
A Journey to Better Deployments
For the past year, we’ve been working to improve our deployment process. Over that time we’ve built custom tooling and started using new (and said goodbye to old) tools and practices. This post will try and give an overview of why we wanted a new deployment process, how we went about implementing it and what we have now.
The Old System
Infrastructure
Our infrastructure was built using CloudFormation. CloudFormation templates were generated from CFNDSL, which in turn were wrapped in an in-house Ruby Gem which made it a little easier to work with.
A CloudFormation stack generally produced an Auto Scaling Group, fronted by a Classic Load Balancer, with associated Security Groups and IAM roles and profiles.
CloudFormation was also used to set up other parts of our AWS infrastructure, such as VPC networking, CloudFront distributions and S3 Buckets.
All of our instances were managed by Chef. Chef ran every 15 minutes to configure our systems as we specified, it controlled every aspect of the machine. That means managing the configuration of the OS, installing system packaging and ensuring our instances were kept up to date and patched. It is also responsible for installing and configuring our applications.
Deployments
All deployments were orchestrated by Chef. When a deployment happened it was controlled by us and happened in one of three ways:
- Environments could be set up to take the latest available package on each Chef run. We used this to deploy the latest versions of our code when a Jenkins builds completed.
- Deployments to other development environments were made using either a Web UI or via a CLI — Knife plugin — (both effectively using the same Ruby code underneath) which told Chef to deploy a specific version of code and configuration.
- Production deploys were driven via command line on developers machines using a Knife plugin. This allowed a higher degree of control over the deployment. For instance, a deploy typically consisted of a canary node being deployed, a developer checking the logs and metrics before deciding whether or not to continue the deploy. If the deployment was continued then a rolling deploy to the remaining instances was started. Otherwise, the canary was rolled back.
Why Develop a New Deployment Process?
Faster Deployments
Each deploy required a full Chef run, meaning we were checking all other parts of the system, just to install a Jar and a YAML configuration file and restart a service.
Deploys from CI took too long, Chef ran every 15 minutes, which means we waited, on average 7.5 minutes for a deployment to start, after a new version had been published. Developers want to see if their code works ASAP.
Production deployments took a long time:
- We took an instance out of the load balancer
- Ran chef
- Added the instance back in the load balancer
- Waited for a developer to check the logs
- Repeated steps 1–3 for the remaining instances (or rollback)
Safer Deployments
Chef managed servers are mutable — they change over time. We were never 100% certain if we could build a new instance from scratch to the current state, this can lead to problems when machines (inevitably) die, or when we needed to scale up new instances.
Production deployments were run from developers machines, which meant there were any number of number of factors that caused problems for deployments, such as:
- Did the developer have all the pre-requisites installed?
- Did they have the correct AWS credentials?
- Was their network connection stable? What happened if it dropped out part way through a deployment?
We relied heavily on developers checking logs and metrics to confirm that the new version we were deploying was working as expected. Much of this could be automated.
The New System
Targets
We set our requirements for our deployment system as:
- Deployments should happen in seconds or minutes (not 10’s of minutes or longer)
- Deployments should not be run from a developers machine
- We should deploy Immutable instances
- Automate as many post-deployment checks as possible
Phase 1
As we wanted immutable instances it was clear that we needed to bake application code into AMIs (Amazon Machine Images). We’d then need to orchestrate the deployment of these AMIs. We decided to use Spinnaker to do this. Spinnaker is “an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence”.
Essentially it allows you to define a pipeline defining how you want a deployment to happen.
A minimal Pipeline consists of a Bake stage and a deployment stage. A deployment stage can be made of a number of different deployment strategies that are built in (for example Red/Black, Canary or Highlander) or you can define your own. You’re also free to add other steps, such as adding optional steps to rollback or steps that can perform checks.
By using Spinnaker it is clear we are going to be able to meet our goals:
- Deployments of Baked AMIs should be fast using Spinnaker
- Safe as we can promote an AMI through environments
- Our instances are immutable
- We’re also not running these deployments from our own machine
But we haven’t done much in terms of automating deployment checks.
We quickly found that whilst the Spinnaker UI was perfect for our DevOps team to use, there is too much unnecessary information in there for many users (members of development teams that are just interested in deploying code, not the details of how the deployments work).
We decided to build a system to wrap Spinnaker (and any future deployment types) in order to abstract away some of the complexities of tools like Spinnaker and also to overlay some of the terminology used by development teams.
We chose to build an API, based on Ruby on Rails, which which will store information about our environments and services as well as allowing us to use background workers to track the state of deployments.
In front of the API we’ve built a React application, which acts as the primary user interface to the API.
Pause and Reflect
We now had a working deployment system, but before we continued we took time to pause and review our progress with our users. People had been used to our old deployment system and like any change it can be difficult to adjust. Many things that seem intuitive when developing a system turn out not to be for users.
From this process, we came up with a few things we wanted to change:
- The time to the first deployment (after a CI build of our application) is still too high. Baking an AMI can take several minutes, meaning we are only slightly faster than Chef deployed instance.
- Our Web interface required some work to become more intuitive and better display information to users.
- Integration between tools could be better. For instance, Jenkins jobs were starting Spinnaker deployments directly, skipping our own tooling.
This feedback has led to a number of improvements.
Phase 2
‘Trigger’ Deploy
To speed up the first deployment times we’ve had to make some compromises. We realised that we were never going to make AMI baking fast enough, so instead we’ve broken one of our initial requirements — immutable instances — in the interest of speed.
We’ve developed a deployment strategy which we have dubbed Trigger Deploy. The full workings of Trigger Deploy could make an entire blog post on their own, so I won’t go into too much detail here.
Essentially we pass a message to long-lived instances via SNS and SQS to deploy a new version of a package. Each instance listens to the queue for a message that it’s interested in and then acts upon it.
This means that we now deploy in seconds following a successful CI build of code. But we’re a little more prone to errors, in this case, we feel it’s an acceptable compromise.
Web Interface
We actively solicited feedback in both face-to-face sessions and via a feedback button embedded in the tool to collect a lot of feedback from our users about how we can improve the UI. Such as where we navigate the user to after certain actions and how we lay out information so that it’s easy to read, balancing providing all the information a user needs with not overloading them.
We also pulled in additional information, such as the current state of an environment.
This is an ongoing exercise. Gathering and acting on user feedback through meetings, a feedback sheet and ad-hoc conversions means that we’re always improving the system.
Tooling Integration
We wanted our deployment API to be the central source of information for all deployments — deploys should be started, controlled by and monitored via the API. One way of doing this was through the React UI. But sometimes this doesn’t cut it — we need to programmatically interact with the API, for instance, if we want Jenkins to start a deployment after a CI build.
Of course, this could be achieved via the API, but dealing with authentication and setting up each Jenkins job was more difficult than just calling Spinnaker directly (Spinnaker jobs can be set up to trigger from Jenkins builds)
So we built a CLI, this lets us abstract most of the pain away from Jenkins calling the API directly and also gives users the option of using the CLI rather than having to use the UI.
Terraform
We’ve also started using Terraform, rather than CloudFormation for building out infrastructure. One of the primary benefits this gives us is being able to share information between stacks using remote state, rather than have a global configuration file. Other benefits include the use of modules, which give us a better interface than our old CloudFormation templates.
A side effect of using Spinnaker is that out stacks are a little simpler, in that we don’t have to create the Auto Scaling Group, as Spinnaker manages that for us.
API
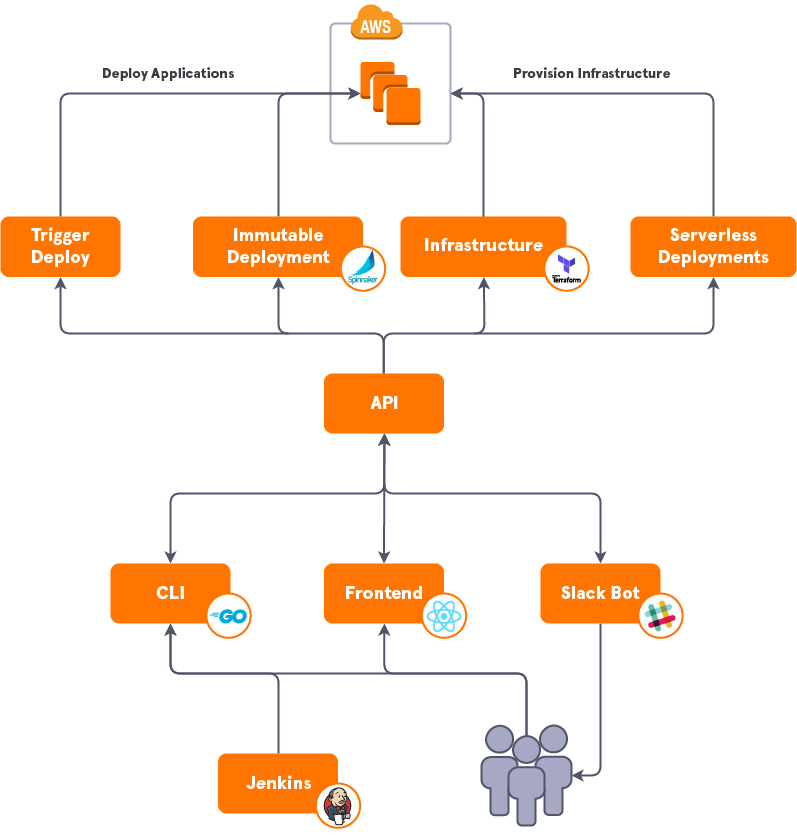
The API has now become the glue that holds our deployments together. It is the source of truth for all deployment related activities.
Not only does it orchestrate Spinnaker and ’Trigger’ deployments, it has been built in such a way we can add new deployment types as we go. We currently have prototypes for deploying AWS Lambda applications using SAM and for running Terraform.
We’re also investigating how we can manage the configuration of our services via the API.
With the API at the centre of our deployment workflow we have been able to leverage it to create a number of tools, such as the React frontend, a Golang CLI and a Lambda based Slack bot.
Conclusion
The result of our work so far is that deployments are faster, it takes just a few seconds to deploy following a new version of the code being made available.
It takes a few minutes for the next environment, but we have a lot more confidence that the deployment will be successful.
Prod deployments are no longer run from a user’s machine and are faster than they used to be. We haven’t made as much progress as we’d have liked when it comes to the automated checking of the deployments health, this is something we’ll continue to work on going forward.
Going through this process has highlighted how important it is to check in with your users at regular intervals to see if you are meeting their requirements.
This is just the beginning of the journey to better deployments, we’ve laid a solid foundation, which we can build on to enable us to manage different deployment types as well as to continue to make deployments faster and safer.