
Dance x Machine Learning: First Steps
Dance x Machine Learning: First Steps
Creating new datasets and exploring new algorithms in the context of the dance performance “discrete figures”
In February 2018 Daito Manabe wrote me an email with the subject “Dance x Math (ML)”, asking if I’d be interested in working on a new project. I have some background working in the context of dance in the past, including

I was very excited for the possibility of working with Mikiko, and Elevenplay, and again with Daito. Daito and Mikiko shared some initial ideas and inspiration for the piece, especially ideas emerging from the evolution of mathematics. Starting with the way bodies have been used for counting since prehistory, all the way through Alan Turing’s impressions of computers as an extension of human flesh, into modern attempts to categorize and measure the body with algorithms in the context of surveillance and computer vision.

After long conversations around these themes, we picked the name discrete figures to play on the multiple interpretations of both words. I focused on two consecutive scenes toward the end of the performance, which we informally called the “debug” scene and “AI dancer” scene. The goal for these two scenes was to explore the possibilities of training a machine learning system to generate dances in a style similar to Elevenplay’s improvisation. For the performance in Tokyo, we also added a new element to the debug scene that includes generated dance sequences based on videos captured of the audience before the performance. In this writeup I’ll provide a teardown of the process that went into creating these scenes.
Background
There is a long history of interactive and generative systems in the context of dance. Some of the earliest examples I know come from the “9 Evenings” series in 1966. For example, Yvonne Rainer with “Carriage Discreteness”, where dancers interacted with lighting design, projection, and even automated mechanical elements.


More recently there are artist-engineers who have built entire toolkits or communities around dance. For example, Mark Coniglio developed Isadora starting with tools he created in 1989.


Or Kalypso and EyeCon by Frieder Weisse, starting around 1993.
I’ve personally been very inspired by OpenEnded Group, who have been working on groundbreaking methods for visualization and augmentation of dancers since the late 1990s.

Many pieces by OpenEnded Group were developed in their custom environment called “Field”, which combines elements of node-based patching, text-based programming, and graphical editing.
AI Dancer Scene
For my work on discrete figures I was inspired by a few recent research projects that apply techniques from deep learning to human movement. The biggest inspiration is called “chor-rnn” by Luka and Louise Crnkovic-Friis.

In chor-rnn, they first collect five hours of data from a single contemporary dancer using a Kinect v2 for motion capture. Then they process the data with a common neural network architecture called LSTM. This is a recurrent neural network architecture (RNN) which means it is designed for processing sequential data, as opposed to static data like an image. The RNN processes the motion capture data one frame at a time, and can be applied to problems like dance-style classification or dance-generation. “chor-rnn” is a pun from “char-rnn”, a popular architecture that is used for analyzing and generating text one character at a time.
For discrete figures, we collected around 2.5 hours of data with a Vicon motion capture system at 60fps in 40 separate recording sessions. Each session is composed of one of eight dancers improvising in a different style: “robot”, “sad”, “cute”, etc. The dancers were given a 120bpm beat to keep consistent timing.

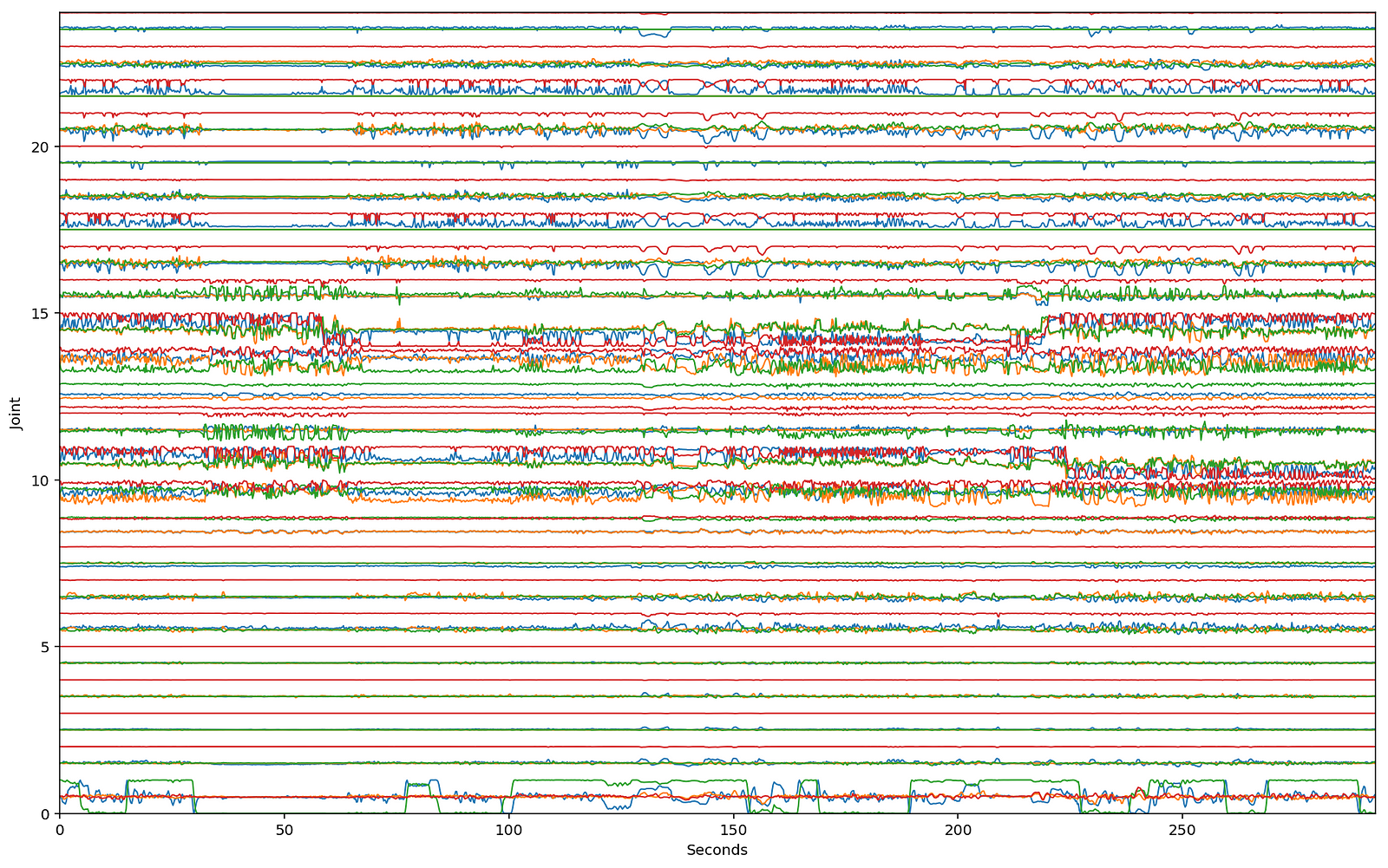
This data is very different than most existing motion capture datasets, which are typically designed for making video games and animation. Other research on generative human motion is also typically designed towards this end, for example, “Phase-Functioned Neural Networks for Character Control” from the University of Edinburgh takes from a joystick, 3d terrain, and walk cycle phase and outputs character motion.

We are more interested in things like the differences between dancers and styles, and how rhythm in music is connect to improvised dance. For our first exploration in this direction, we worked with Parag Mital to craft and train a network called dance2dance. This network is based on the seq2seq architecture from Google, which is similar to char-rnn in that it is a neural network architecture that can be used for sequential modeling.
Typically, seq2seq is used for modeling and generating language. We modified it to handle motion capture data. Based on results from chor-rnn, we also used a technique called “mixture density networks” (MDN). MDN allows us to predict a probability distribution across multiple outcomes at each time step. When predicting discrete data like words, characters, or categories, it’s standard to predict a probability distribution across the possibilities. But when you are predicting a continuous value, like rotations or positions, the default is to predict a single value. MDNs give us the ability to predict multiple values, and the likelihood of each, which allows the neural network to learn a more complex structure to the data. Without MDNs the neural network either overfits and copies the training data, or it generates “average” outputs.
One big technical question we had to address while working on this was how to represent dance. By default, the data from the motion capture system is stored in a format called BVH, which provides a skeletal structure with fixed length limbs and a set of position and rotation offsets for every frame. The data is mostly encoded using rotations, with the exception of the hip position, which is used for representing the overall position of the dancer in the world. If we were able to generate rotation data with the neural net, then we could generate new BVH files and use them to transform a rigged 3D model of a virtual dancer.

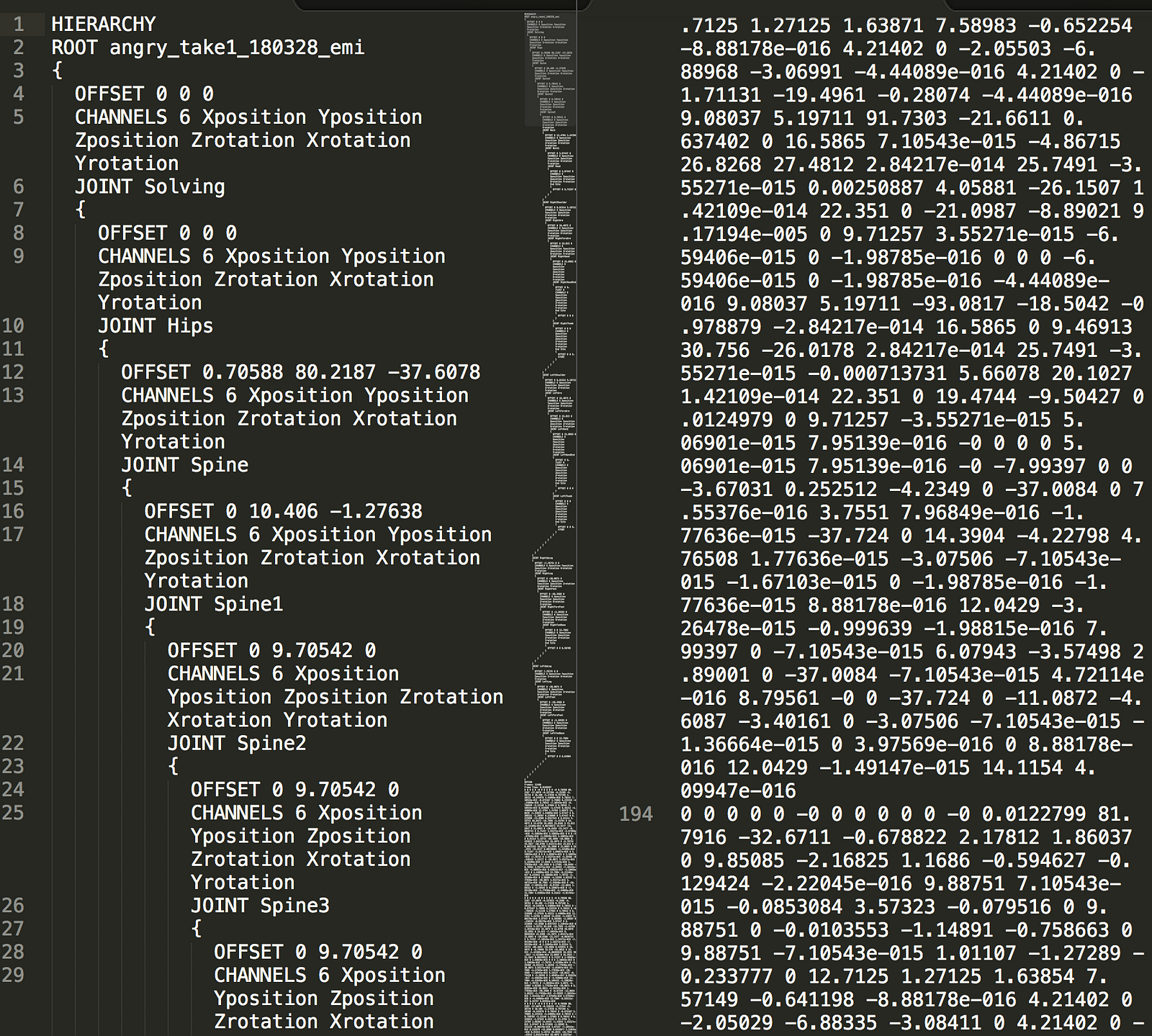
chor-rnn uses 3D position data, which means that it is impossible to distinguish between something like an outstretched hand that is facing palm-up vs palm-down, or whether the dancer’s head is facing left vs right.
There are some other decisions to make about how to represent human motion.
- The data: position or rotation.
- The representation: for position, there are cartesian and spherical coordinates. For rotation, there are rotation matrices, quaternions, Euler angles, and axis-angle.
- The temporal relationship: temporally absolute data, or difference relative to previous frame.
- The spatial relationship: spatially absolute data, or difference relative to parent joint.
Each of these have different benefits and drawbacks. For example, using temporally relative data “centers” the data making it easier to model (this approach is used by David Ha for sketch-rnn), but when generating the absolute position can slowly drift.
Using Euler angles can help decrease the amount of variables to model, but angles wrap around in a way that is hard to model with neural networks. A similar problem is encountered when using neural networks to model the phase of audio signals.
In our case, we decided to use temporally and spatially absolute quaternions. Initially we had some problems with wraparound and quaternion flipping, because quaternions have two equivalent representations for any orientation, but it is possible to constrain quaternions to a single representation.
Before training the dance2dance network, I tried some other experiments on the data. For example, training a variational autoencoder (VAE) to “compress” each frame of data.

In theory, if it’s possible to compress each frame then it is possible to generate in that compressed space instead of worrying about modeling the original space. When I tried to generate using a 3-layer LSTM trained on the VAE-processed data, the results were incredibly “shaky”. (I assume this is because I did not incorporate any requirement of temporal smoothness, and the VAE learned a very piecemeal latent space capable of reconstructing individual frames instead of learning how to expressively interpolate.)

After training the dance2dance network for a few days, we started to get output that looked similar to some of our input data. The biggest difference across all these experiments is that the hips are fixed in place, making it look sort of like the generated dancer is flailing around on a bicycle seat. The hips are fixed because we were only modeling the rotations and didn’t model the hip position offset.
As the deadline for the performance drew close, we decided to stop the training and work with the model we had. The network was generating a sort of not-quite-human movement that was still somehow reminiscent of the original motion, and it felt appropriate for the feeling we were trying to create in the performance.

During the performance, the real dancer from Elevenplay 丸山未那子 (MARUYAMA Masako, or Maru) starts the scene by exploring the space around the AI dancer, keeping her distance with a mixture of curiosity and suspicion. Eventually, Maru attempts to imitate the dancer. For me, this is one of the most exciting moments as it represents the transformation of human movement passed through a neural network once again embodied by a dancer. The generated motion is then interpolated with the choreography to produce a slowly-evolving duet between Maru and the AI dancer. During this process, the rigged 3D model “comes to life” and changes from a silvery 3D blob to a textured dancer. For me, this represents the way that life emerges when creative expression is shared between people; the way that sharing can complete something otherwise unfinished. As the scene ends, the AI dancer attempts to exit the stage, but Maru backs up in the same direction with palm outstretched towards the AI dancer. The AI dancer transforms back into the silvery blob and it is left writhing alone in its unfinished state, without a real body or any human spirit to complete it.