
The Devil is in the JSON Details · The Factotum
The Devil is in the JSON Details · The Factotum
TL;DR: use I-JSON instead of “pure” JSON when designing a new API.
JSON is nowadays ubiquitous, and it’s impossible to find any programming language that doesn’t provide support for it. All modern APIs replaced the (in)famous XML with less cumbersome and more human-friendly JSON payloads, and even if it’s not the most performant or space-efficient data format we all agreed it’s de-facto
JSON is the acronym of JavaScript Object Notation and, and as its name suggests, it was derived from JavaScript and its original spec can be found at json.org. More than a decade after its creation we have two main specifications: RFC 8259 and ECMA-404. The three specs are broadly compatible except for some details, and all of them leave some details to the implementor.
Let’s go through some details that might lead to interoperability issues across different implementations of JSON:
Type of root value?
A valid JSON text can represent a single value, but the first specifications restrict this value to be only either an object or an array. This is not true anymore, and
RFC 8259 allows all values at the top-level.
A JSON text is a serialized value. Note that certain previous specifications of JSON constrained a JSON text to be an object or an array. Implementations that generate only objects or arrays where a JSON text is called for will be interoperable in the sense that all implementations will accept these as conforming JSON texts.
ECMA-404 does not explicitly define it.
JSON.org allows only objects and arrays.
JSON is built on two structures:
- A collection of name/value pairs. [ … ]
- An ordered list of values. In most languages, this is realised as an array, vector, list, or sequence.
Always use an object or an array as top-level value to support any JSON decoder.
Duplicate names and ordering
An object is a map name-value where the name is a string. None of the specs forces the names to be unique, so decoders need to deal with data like:
{ "name": "foo", "name": "bar", "name": "spam" }Which name should the decoder pick? The three specs do not define this behaviour and let the implementors take a decision, but it looks like most implementations converge to always selecting the last one.
RFC 8259 only suggests not to allow duplicate names.
A single comma separates a value from a following name. The names within an object SHOULD be unique.
An object whose names are all unique is interoperable in the sense that all software implementations receiving that object will agree on the name-value mappings.
When the names within an object are not unique, the behaviour of software that receives such an object is unpredictable. Many implementations report the last name/value pair only. Other implementations report an error or fail to parse the object, and some implementations report all of the name/value pairs, including duplicates.
ECMA-404 does not require the names to be unique and does not give any instruction on how to manage them.
The JSON syntax does not impose any restrictions on the strings used as names, does not require that name strings be unique, and does not assign any significance to the ordering of name/value pairs
JSON.org is not clear if the pairs in the set are unique by name.
An object is an unordered set of name/value pairs
Never allow duplicate names in your JSON object.
What’s a number?
JSON defines a single type number used to represent integers and floats. The specs do not set specify a range of valid values or their precision; therefore this depends on the implementation you are using.
RFC8259 allows implementations to decide which limits to apply for JSON numbers and it warns about issues that might arise when dealing with floating points.
This specification allows implementations to set limits on the range and precision of numbers accepted. Since software that implements IEEE 754 binary64 (double precision) numbers [IEEE754] is generally available and widely used, good interoperability can be achieved by implementations that expect no more precision or range than these provide, in the sense that implementations will approximate JSON numbers within the expected precision.
A JSON number such as 1E400 or 3.141592653589793238462643383279 may indicate potential interoperability problems since it suggests that the software that created it expects receiving software to have greater capabilities for numeric magnitude and precision than is widely available.
Numeric values that cannot be represented in the grammar below (such as Infinity and NaN) are not permitted.
ECMA-404 delegates any limit or precision to the implementation too.
JSON is agnostic about the semantics of numbers.
In any programming language, there can be a variety of number types of various capacities and complements, fixed or floating, binary or decimal. That can make interchange between different programming languages difficult.
JSON instead offers only the representation of numbers that humans use: a sequence of digits. All programming languages know how to make sense of digit sequences even if they disagree on internal representations. That is enough to allow interchange.
Numeric values that cannot be represented in the grammar below (such as Infinity and NaN) are not permitted.
JSON.org provides a basic definition without any details about interoperability.
A number is very much like a C or Java number, except that the octal and hexadecimal formats are not used.
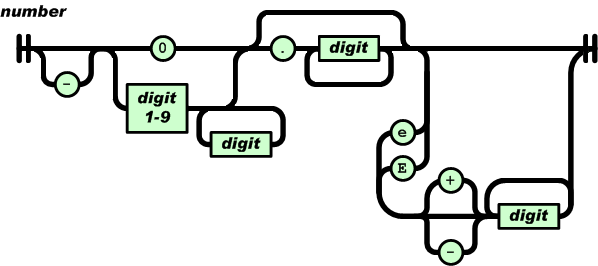
If precision is a must in your application, you should use an implementation that supports fixed-point decimals or decode numbers as strings to avoid any automatic decoding into floats in the clients.
It’s worth noting that NaN and Infinity are not supported (Spoiler Alert: there’s an implementation that supports them).
The implementation details
In the repository check-json, you can find a test-suite to checks the implementation details discussed above. The test suite runs against an executable that is supposed to decode the JSON text passed in the standard input and re-encode it writing the result in the standard output. If the implementation can’t handle the de/encoding, it will return a non-zero exit code.
The following tests have been used to check the details I discussed above:
Test Input Number as top-level value 1 String as top-level value "hello" NaN keyword {"foo":NaN} Infinity keyword {"foo":Infinity} Number precision {"pi":3.14... } 60 digits Big integer {"big": 314... } 840 digits Hexadecimal notation {"hex":0xff} Octal notation {"oct":0777} Binary notation {"bin":0b0110} Duplicate members: keep last {"aaa": 1, "aaa": 2} Duplicate members: keep first {"aaa": 1, "aaa": 2}
Python
The standard Python module json implements a keep-last policy for duplicate names, and it can manage big integers, but as expected it uses the type float when parsing numbers. Everything seems fine except for the big WAT when you realise it can parse NaN and Infinity. The docs do warn about this behaviour:
It also understands NaN, Infinity, and -Infinity as their corresponding float values, which is outside the JSON spec.
and it allows developers to override the default behaviour setting allow_nan=False in json.JSONEncoder. Honestly, I’d expect to have the safest default value in json.dumps.
Test Output RFC 8259 ECMA-404 JSON.org Number as top-level value 1 OK OK Error String as top-level value "hello" OK OK Error NaN keyword {"foo":NaN} Error Error Error Infinity keyword {"foo":Infinity} Error Error Error Number precision {"pi":3.141592653589793} Invalid Invalid Invalid Big integer {"big":3141592653589793...} OK OK OK Hexadecimal notation Error OK OK OK Octal notation Error OK OK OK Binary notation Error OK OK OK Duplicate members: keep last {"aaa":2} OK OK OK Duplicate members: keep first {"aaa":2} Invalid Invalid Invalid
After setting allow_nan=False the two tests pass:
Test Output RFC 8259 ECMA-404 JSON.org NaN keyword Error OK OK OK Infinity keyword Error OK OK OK
JavaScript
Node shows only one weirdness when it uses null as fallback value when it can’t serialise a given value, that’s why the big integer appears as null in the encoded value.
Test Output RFC 8259 ECMA-404 JSON.org Number as top-level value 1 OK OK Error String as top-level value "hello" OK OK Error NaN keyword Error OK OK OK Infinity keyword Error OK OK OK Number precision {"pi":3.141592653589793} Invalid Invalid Invalid Big integer {"big":null} Invalid Invalid Invalid Hexadecimal notation Error OK OK OK Octal notation Error OK OK OK Binary notation Error OK OK OK Duplicate members: keep last {"aaa":2} OK OK OK Duplicate members: keep first {"aaa":2} Invalid Invalid Invalid
This also happens with NaN and Infinity when serialised so you may lose them in translation without any visible error.
> JSON.stringify({"nan": NaN}) '{"nan":null}' > JSON.stringify({"inf": Infinity}) '{"inf":null}'Ruby
Ruby’s JSON standard library supports only object and arrays as top-level values, the only one amongst the tested languages to have this old constraint.
Test Output RFC 8259 ECMA-404 JSON.org Number as top-level value Error Invalid Invalid OK String as top-level value Error Invalid Invalid OK NaN keyword Error OK OK OK Infinity keyword Error OK OK OK Number precision {"pi":3.141592653589793} Invalid Invalid Invalid Big integer {"big":3141592653589793...} OK OK OK Hexadecimal notation Error OK OK OK Octal notation Error OK OK OK Binary notation Error OK OK OK Duplicate members: keep last {"aaa":2} OK OK OK Duplicate members: keep first {"aaa":2} Invalid Invalid Invalid
However, this constraint has not been implemented in Ruby On Rails that allows any type as top-level value.
Test Output RFC 8259 ECMA-404 JSON.org Number as top-level value 1 OK OK Error String as top-level value "hello" OK OK Error
Go
The go implementation doesn’t have many surprises. It doesn’t support big integers by default, so you’ll need to call Decode.UseNumber before decoding the data to avoid any information loss.
Test Output RFC 8259 ECMA-404 JSON.org Number as top-level value 1 OK OK Error String as top-level value "hello" OK OK Error NaN keyword Error OK OK OK Infinity keyword Error OK OK OK Number precision {"pi":3.141592653589793} Invalid Invalid Invalid Big integer Error Invalid Invalid Invalid Hexadecimal notation Error OK OK OK Octal notation Error OK OK OK Binary notation Error OK OK OK Duplicate members: keep last {"aaa":2} OK OK OK Duplicate members: keep first {"aaa":2} Invalid Invalid Invalid
After calling Decode.UseNumber both tests passed.
Test Output RFC 8259 ECMA-404 JSON.org Number precision {“pi”:3.141592653589793…} OK OK OK Big integer {“big”:3141592653589793…} OK OK OK
Rust
Rust doesn’t support JSON in its standard library, but its main de/serializer framework serde provides a JSON implementation serde_json. The default behaviour is the same we’ve seen in Go, and if we want to avoid any information loss when treating numbers, we can enable the feature arbitrary_precision in serde_json.
Test Output RFC 8259 ECMA-404 JSON.org Number as top-level value 1 OK OK Error String as top-level value "hello" OK OK Error NaN keyword Error OK OK OK Infinity keyword Error OK OK OK Number precision {"pi":3.141592653589793} Invalid Invalid Invalid Big integer Error Invalid Invalid Invalid Hexadecimal notation Error OK OK OK Octal notation Error OK OK OK Binary notation Error OK OK OK Duplicate members: keep last {"aaa":2} OK OK OK Duplicate members: keep first {"aaa":2} Invalid Invalid Invalid
After I replace serde_json = "1.0.32" with serde_json = { version = "1.0.32", features = ["arbitrary_precision"] } in my Cargo.toml both tests passed.
Test Output RFC 8259 ECMA-404 JSON.org Number precision {“pi”:3.141592653589793…} OK OK OK Big integer {“big”:3141592653589793…} OK OK OK
Conclusions
These cases might be often labelled as edge cases, but soon or later they’ll bite you back. I-JSON, defined in RFC 7493, adds a set of constraints to the standard JSON spec like:
- Do not use integer outside the range [-(253)+1, (253)-1]).
- Do not use numbers that cannot be expressed IEEE 754 double precision numbers.
- Use strings when dealing with numbers that cannot be expressed because of the above constraints.
- Do not allow objects to have duplicate names, and their order must not matter.
- Allow any type as top-level value but suggests to use only objects and arrays.
You should consider I-JSON when designing a new protocol or API based on JSON to reach a good level of interoperability.
Note: I ignored all the issues related to character encoding because they have been discussed extensively in many articles and they’d deserve an article on their own.