C/C++基礎----關聯容器
阿新 • • 發佈:2018-12-27
- 基本屬性
與順序容器的差別,按照關鍵字來儲存和訪問,而順序容器是按照容器中的位置來順序儲存和訪問。
map:每個元素是一對鍵值(key-valye)組合;set每個元素只包含關鍵字。。
每個根據關鍵字是否可以重複分成兩類,又根據關鍵字是否有序儲存分成兩類。
map通過關鍵字而不是位置來訪問
set 只想知道一個值是否存在時,set最有用。
map 經典例子—單詞計數器
set 想忽略常見單詞,用set儲存想要忽略的單詞。- 操作
關聯容器支援普通與位置無關的操作,不支援建構函式或插入操作這些接收一個元素值和一個數量值的操作。 關聯容器還支援一些順序容器不支援的操作和類型別名。此外,無序容器還提供一些調整雜湊效能的操作。 關聯容器的迭代器都是雙向的。 關聯容器的關鍵字型別必須定義比較的方法,預設使用<運算子。 傳遞給排序演算法的可呼叫物件,必須滿足與關聯容器中關鍵字一樣的型別要求。 關鍵字型別上定義一個嚴格弱序。 自定義的關鍵字比較操作比較在尖括號中緊跟著元素型別給出。比較操作型別應該是一種函式指標。 pair的建構函式預設對資料成員進行值初始化。其資料成員是public的,兩個成員分別命名為first和second。 初始化方式 p (v1, v2) p={v1, v2} make_pair(v1, v2)
- 類型別名
- key_type
- mapped_type
- value_type 對set等於key_type;對map,pair<const key_type, mapped_type>
map的key也是const的
set的迭代器是const的 演算法
通常不對關聯容器使用泛型演算法,可用於只讀取元素的演算法。 但很多這類演算法會用到搜尋序列,由於不能通過關鍵字進行快速查詢,所有使用泛型演算法幾乎總是個壞主意。 實際程式設計中真要對關聯容器使用演算法,要麼將它當做一個源序列,要麼作為一個目的位置。 關聯容器insert返回一個pair,包含一個指向具有指定關鍵字的元素,和一個指示插入是否成功的bool值。 對於允許重複關鍵字的關聯容器,insert操作返回一個指向新元素的迭代器,無需返回一個bool值。 3個版本的erase 非const的map和無序map可以使用下標,如關鍵字不存在會建立一個元素。 c.at(k) 訪問關鍵詞為k的元素,若k不在c中,丟擲out_of_range異常。 以上兩個返回的是mapped_type,而解引用返回的是value_type
- 訪問元素
find(k)查詢元素是否存在,返回指向第一個關鍵字為k元素的迭代器,不存在則尾後 cout(k) 計數 返回關鍵字等於k的元素的數量 lower_bound(k) 返回一個迭代器,指向第一個關鍵字不小於k的元素 upper_bound(k) 返回一個迭代器,指向第一個關鍵字大於k的元素 equal_range(k) 返回一個迭代器pair,表示關鍵字等於k的元素的範圍。不存在則pair兩個成員都為end() 1以count和find配合遍歷所有關鍵字為k的元素 2可以lower_bound和upper_bound配合獲得所有元素的範圍。如關鍵字不在容器中,lower_bound會返回第一個安全插入點,不影響容器中元素順序的插入位置 3 qual_range 本質上跟第二種一樣。
- 無序容器
- 不是通過比較運算子來組織元素,而是使用hash函式和關鍵字型別的==運算子
- 在關鍵字沒有明顯的序關係的情況下,無序容器是很有用的。或者在某些應用場合維護元素的序的代價非常高貴,此時無序容器也是很有用的。
- 理論上hash技術能獲得更好地平均效能,但要達到需要效能測試和調優工作。通常使用無序容器更為簡單。管理桶
- 無序容器的效能依賴於雜湊函式的質量和桶的數量大小。
| 無序容器管理操作 | |
|---|---|
| c.bucket_count() | 正在使用的桶的數量 |
| c.max_bucket_count() | 容器能容納的最多的桶的數量 |
| c.bucket_size(n) | 第n個桶中有多少個元素 |
| c.bucket(k) | 關鍵字為k的元素在哪個桶中 |
| 桶迭代 | |
| local_iterator | 可以訪問桶中元素迭代器的型別 |
| const_local_iterator | const版本 |
| c.begin(n), c.end(n) | |
| c.cbegin(n), c.cend(n) | |
| 雜湊策略 | |
| c.load_factor() | 每個桶的平均元素數量,返回float |
| c.max_load_factor() | c試圖維護的平均桶大小,在需要時會新增新桶 |
| c.rehash(n) | 重組儲存,桶數>=n且>size/max_load_factor |
| c.reserve(n) | 重組儲存,使得c可以儲存n個元素且不必rehash |
自定義類型別的無序容器,必須提供自己版本的hash模板版本,還有比較函式(或==)
樹
二叉樹
- 如果平衡,搜尋效能逼近二分查詢。相比連續記憶體空間的二分查詢優點是,增刪時不需要移動大段的記憶體資料,甚至通常是常數開銷。實際使用的二叉樹加上平衡演算法。
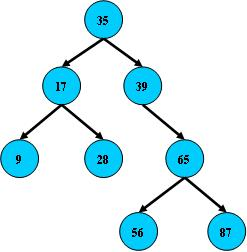
紅黑樹
- 子女個數可以有多個,主要減少io的次數,減小樹的層數,同時解決平衡問題,保證至少半滿。
- 效能等價與二分查詢
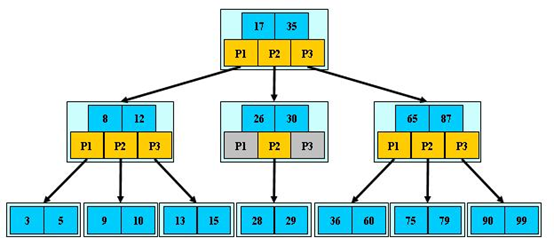
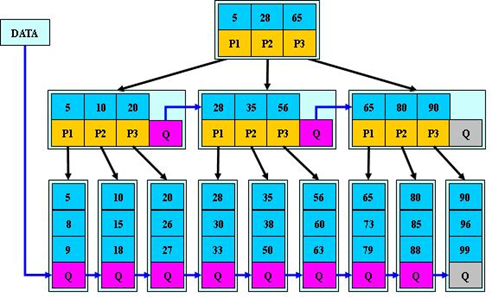
B+樹
- 內部節點並沒有指向具體資料的指標,同一個盤塊中可以容納更多的關鍵字數量,一次性讀入記憶體的關鍵字就更多,IO讀寫次數就降低了。
- 指標指向一個半開區間 [ ),葉子節點之間增加指標,方便遍歷或範圍查詢。
- 所有資料都儲存在葉子節點中,保證每次搜尋都花費相同的時間,查詢效率更穩定。
- 所有關鍵字都出現在連結串列中(稠密索引),非葉子節點相當於是葉子節點的索引(稀疏索引),葉子節點相當於是儲存資料的資料層。
- 內部節點並沒有指向具體資料的指標,同一個盤塊中可以容納更多的關鍵字數量,一次性讀入記憶體的關鍵字就更多,IO讀寫次數就降低了。
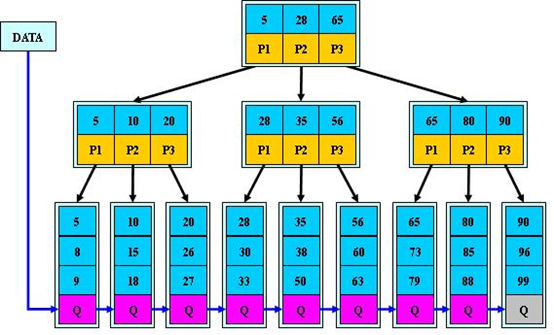
B*樹
- 至少2/3滿,提高塊利用率。
- B+樹分裂隻影響到原結點和父結點,故不需要兄弟指標
- 分配新節點的概率低。
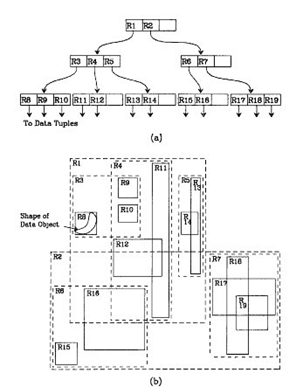
R樹
- 高維空間的搜尋問題,把B樹的思想擴充套件到了多維空間。
- 最小邊界矩陣進行空間分割。
- 最佳應用範圍是2到6維,更高維的儲存會變得非常複雜。
- 變體R*樹。