
Top Data Science Interview Questions & Answers
1.Using Python, write a program/function that prints the least integer that is not present in a given list and cannot be represented by the summation of the sub-elements of the list.
E.g. For a = [1,2,5,7] the least integer not represented by the list or a slice of the list is 4, and if a = [1,2,2,5,7] then the least non-representable integer is 18.
import itertoolstotal_list = []input = [1,2,5,7]for L in range(0, len(input)+1): for subset in itertools.combinations(input, L): total_list.append(sum(subset))new_list = list(set(total_list))new_list.sort()for each in range(0,new_list[-1]+2): if each not in new_list: print(each) break
2. Is more data always better?
The answer to these kind of questions is to think logically at different levels.
At a fundamental level having more data means additional storage, more computational power and memory requirement. Hence, there is a cost related to more data. Doing a cost to benefit analysis of this scenario can help make an informed decision.
At a more specific level, considering the nature of the data, quality is an important metric. If your data is biased, just getting more data is of no use.
From a model perspective, we need to consider what additional data does to the existing model. If a model suffers from a high bias, more data will not be able to improve test results beyond a limit unless more features are added.
3. What is the difference between an inner join, left join/right join, and full join?
For this question lets us take an example of having two database tables:
- Contains the name and unique Ids of all the people who love Pizza.
- Contains the name and unique Ids of all the people who are software developers.
Inner Join- This consists of people who are software developers and love Pizza at the same time.
Left Join- This consists of all the people who love pizza who may/may not be software developers.
Right Join- This consists of all software developers who may/may not love Pizza.
Full Join- This consists of all the people from both tables.
4. Write a query that returns the name of each department and a count of the number of employees in each.
EMPLOYEES containing: Emp_ID (Primary key) and Emp_NameEMPLOYEE_DEPT containing: Emp_ID (Foreign key) and Dept_ID (Foreign key)DEPTS containing: Dept_ID (Primary key) and Dept_Name
Select Dept_Name, count(1)
from DEPTS a right join EMPLOYEE_DEPT b on a.Dept_id = b.Dept_id
Group By Dept_Name
5. What is regularization? Explain L1 and L2 regularization.
Regularization basically adds penalty to a model as complexity increases. Regularization parameter penalizes all the parameters except intercept so that model generalizes the data. This prevents overfitting.
Both L1 and L2 regularization use penalty to avoid overfitting. The major difference between the two is the way penalty is defined. L1 or Lasso and L2 or Ridge regularization will both reduce/remove features from the model when applied.
Lasso Regression adds “absolute value (magnitude)” of coefficient as penalty term to the loss function. Here we use absolute value as highlighted.
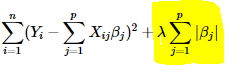
Ridge regression adds “squared value (magnitude)” of coefficient as penalty term to the loss function.
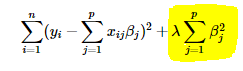
Due to their respective coefficients, L1 regularization is more tolerant of outliers. L1 is better with noisy data and used extensively for the same.
Subscribe to our Acing AI newsletter, I promise not to spam and its FREE!
Thanks for reading! ? If you enjoyed it, test how many times can you hit ? in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.
The sole motivation of this blog article is to provide answers to some Data Science Interview Questions. I aim to make this a living document, so any updates and suggested changes can always be included. Please provide relevant feedback.