
Learning from Machine Learning
Learning from Machine Learning
What a recent experience with some real data taught me.


I recently understood what the curse-of-dimensionality meant! I started working with some data that was very normal at first glance — just over 100,000 rows and 448 variables. The task was fairly straight forward — Given some (actually quite some) variables predict an outcome variable that can be 0 or 1. Easy peasy!
But then it struck me — 448 columns! How do I even begin to make sense of what’s going on? The goal of prediction was not just to build a very accurate model but also to see what explains the outcome. Having played with mostly toy data, the task ahead seemed dangerous.
Data Dictionary to the rescue
I have learnt (nothing to be really proud of) that one of the first things that needs be done is a quick glance at the column names and not-so-quick glance at the data dictionary — mostly an excel sheet that tells you what each variable means. The longer you spend absorbing this dictionary, the more you stand a chance to head off in the right direction with your analysis.
What are my variables like?
Once it is clear what you are dealing with, it pays to look at the data types for your columns. Why? Well for one it would tell you how many of the variables you have are pesky categorical ones and whether a variable has a data type that it shouldn’t. For instance, there could be a variable like ‘Type of insurance’ that has values of 1,2,3,4 even though the type has nothing to do with numerical data. Furthermore, the values 1,2,3, and 4 imply an inherent ordering which is not true for categorical variables.


One way to deal with this is shown below. This produces a beautiful bar chart telling us how many variables of what data type we have! Pro tip — For this bar chart we don’t actually need the y-axis ticks but I am feeling lazy today.
# df is the dataframe that you have
import matplotlib.pyplot as pltplt.figure(figsize = (10,6))ax = df.dtypes.value_counts().plot(kind = 'bar', rot = 0)ax.set_title('Data Types', fontsize = 15)ax.set_ylabel('# Columns', fontsize = 13)# each bar is a rectangle (in plotting parlance)rects = ax.patches
# Make some labels for your bar chartlabels = df.dtypes.value_counts().tolist()
# loop through each bar and put a label on itfor rect, label in zip(rects, labels): height = rect.get_height() ax.text(rect.get_x() + rect.get_width() / 2, height, label, ha='center', va='bottom')

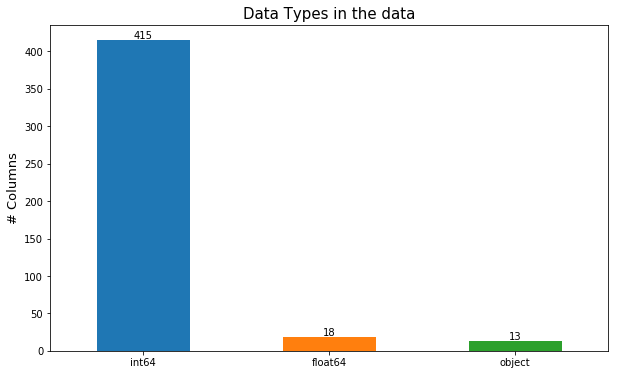
But what do I do in case the variable is incorrectly represented as numeric when it should be categorical?
Given that the data dictionary is actually of any use, it would tell you what each of the number represents, i.e. what insurance type maps to each number. Once you have that, its just a short code towards glory -
# give the computer a dictionary with number to type mappinginsurance_map = {1:'Type A', 2: 'Type B', 3: 'Type C', 4: 'Type D'}# use that mapping and transform your variabledf['insurance_type'] = df['insurance_type'].map(insurance_map)
Voila, your numbers are now transformed into insurance types and it makes much more sense now!
Divide your data into test and train data
To get a realistic expectation of how your data performs on unseen data, the BEST practice is to divide your data into test/validation and train sets. Use 80%–20% or 70%–30% for train-test split as per the data.
I did this before I even imputed the missing data because of a concept called data leakage. Among other things, it says that validation data should not impact in any way the data we use to train our models aka the training data. If we use all the data even to impute missing values, that violates this principle. So, divide your data into two parts and proceed with what comes next. Since we randomly divide our data into test and train subsets, it is safe to assume that missing values will be in the same variables for both of them.
Missing Data
If there’s one thing that I DO NOT enjoy doing, its this. And if there’s one thing that you cannot avoid, it’s still this! So what do we do? First, we need to check whether our data has missing values (please god tell me there’s none!)


# this jazzy piece of code returns missing rows by column and # percentage of missing rows in each column (if any)
def missing_check(df): # this gets a column wise sum of missing values missing_df = df.isnull().sum().reset_index() missing_df.columns = ['variable', 'missing_values'] missing_df['Total_Rows'] = len(df) missing_df['Perc_Missing'] = missing_df['missing_values']*100/len(df) # sorts the columns in descending order of missing rows missing_df.sort_values('Perc_Missing', ascending = False, inplace = True) missing_df = missing_df.loc[missing_df['Perc_Missing']>0, :].reset_index(drop = True) if len(missing_df) == 0: return "No columns with missing values" else: return missing_dfLook into missing data
If it was not bad enough that some of the data is missing, what adds to the misery is that data can be missing in three ways — 1. Missing Completely at Random (MCAR) — This means that the missing data has no relationship with any observed or unobserved values in the data. What this entails is that the distributions of the observed data and the missing data are the same.
2. Missing at Random (MAR) — This means that the missing values have some relationship with some of the other observed variables. For this case, we can use these other variables to predict the values that are missing.
3. Missing Not at Random (MNAR) — Missing not at random means that the missing values are related to the values that are missing. For ex- Missing age for a study on alcoholism. We know that underage people would be more likely to not reveal their age. For this, the distribution of the variable with the missing values (if they were not missing) would be different than what it is.
Huh, What?
Okay, so down to the practical stuff! If a categorical variable had missing values I did the following —
- Variable Encoding — One hot encoding or label encoding
This is a step that has to be done eventually for us to use categorical variables in our models. Why I like it is that gives me each value of the variable as a new column — even the NAs. This works because unless a categorical variable is absolutely obvious to decipher from another variable (like maybe gender from a name if the name has Mr./ Ms. as a prefix), it is usually difficult to predict accurately.
We use Label encoding if we have just two unique levels in the variable — it will give them values of 1/2 or 0/1. One-Hot Encoding creates a 1/0 type variable for each level in a categorical variable. For example — insurance type gives rise to 4 new variables — insurance_type_a, insurance_type_b, etc.
How do we do this? First we check how many unique values are in our variable.
# Check how many levels are in the datadf.select_dtypes('object').apply(lambda x: pd.Series.nunique(x, dropna = False))For variables with two unique values, we use Label Encoding-
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()count_le = 0
# select categorical variablesobj_cols = df_train.select_dtypes('object').columns.tolist()# for each categorical variable check if there are 2 unique values# and then apply the encoder
for col in obj_cols: if len(df_train[col].unique()) <= 2: df_train[col] = le.fit_transform(df_train[col]) df_test[col] = le.transform(df_test[col]) count_le += 1 print("Columns with label encoding:", count_le)What would be left are variables with more than two unique values, so we use pandas’ get_dummies function —
# this will automatically detect categorical variables and # create new variables - one for each unique value in the variable
df_train = pd.get_dummies(df_train)df_test = pd.get_dummies(df_test)
Notice that at this stage, all our variables are numeric.
2. Add an indicator to mark rows where variables had a missing value
# this adds a 1/0 flag depending on whether a missing value is found. I use dfdf_train.loc[:, loan_amt_missing] = np.where(df_train[loan_amt].isna(), 1, 0)df_test.loc[:, loan_amt_missing] = np.where(df_test[loan_amt].isna(), 1, 0)
3. Get Correlations between variables with missing values and those without.
# 'vars_without_missing' are variables with no missing values# 'variable' is the variable with the missing value
correlations = df_train[vars_without_missing].corrwith(df_train[variable]).sort_values(ascending = True)
4. Choose predictors with some correlation with the missing variable and use those to predict it
The code for this one is particularly long and doesn’t demonstrate any unique Python magic so I will just go over the concept. Once correlations are found, pick variables that correlate well (use a threshold) with the missing variable and use those to predict the outcome. I used linear regression but k-nearest neighbors could be an alternative too.
For variables that showed no significant correlation with other variables, I resorted to using their medians as a safe imputation value. Note that we use just the training data to calculate the median of the variable and use the same median to impute values in the training data as well.
# imputing and avoiding data leakagefrom sklearn.preprocessing import Imputerimputer = Imputer(strategy = 'median') # impute the missing valuesdf_train_imputed = imputer.fit_transform(df_train)df_test_imputed = imputer.transform(df_test)
The code fits the ‘imputer’ (calculates the median) on the training data and then uses that value to impute missing values in the test data!
5. Check the range of the imputed variables
Once you have imputed missing rows with some values, make sure to check their summary statistics before and after imputing. If the ranges change radically, something has gone wrong and the imputation would need to be done again. We can check the distribution of the variable where we imputed the missing values and ideally one should expect the imputed values to follow the same distribution as the other values in the variable.
6. Align your data frames
And now comes the critical part. To make sure that predictions work correctly on the testing/validation data, we need to make sure that the variables we use in the training data are also present in the testing data. Python has a very handy function to do this called ‘align’ ! Here’s how you use it -
# this tells you if variables mismatch between the dataframeslist(set(X_train_encoded.columns) - set(X_test_encoded.columns))
# this aligns the columns between the df_train_imputed # and df_test_imputeddf_train_imputed, df_test_imputed= df_train_imputed.align(df_test_imputed, join = 'inner', axis = 1)
This function is truly useful to single out those pesky (pestering, annoying, vexing) values in categorical data that are so infrequent as to appear in either one of train or test but not the other. This way, we can either go back replace the rare value with another similar value or totally discard that value as the code above shows.
And there you go!
At this point you have a cleaned data-frame, with categorical variables encoded, missing values imputed and columns aligned between the training and validation data! You are ready to train those godly models on this now! Thanks for reading! :)