
Hive資料庫和表DDL操作
阿新 • • 發佈:2018-12-28
一.資料庫
1.建立資料庫
- 建立一個數據庫,預設儲存路徑在/user/hive/warehouse
create database if not exists db_hive
- 在該資料庫下建立一張表
create table if not exists db_hive.sutdent(name string,id int);
## 2.資料庫查詢
- 顯示資料庫
show databases;
- 過濾顯示查詢的資料庫
show databases like 'db*';
- 檢視資料庫詳情
desc database db_hive;
- 顯示資料庫詳細資訊
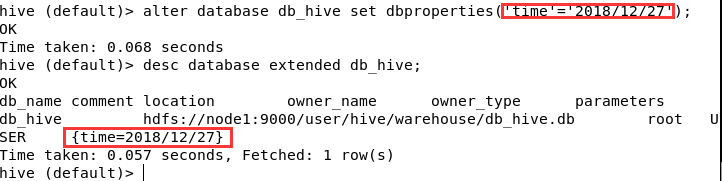
desc database extended db_hive;
- 切換當前資料庫
use db_hive;
## 3.修改資料庫
使用者可以使用 alter database 為某個資料庫的 dbproperties 設定鍵值對屬性值,來描述這個資料庫的屬性資訊,不像表,資料庫的其他元資料資訊都是不可修改的,如資料庫名和資料庫所在目錄位置,只能像這樣新增屬性。
alter database db_hive set dbproperties('time'='2018/12/27');
## 4.刪除資料庫
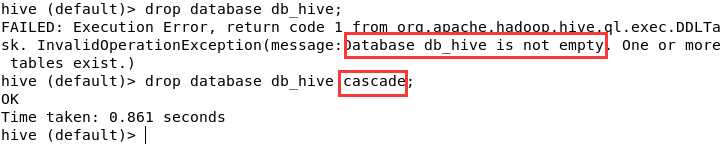
drop database db_hive;
但這樣只能刪除空資料庫,我們應該再刪除之前確認資料庫是否為空。
二.資料表
1.管理表
- 理論
預設建立的表都是管理表,也稱為內部表,刪除內部表的時候會將資料來源和元資料一起刪除,基於這個特性,內部表不適合用於共享 - 查詢表詳細資訊
desc formatted hive_student;
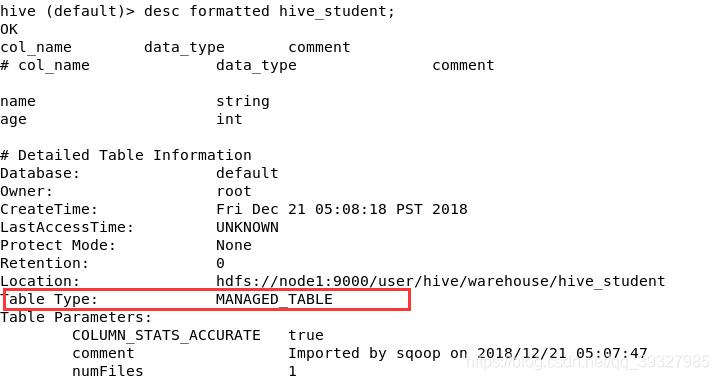
這張表是我用sqoop匯入的,在上面的commet中也可以看到
2.外部表
- 理論
因為是外部表(ENTERNAL),所以Hive並不認為其完全擁有這份資料,刪除該表不會刪除掉這份資料,而元資料是會被刪除的。 - 管理表和內部表的聯合使用
將網站每天的日誌資料定期流入HDFS文字檔案中,在外部表(原始日誌表)的基礎上做大量資料分析,用到的中間表和結果表使用內部表,資料通過SELECT+INSERT進入內部表。
3.內外部表之間的互相轉化
alter table hive_student set tblproperties('EXTERNAL'='TRUE');
4.分割槽表
分割槽表其實就是對應HDFS上獨立的一個資料夾,該資料夾下是該分割槽所有資料檔案。Hive中的分割槽就是分目錄,把一個大的資料集根據需求分成許多小的資料集,查詢時通過WHERE子句來選擇需要的分割槽,這樣效率會快得多。
- 建立分割槽表,在建立普通表的基礎上加上如下即可
partitioned by(month string) ##按月區分
然而在這之後,我們並不能立馬在HDFS該表目錄下看到任何資料夾,直到我們往裡面塞資料的時候,month資料夾才會顯示出來。
- 新增資料
load data local inpath '/root/apps/hive-1.2.2/data/student.txt' into table stu_partition partition(month=20181220);
- 查詢
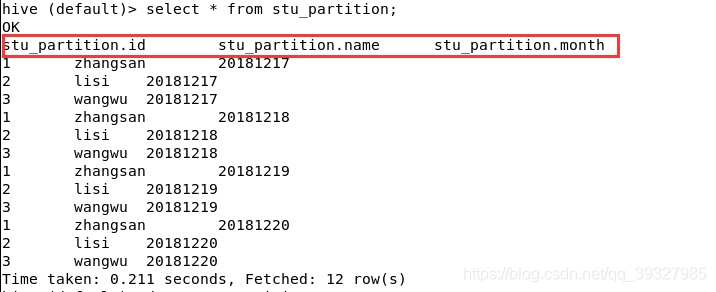
注意這裡,分割槽規則同樣作為表字段被查詢出來了。
然後,我們在語句末加上條件語句WHERE將會得到我們想要的結果,再接著,使用WHERE 條件1 OR 條件2可以查的兩份結果,這和SELECT * FROM TABLENAME WHERE 條件 UNION SELECT * FROM TABLENAME WHERE 條件得到的結果是一樣的,區別是UNION不為我們的結果做排序,底層呼叫的是mapreduce,比較耗時。 - 新增分割槽
我們不僅可以讓INSERT語句在插入資料的時候為我們建立分割槽,還能通過ADD新增分割槽,不過這個分割槽裡暫時是沒有資料的:
alter table stu_partition add partition(month=20181221) partition(month=20181222);
- 刪除分割槽
alter table stu_partition drop partition(month=20181222);
但是讓人感到費解的是,刪除多個分割槽的語句之間居然要用逗號連線,這不是讓人疲於記憶嗎
注意:在新增或刪除某分割槽下的分割槽時都用,並且並不屬於級聯刪除。
5.二級分割槽
- 建立二級分割槽(這和建立一級分割槽表並沒有多少差別)
partitioned by(month string,day int) ##按月和日區分
- 匯入資料
load data local inpath '/root/apps/hive-1.2.2/data/student.txt' into table stu1 partition(month=201812,day=21);
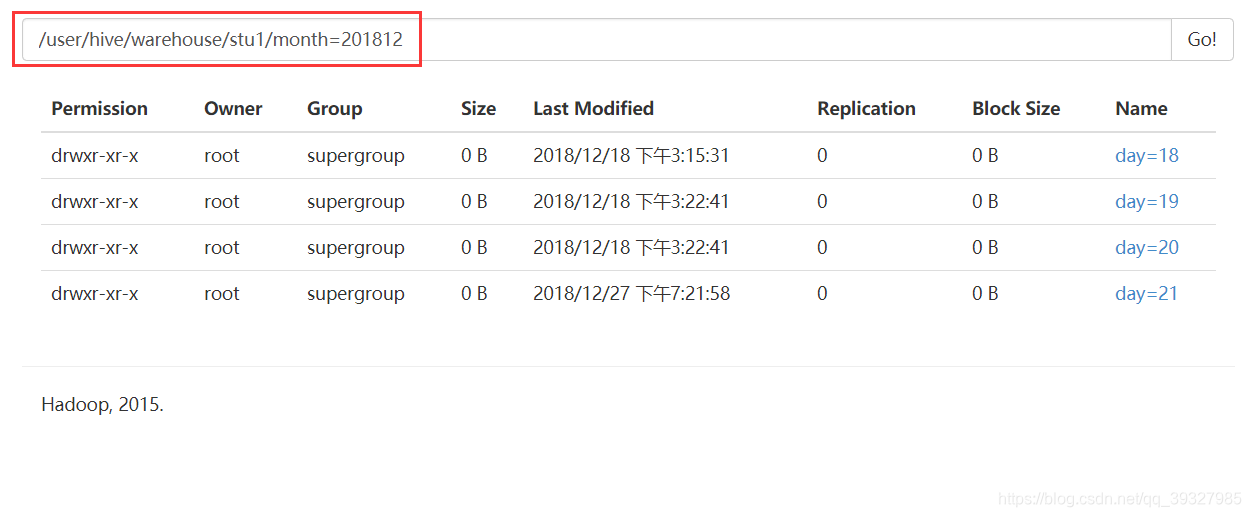
- 把資料直接上傳分割槽目錄後,讓分割槽表和資料產生關聯的三種方式
(1)上傳資料後修復
dfs -mkdir -p /user/hive/warehouse/stu1/month=201812/day=22;
dfs -put /root/apps/hive-1.2.2/data/student.txt /user/hive/warehouse/stu1/month=201812/day=22;
select * from stu1 where month=201812 and day=22;
#這裡是做一個比較,用於與之前建立未分割槽表之後再PUT資料上去做出區別

msck repair table stu1; #修復!
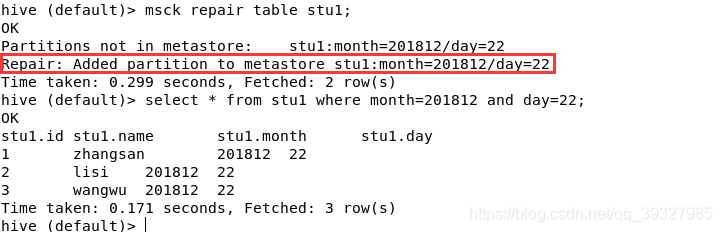
又能查到資料了呢!
注意:這種方式之所以適用於未分割槽表而不適用於分割槽表是因為它雖然會建立表的元資料資訊,但是卻沒有建立分割槽的元資料資訊,敲黑板,分割槽的元資料資訊!
(2)上傳資料後新增分割槽
dfs -mkdir -p /user/hive/warehouse/stu1/month=201812/day=23;
dfs -put /root/apps/hive-1.2.2/data/student.txt /user/hive/warehouse/stu1/month=201812/day=23;
alter table stu1 add partition(month=201812,day=23);
#手動新增分割槽
這樣也是可行的!
(3)load這種方式會自動建立分割槽資料夾,不多贅述了