
一步一步教你如何用Python做詞雲!
前言
在大資料時代,你竟然會在網上看到的詞雲,例如這樣的。

看到之後你是什麼感覺?想不想自己做一個?
如果你的答案是正確的,那就不要拖延了,現在我們就開始,做一個詞雲分析圖,Python是一個當下很流行的程式語言,你不僅可以用它做資料分析和視覺化,還能用來做網站、爬取資料、做數學題、寫指令碼替你偷懶……
如果你之前沒有程式設計基礎,沒關係。希望你不要限於瀏覽,而是親自動手嘗試一番。到完成的那一步,你不僅可以做出第一張詞雲圖,而且這還將是你的第一個有用的程式設計作品。
安裝 wordcloud庫
請確保你的python環境沒有問題,我用的開發工具是VsCode,首先你要在Python擴充套件中安裝python開發環境(當然,這不是為你的windows安裝python)
那麼你還需要安裝所需要的第三方庫,那麼在VSCode中並沒有PyCharm那麼專業,這裡需要獲得你自己的Python指令碼位置。
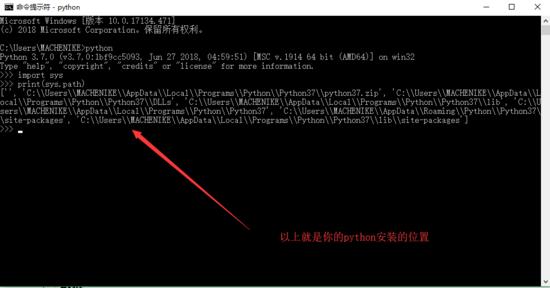
我們可以發現裡面有一個名為pip.exe檔案,這個檔案就是python官方給我們去安裝python第三方庫的一個程式,那麼我們可以在VsCode的終端中就可以去通過它,這也是我們為什麼要獲取python安裝位置的根本原因。
例如我們安裝WordCloud,我們的操作如下:
pip install WordCloud
資料
這個時候我們就要開始Code了,我們一定需要資料,這裡我自己找了一個繞口令,內容如下:
Betty Botter bought some butter but she said the butter's bitter. If I put it in my batter it will make my batter bitter. So, she bought some better butter, better than the bitter butter and she put it in her batter and her batter was not bitter. So 'twas good that Betty Botter bought some better butter.
翻譯: 貝蒂·波特買牛油, 可她說:“牛油是苦的。 不過加上一點好牛油—— 可以使苦牛油更好點。” 於是她買了一點牛油, 比苦牛油好點的牛油。 摻了之後苦牛油真的變的好多了。 所以這就是貝蒂·波特買的一點比苦牛油好點的牛油。
我把其中的文字儲存成了一個文字,叫做minister.txt。
Code
python做詞雲呢,需要匯入的包有wordcloud和PIL,其中PIL(Python Image Library)是python平臺影象處理標準庫,功能是真的強大。首先需要讀取檔案 。
首先我們要讀取我們的txt檔案,那麼程式碼如下:
from wordcloud import WordCloud
import PIL .Image as image
with open("F:minister.txt") as fp:
text=fp.read()
print(text)
執行指令碼結果如下:

接下來導包,我們看看如何生成最簡單的詞雲:
from wordcloud import WordCloud
import PIL .Image as image
with open("F:minister.txt") as fp:
text=fp.read()
#print(text)
#將文字放入WordCoud容器物件中並分析
WordCloud = WordCloud().generate(text)
image_produce = WordCloud.to_image()
image_produce.show()
如果python引入無誤,並程式碼無誤,那麼會彈出你生成的圖片,該圖片會儲存在你的系統。詳細位置一般為: C:UsersMACHENIKEAppDataLocalTemp 中。
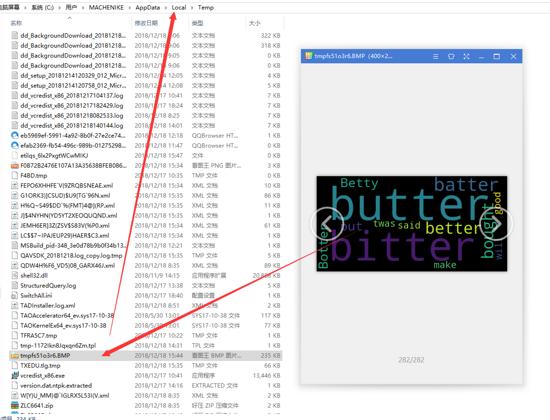
帶形狀的詞雲
一般來說,我們不想要這麼方的詞雲,肯定喜歡一些有形狀的,
接下來是生成那種有輪廓的詞雲,這裡就需要繼續匯入其他包,這裡匯入的包為numpy,numpy系統是python的一種開源的數值計算擴充套件,這種工具可以用來儲存和處理大型矩陣。這裡在處理的時候將給出形狀的圖片表示為一個大型矩陣,再有顏色的地方來進行填詞(導包 :import numpy as np)。導包之後需新增一個遮罩層,遮罩層就是用來限制生成圖片的形狀 。
網上隨便找個圖片放入到專案當中(這裡我找的是一個:heartpulse:),然後開始code:
from wordcloud import WordCloud
import PIL .Image as image
import numpy as np
with open("F:\minister.txt") as fp:
text = fp.read()
# print(text)
mask = np.array(image.open("F:\20180612151652413.png"))
wordcloud = WordCloud(
mask=mask
).generate(text)
image_produce = wordcloud.to_image()
image_produce.show()
結果如下:

不支援中文的解決方案
我又從網上摘抄了一段文字,文字內容如下:
生活星期天早上和朋友一起聊天,朋友說了一個他們聽過的故事:“一尊佛像前有一條鋪著石板的路,人們每天都踏著這一階一階的石板去膜拜佛像。石階看著人們踏著自己去膜拜佛像,心裡很不舒服。石階心裡想,自己和佛本來就來自同一塊石頭,為什麼自己要成為踏腳石,讓人們踩著自去去膜拜它呢!它對佛抱怨說這樣太不公平!佛像說:這沒有什麼不公平,你們成為臺階只需捱了四刀,而我是捱了千刀萬剮才成了人們膜拜的佛像。
重新執行,發現雪崩了。

如果需要生成中文的詞雲,還需匯入jieba分詞的包。jieba分詞的切分還是蠻準的。
進群:960410445 即可獲取數十套PDF!
from wordcloud import WordCloud
import PIL .Image as image
import numpy as np
import jieba
def trans_CN(text):
word_list = jieba.cut(text)
# 分詞後在單獨個體之間加上空格
result = " ".join(word_list)
return result;
with open("F:\minister.txt") as fp:
text = fp.read()
text = trans_CN(text)
# print(text)
mask = np.array(image.open("F:\20180612151652413.png"))
wordcloud = WordCloud(
mask=mask,
font_path = "C:\Windows\Fonts\msyh.ttc"
).generate(text)
image_produce = wordcloud.to_image()
image_produce.show()

C盤中有font字型,那麼這些呢你可以自己去找,trans_CN方法是分詞用的,通過font-path就可以指定裡面的生成文字。這大概就是詞雲的基礎了,可以將爬蟲和詞雲生成結合在一起,在爬取資訊之後生成這樣的詞雲。