffffffff8155a8a9
#15 [ffff8804b42dbbf0] audit_receive at ffffffff811067e7
#16 [ffff8804b42dbc18] netlink_unicast at ffffffff8155a02d
#17 [ffff8804b42dbc60] netlink_sendmsg at ffffffff8155a420
#18 [ffff8804b42dbcf8] sock_sendmsg at ffffffff815112d0
#19 [ffff8804b42dbe58] SYSC_sendto at ffffffff81511841
#20 [ffff8804b42dbf70] sys_sendto at ffffffff815122ce
#21 [ffff8804b42dbf80] system_call_fastpath at ffffffff81646b49
RIP: 00007f4ac19d5353 RSP: 00007ffe233b1fb8 RFLAGS: 00010202
RAX: 000000000000002c RBX: ffffffff81646b49 RCX: 0000000000000000
RDX: 000000000000009c RSI: 00007ffe233b1ff0 RDI: 0000000000000003
RBP: 00007ffe233b1ff0 R8: 00007ffe233b1fe0 R9: 000000000000000c
R10: 0000000000000000 R11: 0000000000000246 R12: ffffffff815122ce
R13: ffff8804b42dbf78 R14: 000000000000044d R15: 0000000000000001
ORIG_RAX: 000000000000002c CS: 0033 SS: 002b
4、在網上搜索,定位到這是kernel Linux 3.10.0-327.36.3.el7.x86_64的bug,詳細描述可以參見下面,該bug在 7.3 kernel (3.10.0-514.el7)後修復
https://bugs.centos.org/view.php?id=12012
5、 但考慮到升級系統成本較高,後面嘗試定位觸發條件,可以看到觸發這個bug是crond命令
PID: 9979 TASK: ffff8804b4020b80 CPU: 2 COMMAND: "crond"
6、 藉助systemtap工具,在發生crash的kernel函式上加探針,kernel.function("rhashtable_lookup_compare")
抓取到crond等系統命令確實會呼叫上面的函式
7、考慮到Mongo最近新上了一套系統監控的指令碼是通過crontab排程的,而上監控之前伺服器重啟的情況很少,猜測可能是crontab排程系統監控採集觸發了kernel bug
後面計劃將採集指令碼改為服務的方式觀察是否可以規避觸發bug
【結論】
由於已發現當前CentOS 7.1存在自動重啟的bug,建議後面新上的linux伺服器都採用CentOS7.4的系統
Description: CentOS Linux release 7.1.1503 (Core)
Release: 7.1.1503
Linux 3.10.0-327.36.3.el7.x86_64
資料庫運維經驗分享&MySQL原始碼學習漫漫路
